SITransformer: Shared Information-Guided Transformer for Extreme Multimodal Summarization

0

Sign in to get full access
Overview
- Multimodal summarization is the task of generating concise summaries from multimedia content.
- This paper introduces SITransformer, a novel transformer-based model that leverages shared information across different modalities to improve multimodal summarization.
- The key contributions include:
- A shared information denoising module that identifies and aggregates relevant information from different modalities.
- A multi-task training strategy that jointly optimizes text summarization and shared information prediction.
- Extensive experiments on challenging multimodal datasets, demonstrating the superiority of SITransformer over existing state-of-the-art methods.
Plain English Explanation
Imagine you have a webpage with text, images, and videos. Multimodal summarization is the process of automatically generating a concise summary that captures the key information from all these different content types. This is a challenging task because each modality (text, images, videos) contains unique information that needs to be effectively combined.
The researchers developed a new model called SITransformer that aims to tackle this problem. The key idea is to first identify the shared information - the crucial details that are present across multiple modalities. By focusing on this shared information, the model can generate summaries that are more comprehensive and accurate.
To do this, SITransformer has a special "denoising" module that analyzes the different content types and extracts the relevant shared information, while filtering out irrelevant or redundant details. The model is then trained to not only generate good text summaries, but also accurately predict the shared information.
Through extensive testing on complex multimodal datasets, the researchers show that SITransformer outperforms existing state-of-the-art methods for multimodal summarization. This suggests that explicitly modeling the shared information across modalities is a powerful approach for this task.
Technical Explanation
The core of SITransformer is a shared information denoising module that identifies and aggregates the relevant information shared across different modalities. This module takes as input the text, images, and other modalities, and outputs a shared information representation that captures the key details common to all the inputs.
To train SITransformer, the researchers used a multi-task learning approach. In addition to optimizing the model for text summarization, they also trained it to accurately predict the shared information representation. This joint optimization encourages the model to focus on extracting the truly important and shared details from the multimodal inputs.
The SITransformer architecture consists of internal links modality-specific encoders, the shared information denoising module, and a cross-modal transformer that generates the final summary. This design allows the model to effectively integrate and leverage the complementary information from the different modalities.
Through extensive experiments on challenging multimodal datasets like MSMO and XMediaSum, the researchers demonstrated that SITransformer outperforms previous state-of-the-art methods for multimodal summarization. This highlights the power of their shared information-guided approach.
Critical Analysis
The paper provides a thoughtful and well-designed solution to the challenging problem of multimodal summarization. The key strength of SITransformer is its ability to effectively identify and leverage the shared information across different modalities, which is crucial for generating comprehensive and accurate summaries.
However, the paper does not extensively discuss the potential limitations or caveats of the proposed approach. For example, it would be interesting to understand how SITransformer performs on more diverse or noisier multimodal datasets, or whether the model's reliance on shared information could potentially lead to biases or blind spots in the generated summaries.
Additionally, while the experiments demonstrate the superiority of SITransformer over existing methods, the paper could benefit from a more in-depth analysis of the model's strengths and weaknesses compared to alternative approaches. This could help readers better understand the trade-offs and applicability of the proposed technique.
Overall, the SITransformer model represents a valuable contribution to the field of multimodal summarization, and the paper provides a solid technical foundation for the research. However, further exploration of the method's limitations and comparison to other state-of-the-art techniques could strengthen the critical analysis and help readers form a more comprehensive understanding of the approach.
Conclusion
The SITransformer paper introduces a novel transformer-based model for multimodal summarization that leverages shared information across different content modalities. By focusing on the crucial details common to text, images, and other inputs, the model is able to generate more comprehensive and accurate summaries than previous state-of-the-art methods.
The key innovations of SITransformer, including the shared information denoising module and the multi-task training strategy, demonstrate the power of explicitly modeling the interplay between different modalities for this task. The strong experimental results on challenging datasets highlight the practical applicability and potential impact of this research.
While the paper could benefit from a more thorough critical analysis, the SITransformer model represents a significant advancement in multimodal summarization and lays the groundwork for further exploration and refinement of shared information-guided approaches in this domain.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SITransformer: Shared Information-Guided Transformer for Extreme Multimodal Summarization
Sicheng Liu, Lintao Wang, Xiaogan Zhu, Xuequan Lu, Zhiyong Wang, Kun Hu
Extreme Multimodal Summarization with Multimodal Output (XMSMO) becomes an attractive summarization approach by integrating various types of information to create extremely concise yet informative summaries for individual modalities. Existing methods overlook the issue that multimodal data often contains more topic irrelevant information, which can mislead the model into producing inaccurate summaries especially for extremely short ones. In this paper, we propose SITransformer, a Shared Information-guided Transformer for extreme multimodal summarization. It has a shared information guided pipeline which involves a cross-modal shared information extractor and a cross-modal interaction module. The extractor formulates semantically shared salient information from different modalities by devising a novel filtering process consisting of a differentiable top-k selector and a shared-information guided gating unit. As a result, the common, salient, and relevant contents across modalities are identified. Next, a transformer with cross-modal attentions is developed for intra- and inter-modality learning with the shared information guidance to produce the extreme summary. Comprehensive experiments demonstrate that SITransformer significantly enhances the summarization quality for both video and text summaries for XMSMO. Our code will be publicly available at https://github.com/SichengLeoLiu/MMAsia24-XMSMO.
Read more8/30/2024

0
Leveraging Entity Information for Cross-Modality Correlation Learning: The Entity-Guided Multimodal Summarization
Yanghai Zhang, Ye Liu, Shiwei Wu, Kai Zhang, Xukai Liu, Qi Liu, Enhong Chen
The rapid increase in multimedia data has spurred advancements in Multimodal Summarization with Multimodal Output (MSMO), which aims to produce a multimodal summary that integrates both text and relevant images. The inherent heterogeneity of content within multimodal inputs and outputs presents a significant challenge to the execution of MSMO. Traditional approaches typically adopt a holistic perspective on coarse image-text data or individual visual objects, overlooking the essential connections between objects and the entities they represent. To integrate the fine-grained entity knowledge, we propose an Entity-Guided Multimodal Summarization model (EGMS). Our model, building on BART, utilizes dual multimodal encoders with shared weights to process text-image and entity-image information concurrently. A gating mechanism then combines visual data for enhanced textual summary generation, while image selection is refined through knowledge distillation from a pre-trained vision-language model. Extensive experiments on public MSMO dataset validate the superiority of the EGMS method, which also prove the necessity to incorporate entity information into MSMO problem.
Read more8/7/2024
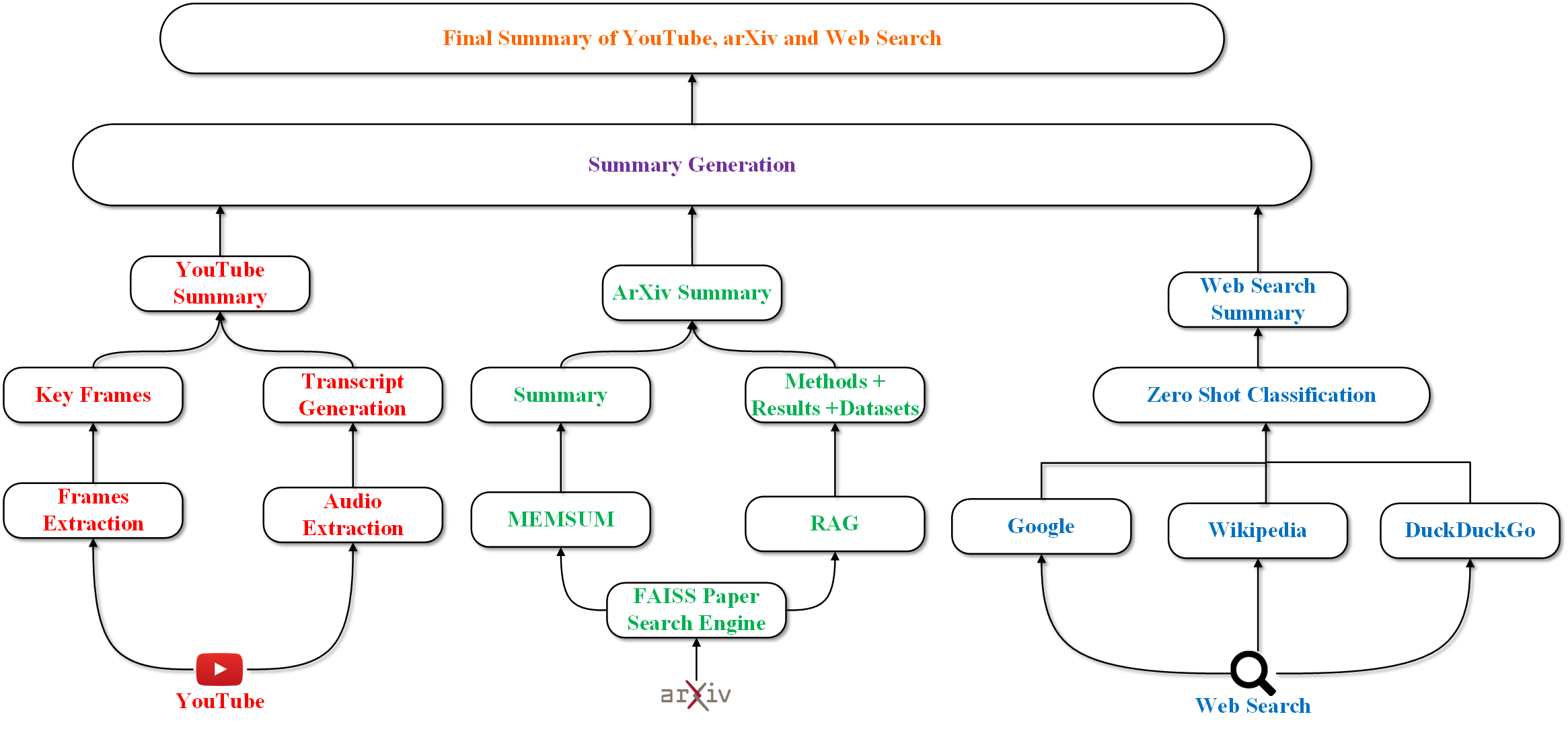
0
Converging Dimensions: Information Extraction and Summarization through Multisource, Multimodal, and Multilingual Fusion
Pranav Janjani, Mayank Palan, Sarvesh Shirude, Ninad Shegokar, Sunny Kumar, Faruk Kazi
Recent advances in large language models (LLMs) have led to new summarization strategies, offering an extensive toolkit for extracting important information. However, these approaches are frequently limited by their reliance on isolated sources of data. The amount of information that can be gathered is limited and covers a smaller range of themes, which introduces the possibility of falsified content and limited support for multilingual and multimodal data. The paper proposes a novel approach to summarization that tackles such challenges by utilizing the strength of multiple sources to deliver a more exhaustive and informative understanding of intricate topics. The research progresses beyond conventional, unimodal sources such as text documents and integrates a more diverse range of data, including YouTube playlists, pre-prints, and Wikipedia pages. The aforementioned varied sources are then converted into a unified textual representation, enabling a more holistic analysis. This multifaceted approach to summary generation empowers us to extract pertinent information from a wider array of sources. The primary tenet of this approach is to maximize information gain while minimizing information overlap and maintaining a high level of informativeness, which encourages the generation of highly coherent summaries.
Read more6/21/2024

0
Multimodal Information Interaction for Medical Image Segmentation
Xinxin Fan, Lin Liu, Haoran Zhang
The use of multimodal data in assisted diagnosis and segmentation has emerged as a prominent area of interest in current research. However, one of the primary challenges is how to effectively fuse multimodal features. Most of the current approaches focus on the integration of multimodal features while ignoring the correlation and consistency between different modal features, leading to the inclusion of potentially irrelevant information. To address this issue, we introduce an innovative Multimodal Information Cross Transformer (MicFormer), which employs a dual-stream architecture to simultaneously extract features from each modality. Leveraging the Cross Transformer, it queries features from one modality and retrieves corresponding responses from another, facilitating effective communication between bimodal features. Additionally, we incorporate a deformable Transformer architecture to expand the search space. We conducted experiments on the MM-WHS dataset, and in the CT-MRI multimodal image segmentation task, we successfully improved the whole-heart segmentation DICE score to 85.57 and MIoU to 75.51. Compared to other multimodal segmentation techniques, our method outperforms by margins of 2.83 and 4.23, respectively. This demonstrates the efficacy of MicFormer in integrating relevant information between different modalities in multimodal tasks. These findings hold significant implications for multimodal image tasks, and we believe that MicFormer possesses extensive potential for broader applications across various domains. Access to our method is available at https://github.com/fxxJuses/MICFormer
Read more4/26/2024