SimulTron: On-Device Simultaneous Speech to Speech Translation

0
Sign in to get full access
Overview
- This paper introduces SimulTron, a system for on-device simultaneous speech-to-speech translation.
- SimulTron aims to enable real-time, low-latency translation between languages on mobile devices.
- The system leverages recent advancements in end-to-end simultaneous speech translation and cross-lingual prosody preservation to provide a seamless and expressive translation experience.
- SimulTron is designed to be fast and efficient, enabling high-fidelity mobile translation without sacrificing quality or requiring powerful hardware.
Plain English Explanation
SimulTron is a new system that can translate speech between languages in real-time on your mobile device. This means you can have a conversation with someone who speaks a different language, and SimulTron will instantly translate what they say into your language, and vice versa.
The key innovations in SimulTron are that it can do this translation very quickly, with low delay, and it can also preserve the natural rhythm and tone of the original speech. This makes the translation feel more natural and expressive, like a human interpreter.
SimulTron is designed to work well on mobile devices, even older or less powerful ones. It can provide high-quality translation without needing a lot of computing power or draining your battery quickly. This makes it useful for things like travel, business meetings, or casual conversations where you need to communicate across language barriers.
Technical Explanation
SimulTron builds on recent advancements in end-to-end simultaneous speech translation, which allow for translating speech in real-time with low latency. It also incorporates techniques for preserving the prosody (rhythm and tone) of the original speech during translation, to create a more natural and expressive output.
The system is designed to be efficient and high-fidelity for mobile devices, without compromising on speed or quality. This is achieved through a carefully optimized neural network architecture and inference pipeline.
Key aspects of the SimulTron system include:
- Simultaneous Translation: The system can translate speech in real-time, with low latency, by using incremental processing and prediction techniques.
- Prosody Preservation: SimulTron preserves the natural rhythm, intonation, and emotional expressiveness of the original speech in the translated output.
- Mobile Optimization: The system is designed to run efficiently on mobile devices, enabling robust semantic communication even in challenging conditions.
Critical Analysis
The paper provides a compelling demonstration of SimulTron's capabilities, with experiments showing high translation quality and low latency, even on resource-constrained mobile devices. However, the authors acknowledge that further research is needed to improve performance in noisy environments, handle more language pairs, and explore novel neural network architectures.
One potential limitation is the reliance on pre-trained models and datasets, which may introduce biases or limit the system's ability to adapt to diverse real-world scenarios. The authors could explore techniques for dynamic model adaptation or personalization to address this concern.
Additionally, the paper does not delve deeply into potential ethical considerations, such as privacy implications or the societal impact of widespread real-time translation. Further research in these areas would be valuable to ensure SimulTron is developed and deployed responsibly.
Conclusion
SimulTron represents a significant step forward in the field of on-device simultaneous speech-to-speech translation. By combining state-of-the-art techniques in speech translation, prosody preservation, and mobile optimization, the system offers a compelling solution for enabling seamless cross-language communication on everyday devices.
The authors have demonstrated the system's technical prowess, and the potential for SimulTron to facilitate global connectivity, improve access to information and services, and break down language barriers. As the research continues, addressing the identified limitations and exploring the broader societal implications will be crucial to ensuring SimulTron reaches its full transformative potential.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SimulTron: On-Device Simultaneous Speech to Speech Translation
Alex Agranovich, Eliya Nachmani, Oleg Rybakov, Yifan Ding, Ye Jia, Nadav Bar, Heiga Zen, Michelle Tadmor Ramanovich
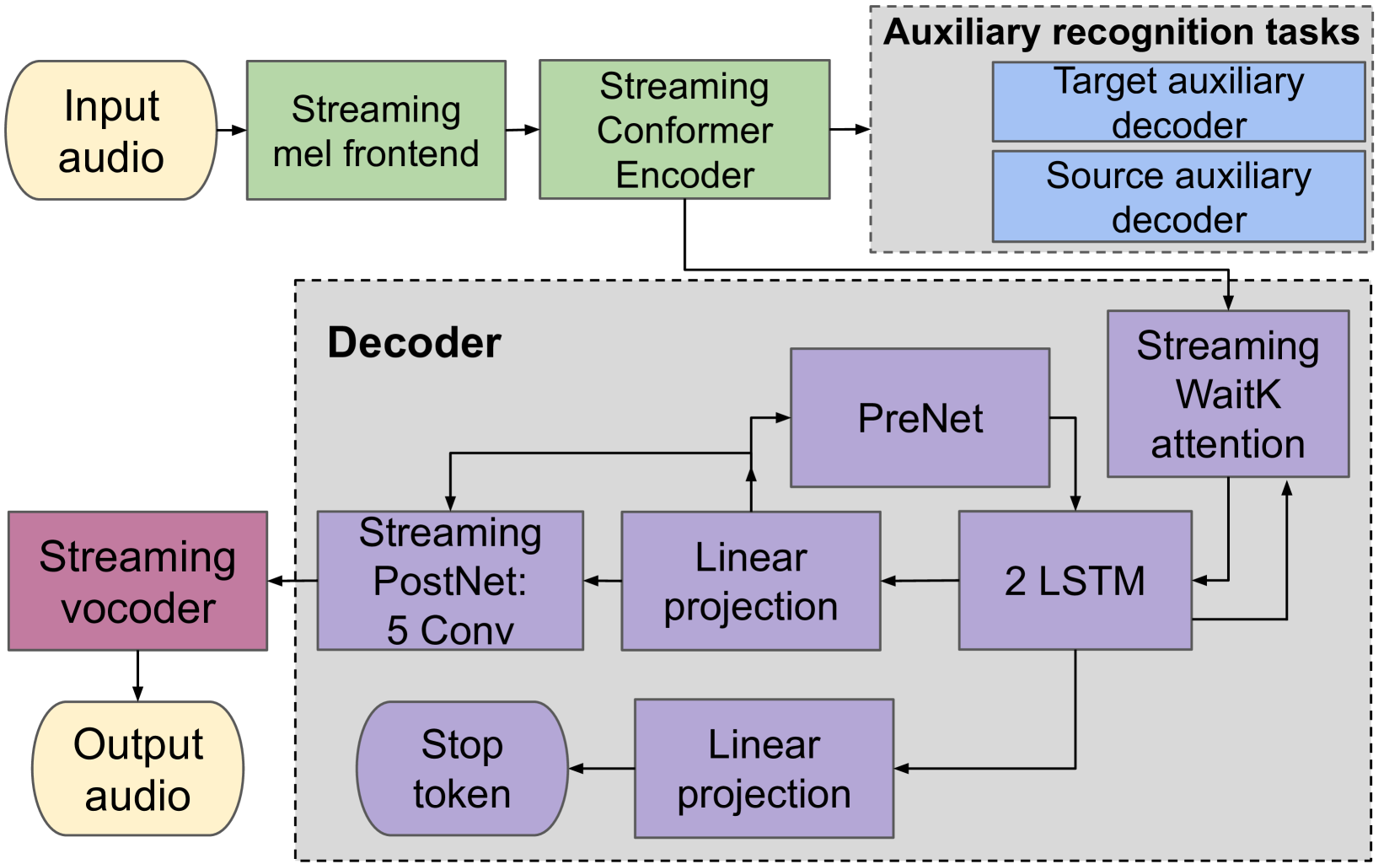
Simultaneous speech-to-speech translation (S2ST) holds the promise of breaking down communication barriers and enabling fluid conversations across languages. However, achieving accurate, real-time translation through mobile devices remains a major challenge. We introduce SimulTron, a novel S2ST architecture designed to tackle this task. SimulTron is a lightweight direct S2ST model that uses the strengths of the Translatotron framework while incorporating key modifications for streaming operation, and an adjustable fixed delay. Our experiments show that SimulTron surpasses Translatotron 2 in offline evaluations. Furthermore, real-time evaluations reveal that SimulTron improves upon the performance achieved by Translatotron 1. Additionally, SimulTron achieves superior BLEU scores and latency compared to previous real-time S2ST method on the MuST-C dataset. Significantly, we have successfully deployed SimulTron on a Pixel 7 Pro device, show its potential for simultaneous S2ST on-device.
Read more6/5/2024

0
StreamSpeech: Simultaneous Speech-to-Speech Translation with Multi-task Learning
Shaolei Zhang, Qingkai Fang, Shoutao Guo, Zhengrui Ma, Min Zhang, Yang Feng
Simultaneous speech-to-speech translation (Simul-S2ST, a.k.a streaming speech translation) outputs target speech while receiving streaming speech inputs, which is critical for real-time communication. Beyond accomplishing translation between speech, Simul-S2ST requires a policy to control the model to generate corresponding target speech at the opportune moment within speech inputs, thereby posing a double challenge of translation and policy. In this paper, we propose StreamSpeech, a direct Simul-S2ST model that jointly learns translation and simultaneous policy in a unified framework of multi-task learning. Adhering to a multi-task learning approach, StreamSpeech can perform offline and simultaneous speech recognition, speech translation and speech synthesis via an All-in-One seamless model. Experiments on CVSS benchmark demonstrate that StreamSpeech achieves state-of-the-art performance in both offline S2ST and Simul-S2ST tasks. Besides, StreamSpeech is able to present high-quality intermediate results (i.e., ASR or translation results) during simultaneous translation process, offering a more comprehensive real-time communication experience.
Read more6/6/2024
🗣️
0
Recent Advances in End-to-End Simultaneous Speech Translation
Xiaoqian Liu, Guoqiang Hu, Yangfan Du, Erfeng He, Yingfeng Luo, Chen Xu, Tong Xiao, Jingbo Zhu
Simultaneous speech translation (SimulST) is a demanding task that involves generating translations in real-time while continuously processing speech input. This paper offers a comprehensive overview of the recent developments in SimulST research, focusing on four major challenges. Firstly, the complexities associated with processing lengthy and continuous speech streams pose significant hurdles. Secondly, satisfying real-time requirements presents inherent difficulties due to the need for immediate translation output. Thirdly, striking a balance between translation quality and latency constraints remains a critical challenge. Finally, the scarcity of annotated data adds another layer of complexity to the task. Through our exploration of these challenges and the proposed solutions, we aim to provide valuable insights into the current landscape of SimulST research and suggest promising directions for future exploration.
Read more8/21/2024

0
CMU's IWSLT 2024 Simultaneous Speech Translation System
Xi Xu, Siqi Ouyang, Brian Yan, Patrick Fernandes, William Chen, Lei Li, Graham Neubig, Shinji Watanabe
This paper describes CMU's submission to the IWSLT 2024 Simultaneous Speech Translation (SST) task for translating English speech to German text in a streaming manner. Our end-to-end speech-to-text (ST) system integrates the WavLM speech encoder, a modality adapter, and the Llama2-7B-Base model as the decoder. We employ a two-stage training approach: initially, we align the representations of speech and text, followed by full fine-tuning. Both stages are trained on MuST-c v2 data with cross-entropy loss. We adapt our offline ST model for SST using a simple fixed hold-n policy. Experiments show that our model obtains an offline BLEU score of 31.1 and a BLEU score of 29.5 under 2 seconds latency on the MuST-C-v2 tst-COMMON.
Read more8/15/2024