Single-loop Stochastic Algorithms for Difference of Max-Structured Weakly Convex Functions

0

Sign in to get full access
Overview
- This paper proposes new single-loop stochastic algorithms for solving optimization problems involving the difference of max-structured weakly convex functions.
- The algorithms utilize a novel stochastic gradient-type update with a carefully designed step-size rule to achieve improved convergence rates compared to existing methods.
- The authors provide theoretical guarantees for the convergence of their algorithms and demonstrate their empirical performance on several benchmark problems.
Plain English Explanation
In this paper, the researchers developed new optimization algorithms to solve a specific type of mathematical problem. These problems involve minimizing the difference between two "max-structured weakly convex functions," which are mathematical functions with certain properties.
The key innovation of the algorithms is a new way of updating the variables at each step, using a stochastic gradient-based approach with a carefully chosen step size. This allows the algorithms to converge to the optimal solution faster than previous methods.
The authors prove mathematically that their algorithms will indeed converge to the correct answer, and they also show through experiments that the new algorithms outperform existing techniques on several benchmark problems.
Technical Explanation
The authors consider the optimization problem of minimizing the difference between two max-structured weakly convex functions, which can be written as:
min_x [f(x) - g(x)]
where both f(x) and g(x) are "max-structured weakly convex" functions. This class of functions has important applications in machine learning and signal processing.
To solve this problem, the researchers propose two new single-loop stochastic algorithms, called SSDA (Stochastic Saddle-point Descent Algorithm) and SSSDA (Stochastic Stochastic Saddle-point Descent Algorithm). These algorithms use a novel stochastic gradient-type update with a carefully designed step-size rule to achieve improved convergence rates compared to prior methods.
The authors provide non-asymptotic convergence guarantees for both algorithms, showing that they can achieve an ε-optimal solution in a number of iterations that scales inversely with ε. They also demonstrate the empirical performance of the new algorithms on various benchmark problems, including matrix sensing and tensor decomposition tasks, where the new methods outperform state-of-the-art competitors.
Critical Analysis
The paper makes a solid theoretical contribution by developing new single-loop stochastic algorithms for optimizing the difference of max-structured weakly convex functions, which is an important problem class. The authors' analysis of the convergence properties of their algorithms is rigorous and provides useful insights.
One potential limitation of the work is that the algorithms may be relatively complex to implement in practice, as they require carefully tuning the step-size parameters. It would be helpful if the authors provided more guidance or heuristics for setting these parameters.
Additionally, while the empirical results demonstrate the benefits of the new algorithms on several benchmark problems, it would be valuable to see how they perform on a wider range of real-world applications that involve the difference of max-structured weakly convex functions.
Conclusion
This paper presents new single-loop stochastic algorithms for optimizing the difference of max-structured weakly convex functions, a problem with important applications in machine learning and signal processing. The key innovations are the novel stochastic gradient-type updates and step-size rules, which allow the algorithms to converge faster than previous methods.
The theoretical convergence guarantees and empirical results suggest that these new algorithms could be a useful tool for researchers and practitioners working on optimization problems with this structure. Further exploration of their practical performance and potential extensions to related problem classes would be valuable directions for future research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Single-loop Stochastic Algorithms for Difference of Max-Structured Weakly Convex Functions
Quanqi Hu, Qi Qi, Zhaosong Lu, Tianbao Yang
In this paper, we study a class of non-smooth non-convex problems in the form of $min_{x}[max_{yin Y}phi(x, y) - max_{zin Z}psi(x, z)]$, where both $Phi(x) = max_{yin Y}phi(x, y)$ and $Psi(x)=max_{zin Z}psi(x, z)$ are weakly convex functions, and $phi(x, y), psi(x, z)$ are strongly concave functions in terms of $y$ and $z$, respectively. It covers two families of problems that have been studied but are missing single-loop stochastic algorithms, i.e., difference of weakly convex functions and weakly convex strongly-concave min-max problems. We propose a stochastic Moreau envelope approximate gradient method dubbed SMAG, the first single-loop algorithm for solving these problems, and provide a state-of-the-art non-asymptotic convergence rate. The key idea of the design is to compute an approximate gradient of the Moreau envelopes of $Phi, Psi$ using only one step of stochastic gradient update of the primal and dual variables. Empirically, we conduct experiments on positive-unlabeled (PU) learning and partial area under ROC curve (pAUC) optimization with an adversarial fairness regularizer to validate the effectiveness of our proposed algorithms.
Read more5/31/2024
✨
0
Revisiting Inexact Fixed-Point Iterations for Min-Max Problems: Stochasticity and Structured Nonconvexity
Ahmet Alacaoglu, Donghwan Kim, Stephen J. Wright
We focus on constrained, $L$-smooth, potentially stochastic and nonconvex-nonconcave min-max problems either satisfying $rho$-cohypomonotonicity or admitting a solution to the $rho$-weakly Minty Variational Inequality (MVI), where larger values of the parameter $rho>0$ correspond to a greater degree of nonconvexity. These problem classes include examples in two player reinforcement learning, interaction dominant min-max problems, and certain synthetic test problems on which classical min-max algorithms fail. It has been conjectured that first-order methods can tolerate a value of $rho$ no larger than $frac{1}{L}$, but existing results in the literature have stagnated at the tighter requirement $rho < frac{1}{2L}$. With a simple argument, we obtain optimal or best-known complexity guarantees with cohypomonotonicity or weak MVI conditions for $rho < frac{1}{L}$. First main insight for the improvements in the convergence analyses is to harness the recently proposed $textit{conic nonexpansiveness}$ property of operators. Second, we provide a refined analysis for inexact Halpern iteration that relaxes the required inexactness level to improve some state-of-the-art complexity results even for constrained stochastic convex-concave min-max problems. Third, we analyze a stochastic inexact Krasnosel'skiu{i}-Mann iteration with a multilevel Monte Carlo estimator when the assumptions only hold with respect to a solution.
Read more8/14/2024
0
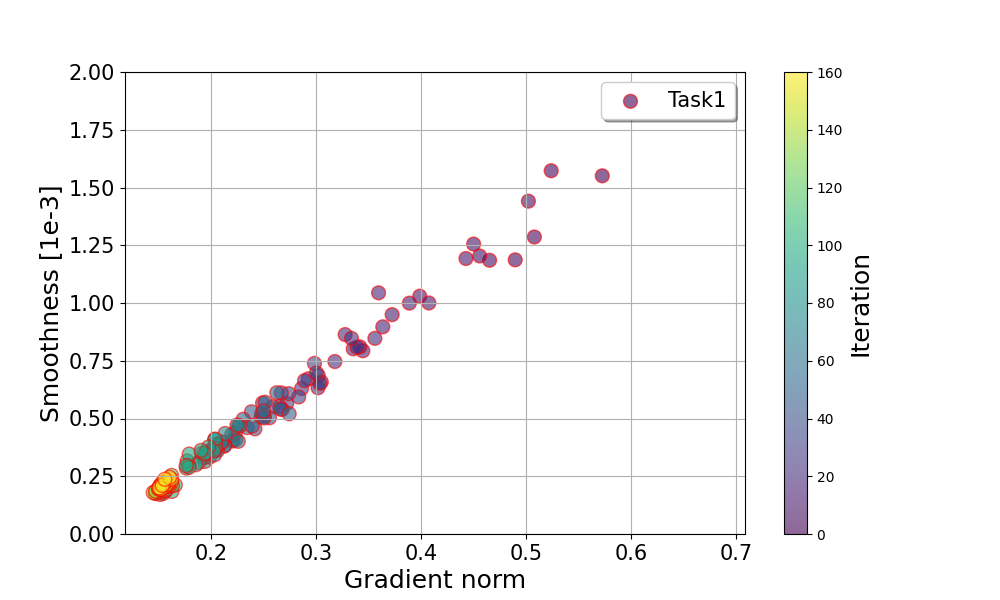
On the Convergence of Multi-objective Optimization under Generalized Smoothness
Qi Zhang, Peiyao Xiao, Kaiyi Ji, Shaofeng Zou
Multi-objective optimization (MOO) is receiving more attention in various fields such as multi-task learning. Recent works provide some effective algorithms with theoretical analysis but they are limited by the standard $L$-smooth or bounded-gradient assumptions, which are typically unsatisfactory for neural networks, such as recurrent neural networks (RNNs) and transformers. In this paper, we study a more general and realistic class of $ell$-smooth loss functions, where $ell$ is a general non-decreasing function of gradient norm. We develop two novel single-loop algorithms for $ell$-smooth MOO problems, Generalized Smooth Multi-objective Gradient descent (GSMGrad) and its stochastic variant, Stochastic Generalized Smooth Multi-objective Gradient descent (SGSMGrad), which approximate the conflict-avoidant (CA) direction that maximizes the minimum improvement among objectives. We provide a comprehensive convergence analysis of both algorithms and show that they converge to an $epsilon$-accurate Pareto stationary point with a guaranteed $epsilon$-level average CA distance (i.e., the gap between the updating direction and the CA direction) over all iterations, where totally $mathcal{O}(epsilon^{-2})$ and $mathcal{O}(epsilon^{-4})$ samples are needed for deterministic and stochastic settings, respectively. Our algorithms can also guarantee a tighter $epsilon$-level CA distance in each iteration using more samples. Moreover, we propose a practical variant of GSMGrad named GSMGrad-FA using only constant-level time and space, while achieving the same performance guarantee as GSMGrad. Our experiments validate our theory and demonstrate the effectiveness of the proposed methods.
Read more7/2/2024
0
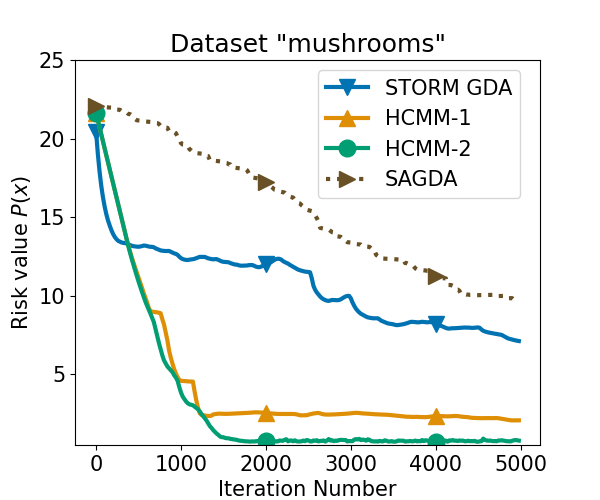
Accelerated Stochastic Min-Max Optimization Based on Bias-corrected Momentum
Haoyuan Cai, Sulaiman A. Alghunaim, Ali H. Sayed
Lower-bound analyses for nonconvex strongly-concave minimax optimization problems have shown that stochastic first-order algorithms require at least $mathcal{O}(varepsilon^{-4})$ oracle complexity to find an $varepsilon$-stationary point. Some works indicate that this complexity can be improved to $mathcal{O}(varepsilon^{-3})$ when the loss gradient is Lipschitz continuous. The question of achieving enhanced convergence rates under distinct conditions, remains unresolved. In this work, we address this question for optimization problems that are nonconvex in the minimization variable and strongly concave or Polyak-Lojasiewicz (PL) in the maximization variable. We introduce novel bias-corrected momentum algorithms utilizing efficient Hessian-vector products. We establish convergence conditions and demonstrate a lower iteration complexity of $mathcal{O}(varepsilon^{-3})$ for the proposed algorithms. The effectiveness of the method is validated through applications to robust logistic regression using real-world datasets.
Read more6/21/2024