Skill Set Optimization: Reinforcing Language Model Behavior via Transferable Skills

0
💬
Sign in to get full access
Overview
- Large language models (LLMs) are being used for sequential decision-making in interactive environments.
- Leveraging environment reward signals to continuously improve LLM actor performance is challenging.
- The paper proposes a method called Skill Set Optimization (SSO) to improve LLM actor performance through constructing and refining transferable skills.
Plain English Explanation
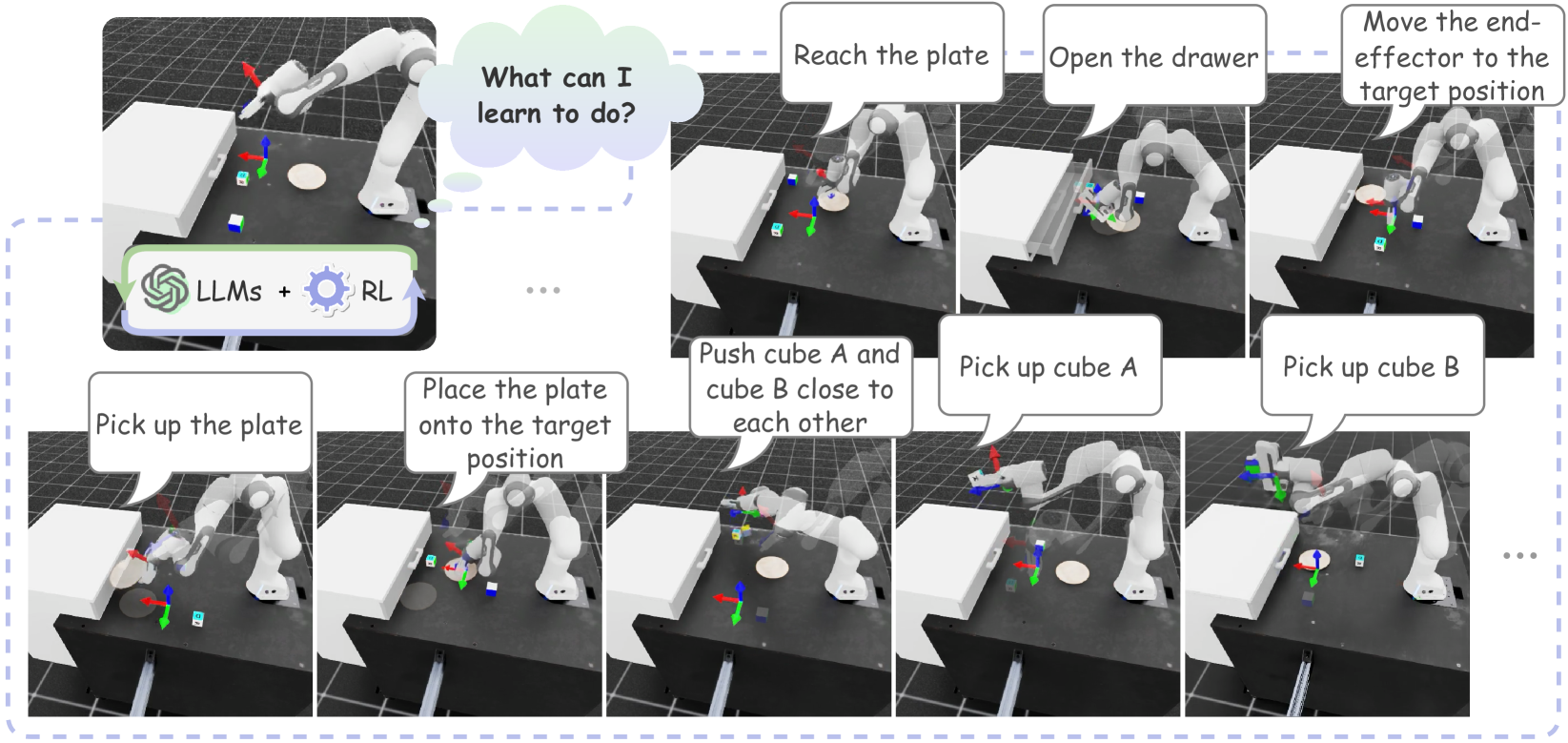
The paper discusses a method called Skill Set Optimization (SSO) for improving the performance of large language models (LLMs) in interactive environments. LLMs have recently been used for sequential decision-making tasks, but it's not straightforward to use the rewards from the environment to continuously improve the LLM's performance.
SSO works by constructing a set of transferable skills that the LLM can use to navigate the environment more effectively. The method identifies common high-reward subtrajectories, and then generates subgoals and instructions to represent each skill. These skills are then provided to the LLM actor in the context of the task, reinforcing the behaviors that lead to high rewards.
The key idea is to break down the task into a set of reusable skills, rather than trying to learn a single, monolithic policy. This allows the LLM to learn a mixture of skills that can be applied in different situations, rather than relying on a one-size-fits-all approach.
The paper also describes how SSO refines the skill set over time, pruning skills that don't continue to result in high rewards. This allows the system to learn and optimize the set of skills over the course of interaction with the environment.
Technical Explanation
The paper proposes a method called Skill Set Optimization (SSO) to improve the performance of large language model (LLM) actors in interactive environments. SSO works by constructing a set of transferable skills that the LLM can use to navigate the environment more effectively.
The key steps of the SSO method are:
- Skill Extraction: SSO identifies common high-reward subtrajectories in the environment and generates subgoals and instructions to represent each skill.
- Skill Provision: The extracted skills are provided to the LLM actor in-context, reinforcing the behaviors that lead to high rewards.
- Skill Refinement: SSO further refines the skill set by pruning skills that do not continue to result in high rewards.
The authors evaluate SSO in two environments: the classic video game NetHack and the text-based environment ScienceWorld. In the custom NetHack task, SSO outperforms baseline methods by 40%. In ScienceWorld, SSO outperforms the previous state-of-the-art by 35%.
Critical Analysis
The paper presents a promising approach for improving LLM performance in interactive environments through the use of transferable skills. However, the authors acknowledge several limitations and areas for further research:
- The skill extraction process relies on identifying common high-reward subtrajectories, which may not be feasible in more complex environments with a large state space.
- The skill refinement process could be improved by considering additional factors beyond just reward signals, such as the diversity and coherence of the skill set.
- The evaluation is limited to relatively constrained environments, and the scalability of SSO to more complex, open-ended tasks remains to be seen.
Additionally, one could question whether the skill-based approach is truly necessary for all types of interactive tasks, or if a more holistic, end-to-end learning approach could be equally effective in some cases.
Conclusion
The Skill Set Optimization (SSO) method proposed in this paper represents a promising approach for improving the performance of large language models in interactive environments. By constructing and refining a set of transferable skills, the method can leverage environment reward signals to continuously enhance the LLM's capabilities.
The demonstrated improvements in the NetHack and ScienceWorld environments suggest that SSO could be a valuable tool for advancing the state-of-the-art in sequential decision-making tasks. However, further research is needed to evaluate the scalability and generalizability of the approach, as well as to explore potential alternatives or complementary techniques.
Overall, this paper contributes a novel and interesting perspective on the challenge of leveraging environment rewards for LLM improvement, and the authors' work on Skill Set Optimization is a significant step forward in this important area of research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
Skill Set Optimization: Reinforcing Language Model Behavior via Transferable Skills
Kolby Nottingham, Bodhisattwa Prasad Majumder, Bhavana Dalvi Mishra, Sameer Singh, Peter Clark, Roy Fox
Large language models (LLMs) have recently been used for sequential decision making in interactive environments. However, leveraging environment reward signals for continual LLM actor improvement is not straightforward. We propose Skill Set Optimization (SSO) for improving LLM actor performance through constructing and refining sets of transferable skills. SSO constructs skills by extracting common subtrajectories with high rewards and generating subgoals and instructions to represent each skill. These skills are provided to the LLM actor in-context to reinforce behaviors with high rewards. Then, SSO further refines the skill set by pruning skills that do not continue to result in high rewards. We evaluate our method in the classic videogame NetHack and the text environment ScienceWorld to demonstrate SSO's ability to optimize a set of skills and perform in-context policy improvement. SSO outperforms baselines by 40% in our custom NetHack task and outperforms the previous state-of-the-art in ScienceWorld by 35%.
Read more6/26/2024
0
Agentic Skill Discovery
Xufeng Zhao, Cornelius Weber, Stefan Wermter
Language-conditioned robotic skills make it possible to apply the high-level reasoning of Large Language Models (LLMs) to low-level robotic control. A remaining challenge is to acquire a diverse set of fundamental skills. Existing approaches either manually decompose a complex task into atomic robotic actions in a top-down fashion, or bootstrap as many combinations as possible in a bottom-up fashion to cover a wider range of task possibilities. These decompositions or combinations, however, require an initial skill library. For example, a ``grasping'' capability can never emerge from a skill library containing only diverse ``pushing'' skills. Existing skill discovery techniques with reinforcement learning acquire skills by an exhaustive exploration but often yield non-meaningful behaviors. In this study, we introduce a novel framework for skill discovery that is entirely driven by LLMs. The framework begins with an LLM generating task proposals based on the provided scene description and the robot's configurations, aiming to incrementally acquire new skills upon task completion. For each proposed task, a series of reinforcement learning processes are initiated, utilizing reward and success determination functions sampled by the LLM to develop the corresponding policy. The reliability and trustworthiness of learned behaviors are further ensured by an independent vision-language model. We show that starting with zero skill, the skill library emerges and expands to more and more meaningful and reliable skills, enabling the robot to efficiently further propose and complete advanced tasks. Project page: url{https://agentic-skill-discovery.github.io}.
Read more8/19/2024

0
TaSL: Task Skill Localization and Consolidation for Language Model Continual Learning
Yujie Feng, Xu Chu, Yongxin Xu, Zexin Lu, Bo Liu, Philip S. Yu, Xiao-Ming Wu
Language model continual learning (CL) has recently attracted significant interest for its ability to adapt large language models (LLMs) to dynamic real-world scenarios without retraining. A major challenge in this domain is catastrophic forgetting, where models lose previously acquired knowledge upon learning new tasks. Existing approaches commonly utilize multiple parameter-efficient fine-tuning (PEFT) blocks to acquire task-specific knowledge, yet these methods are inefficient and fail to leverage potential knowledge transfer across tasks. In this paper, we introduce a novel CL framework for language models, named Task Skill Localization and Consolidation (TaSL), which boosts knowledge transfer without depending on memory replay. TaSL initially segregates the model into 'skill units' based on parameter dependencies, allowing for more precise control. Subsequently, it employs a novel group-wise skill localization technique to ascertain the importance distribution of skill units for a new task. By comparing this importance distribution with those from previous tasks, we implement a fine-grained skill consolidation strategy that retains task-specific knowledge, thereby preventing forgetting, and updates task-shared knowledge, which facilitates bi-directional knowledge transfer. As a result, TaSL achieves an optimal balance between retaining prior knowledge and excelling in new tasks. TaSL also demonstrates strong generalizability, making it suitable for various base models and adaptable to PEFT methods like LoRA. Furthermore, it offers notable extensibility, supporting enhancements through integration with memory replay techniques. Comprehensive experiments conducted on two CL benchmarks, involving models ranging from 220M to 7B parameters, affirm the effectiveness of TaSL and its variants across different settings.
Read more9/2/2024
📊
0
Mixture-of-Skills: Learning to Optimize Data Usage for Fine-Tuning Large Language Models
Minghao Wu, Thuy-Trang Vu, Lizhen Qu, Gholamreza Haffari
Large language models (LLMs) are typically fine-tuned on diverse and extensive datasets sourced from various origins to develop a comprehensive range of skills, such as writing, reasoning, chatting, coding, and more. Each skill has unique characteristics, and these datasets are often heterogeneous and imbalanced, making the fine-tuning process highly challenging. Balancing the development of each skill while ensuring the model maintains its overall performance requires sophisticated techniques and careful dataset curation. In this work, we propose a general, model-agnostic, reinforcement learning framework, Mixture-of-Skills (MoS), that learns to optimize data usage automatically during the fine-tuning process. This framework ensures the optimal comprehensive skill development of LLMs by dynamically adjusting the focus on different datasets based on their current learning state. To validate the effectiveness of MoS, we conduct extensive experiments using three diverse LLM backbones on two widely used benchmarks and demonstrate that MoS substantially enhances model performance. Building on the success of MoS, we propose MoSpec, an adaptation for task-specific fine-tuning, which harnesses the utilities of various datasets for a specific purpose. Our work underlines the significance of dataset rebalancing and present MoS as a powerful, general solution for optimizing data usage in the fine-tuning of LLMs for various purposes.
Read more6/14/2024