Language-guided Skill Learning with Temporal Variational Inference
2402.16354
0
0
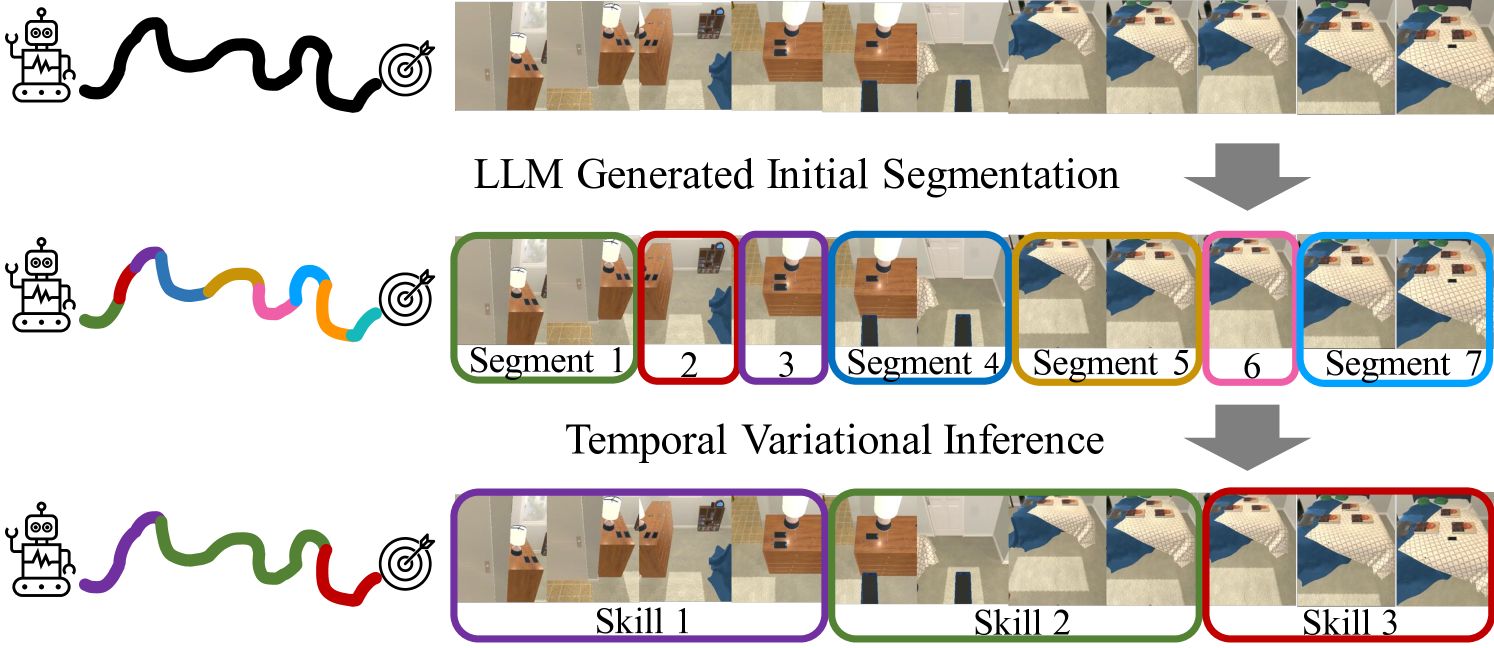
Abstract
We present an algorithm for skill discovery from expert demonstrations. The algorithm first utilizes Large Language Models (LLMs) to propose an initial segmentation of the trajectories. Following that, a hierarchical variational inference framework incorporates the LLM-generated segmentation information to discover reusable skills by merging trajectory segments. To further control the trade-off between compression and reusability, we introduce a novel auxiliary objective based on the Minimum Description Length principle that helps guide this skill discovery process. Our results demonstrate that agents equipped with our method are able to discover skills that help accelerate learning and outperform baseline skill learning approaches on new long-horizon tasks in BabyAI, a grid world navigation environment, as well as ALFRED, a household simulation environment.
Create account to get full access
Overview
- This paper presents a novel approach to language-guided skill learning using temporal variational inference.
- The method allows an agent to learn new skills by interpreting natural language instructions and generating corresponding action sequences.
- The authors demonstrate the effectiveness of their approach on various simulated robotic manipulation tasks.
Plain English Explanation
The paper describes a way for computer systems to learn new skills by following instructions written in natural language. The key idea is to use a technique called "temporal variational inference" to interpret the language and generate the appropriate sequence of actions.
Imagine you want to teach a robot how to make a cup of coffee. Typically, you'd have to program the robot with a specific set of instructions. But with this new approach, you could simply describe the steps in plain English, and the robot would be able to understand the language and figure out how to perform the task.
This is valuable because it allows the robot to learn a much wider range of skills without the need for extensive reprogramming. The system can take in natural language descriptions and translate them into the corresponding actions. This makes the robot more flexible and adaptable, allowing it to handle a broader range of tasks.
The researchers demonstrate this capability by testing their approach on simulated robotic manipulation tasks, such as stacking blocks or arranging objects. The results show that the robot is able to successfully interpret the language instructions and carry out the requested actions.
Technical Explanation
The core of the paper is a model that uses temporal variational inference to learn skills from language instructions. The model consists of an encoder that takes in the language input and generates a latent representation, and a decoder that uses this representation to predict the sequence of actions required to accomplish the task.
The key innovation is the use of a temporal variational inference framework, which allows the model to capture the dynamics of the task and generate the appropriate action sequence over time. This is in contrast to more traditional approaches that treat the task as a static mapping from language to actions.
The authors evaluate their approach on a range of simulated robotic manipulation tasks, such as those involving object stacking and arrangement. The results show that their model outperforms baseline methods, demonstrating the effectiveness of the temporal variational inference approach for learning semantic languages and translating them into corresponding actions.
Critical Analysis
The paper presents a compelling approach to language-guided skill learning, but it is important to consider some potential limitations and areas for further research.
One concern is the reliance on simulated environments for the experiments. While this allows for controlled testing, it remains to be seen how well the approach would scale to real-world robotic systems with all their complexities and uncertainties.
Additionally, the paper focuses on relatively simple manipulation tasks. It would be interesting to see how the model performs on more complex, hierarchical tasks that require the robot to reason about higher-level goals and plan sequences of actions accordingly.
Another area for exploration is the integration of the language-guided skill learning with reward learning techniques. This could allow the robot to not only understand the language instructions, but also learn the appropriate reward function to optimize for the desired behavior.
Overall, this paper represents an exciting step forward in the field of language-guided skill learning, and the authors have demonstrated a promising approach using temporal variational inference. Further research to address the limitations and expand the capabilities of the system could lead to significant advancements in the development of more flexible and adaptable robotic systems.
Conclusion
The paper presents a novel approach to language-guided skill learning that leverages temporal variational inference. This technique allows robots to interpret natural language instructions and generate the corresponding sequences of actions, enabling them to learn a wider range of skills without the need for extensive reprogramming.
The authors demonstrate the effectiveness of their approach through experiments on simulated robotic manipulation tasks, showcasing the robot's ability to understand language and translate it into appropriate actions. While the paper highlights the potential of this approach, further research is needed to address its limitations and expand its capabilities, particularly in terms of real-world applicability and the integration of reward learning techniques.
Overall, this work represents an important step forward in the development of more flexible and adaptable robotic systems that can learn from natural language instructions, with broader implications for the field of human-robot interaction and the advancement of artificial intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
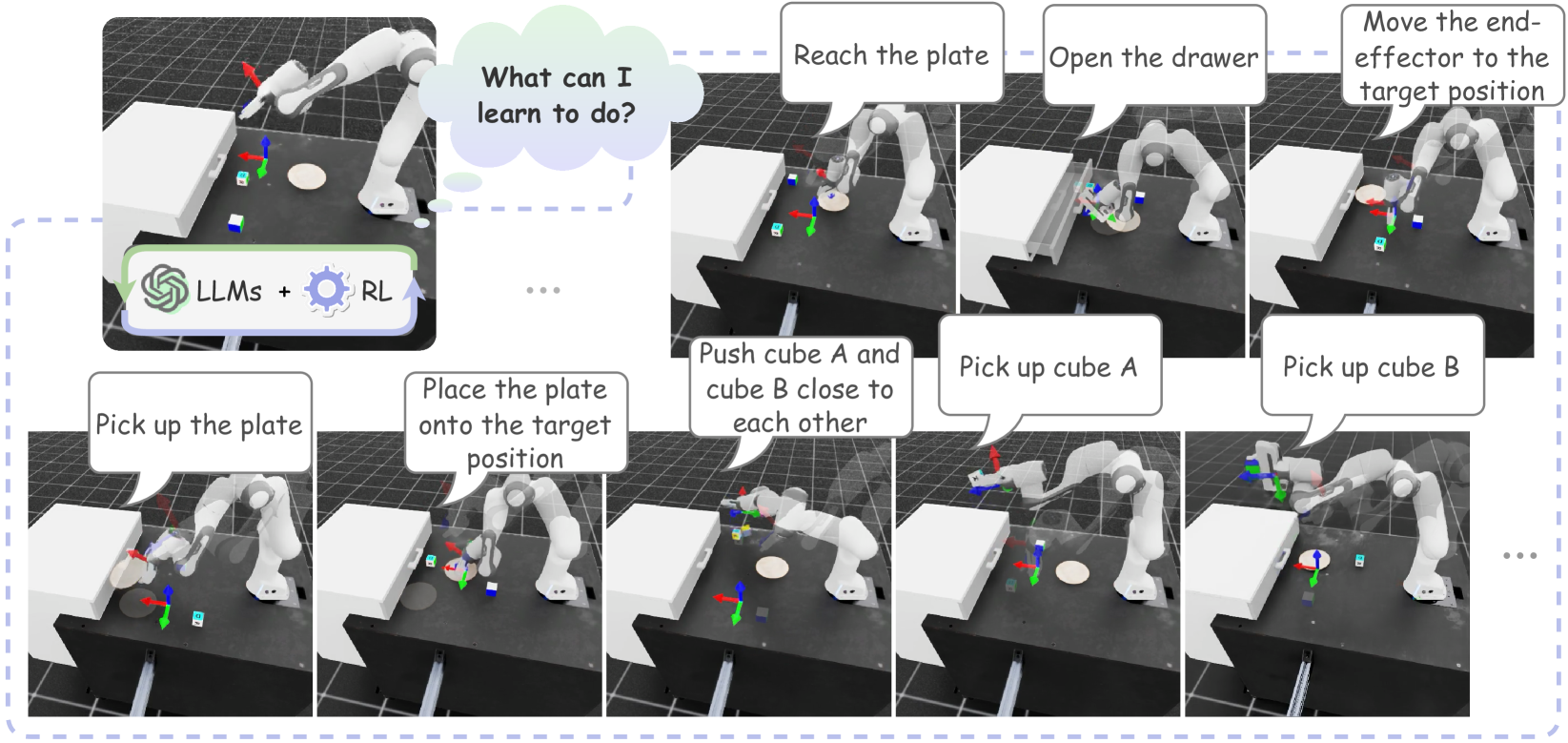
Agentic Skill Discovery
Xufeng Zhao, Cornelius Weber, Stefan Wermter
0
0
Language-conditioned robotic skills make it possible to apply the high-level reasoning of Large Language Models (LLMs) to low-level robotic control. A remaining challenge is to acquire a diverse set of fundamental skills. Existing approaches either manually decompose a complex task into atomic robotic actions in a top-down fashion, or bootstrap as many combinations as possible in a bottom-up fashion to cover a wider range of task possibilities. These decompositions or combinations, however, require an initial skill library. For example, a grasping capability can never emerge from a skill library containing only diverse pushing skills. Existing skill discovery techniques with reinforcement learning acquire skills by an exhaustive exploration but often yield non-meaningful behaviors. In this study, we introduce a novel framework for skill discovery that is entirely driven by LLMs. The framework begins with an LLM generating task proposals based on the provided scene description and the robot's configurations, aiming to incrementally acquire new skills upon task completion. For each proposed task, a series of reinforcement learning processes are initiated, utilizing reward and success determination functions sampled by the LLM to develop the corresponding policy. The reliability and trustworthiness of learned behaviors are further ensured by an independent vision-language model. We show that starting with zero skill, the ASD skill library emerges and expands to more and more meaningful and reliable skills, enabling the robot to efficiently further propose and complete advanced tasks. The project page can be found at: https://agentic-skill-discovery.github.io.
5/27/2024
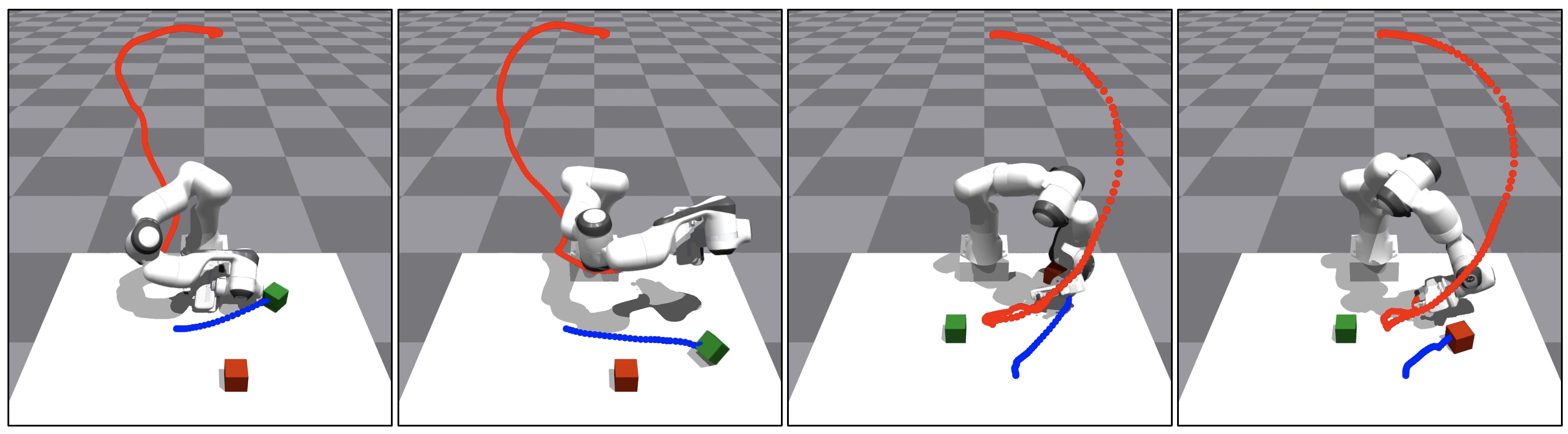
Language Guided Skill Discovery
Seungeun Rho, Laura Smith, Tianyu Li, Sergey Levine, Xue Bin Peng, Sehoon Ha
0
0
Skill discovery methods enable agents to learn diverse emergent behaviors without explicit rewards. To make learned skills useful for unknown downstream tasks, obtaining a semantically diverse repertoire of skills is essential. While some approaches introduce a discriminator to distinguish skills and others aim to increase state coverage, no existing work directly addresses the semantic diversity of skills. We hypothesize that leveraging the semantic knowledge of large language models (LLMs) can lead us to improve semantic diversity of resulting behaviors. In this sense, we introduce Language Guided Skill Discovery (LGSD), a skill discovery framework that aims to directly maximize the semantic diversity between skills. LGSD takes user prompts as input and outputs a set of semantically distinctive skills. The prompts serve as a means to constrain the search space into a semantically desired subspace, and the generated LLM outputs guide the agent to visit semantically diverse states within the subspace. We demonstrate that LGSD enables legged robots to visit different user-intended areas on a plane by simply changing the prompt. Furthermore, we show that language guidance aids in discovering more diverse skills compared to five existing skill discovery methods in robot-arm manipulation environments. Lastly, LGSD provides a simple way of utilizing learned skills via natural language.
6/12/2024
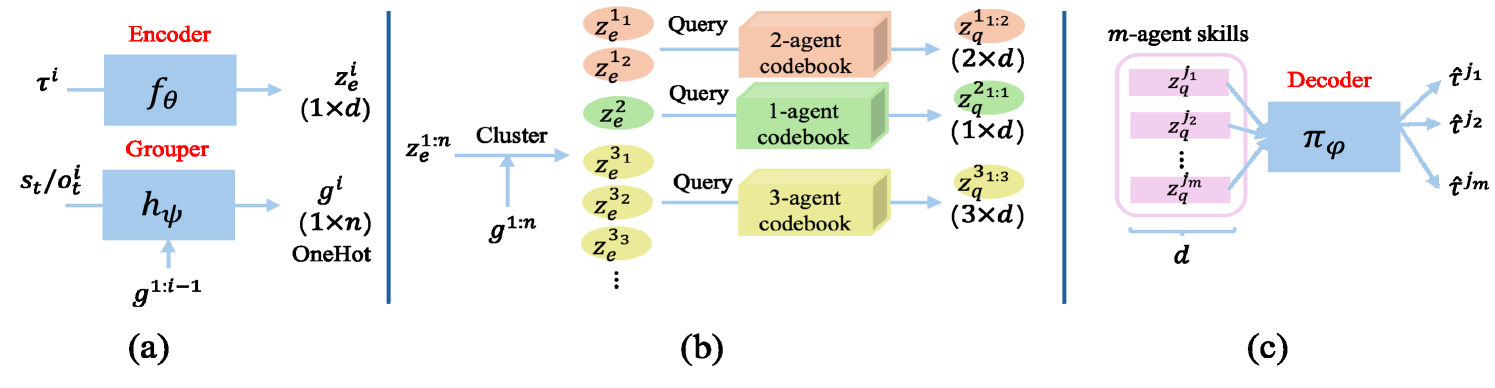
Variational Offline Multi-agent Skill Discovery
Jiayu Chen, Bhargav Ganguly, Tian Lan, Vaneet Aggarwal
0
0
Skills are effective temporal abstractions established for sequential decision making tasks, which enable efficient hierarchical learning for long-horizon tasks and facilitate multi-task learning through their transferability. Despite extensive research, research gaps remain in multi-agent scenarios, particularly for automatically extracting subgroup coordination patterns in a multi-agent task. In this case, we propose two novel auto-encoder schemes: VO-MASD-3D and VO-MASD-Hier, to simultaneously capture subgroup- and temporal-level abstractions and form multi-agent skills, which firstly solves the aforementioned challenge. An essential algorithm component of these schemes is a dynamic grouping function that can automatically detect latent subgroups based on agent interactions in a task. Notably, our method can be applied to offline multi-task data, and the discovered subgroup skills can be transferred across relevant tasks without retraining. Empirical evaluations on StarCraft tasks indicate that our approach significantly outperforms existing methods regarding applying skills in multi-agent reinforcement learning (MARL). Moreover, skills discovered using our method can effectively reduce the learning difficulty in MARL scenarios with delayed and sparse reward signals.
5/28/2024

ICAL: Continual Learning of Multimodal Agents by Transforming Trajectories into Actionable Insights
Gabriel Sarch, Lawrence Jang, Michael J. Tarr, William W. Cohen, Kenneth Marino, Katerina Fragkiadaki
0
0
Large-scale generative language and vision-language models (LLMs and VLMs) excel in few-shot in-context learning for decision making and instruction following. However, they require high-quality exemplar demonstrations to be included in their context window. In this work, we ask: Can LLMs and VLMs generate their own prompt examples from generic, sub-optimal demonstrations? We propose In-Context Abstraction Learning (ICAL), a method that builds a memory of multimodal experience insights from sub-optimal demonstrations and human feedback. Given a noisy demonstration in a new domain, VLMs abstract the trajectory into a general program by fixing inefficient actions and annotating cognitive abstractions: task relationships, object state changes, temporal subgoals, and task construals. These abstractions are refined and adapted interactively through human feedback while the agent attempts to execute the trajectory in a similar environment. The resulting abstractions, when used as exemplars in the prompt, significantly improve decision-making in retrieval-augmented LLM and VLM agents. Our ICAL agent surpasses the state-of-the-art in dialogue-based instruction following in TEACh, multimodal web agents in VisualWebArena, and action anticipation in Ego4D. In TEACh, we achieve a 12.6% improvement in goal-condition success. In VisualWebArena, our task success rate improves over the SOTA from 14.3% to 22.7%. In Ego4D action forecasting, we improve over few-shot GPT-4V and remain competitive with supervised models. We show finetuning our retrieval-augmented in-context agent yields additional improvements. Our approach significantly reduces reliance on expert-crafted examples and consistently outperforms in-context learning from action plans that lack such insights.
6/24/2024