Skills Regularized Task Decomposition for Multi-task Offline Reinforcement Learning

0

Sign in to get full access
Overview
- The paper presents a novel method for multi-task offline reinforcement learning (RL) called Skills Regularized Task Decomposition (SRTD).
- SRTD learns a set of reusable skills that can be efficiently combined to solve multiple tasks, improving sample efficiency.
- The method uses a skill regularizer to encourage the emergence of general, transferable skills during training.
Plain English Explanation
The researchers developed a new approach called Skills Regularized Task Decomposition (SRTD) for tackling multiple tasks in an offline reinforcement learning setting. In this type of learning, the agent has access to a fixed dataset of experiences and must learn to solve various tasks from that data, without being able to interact with the environment.
The key insight of SRTD is that it's more efficient to learn a set of reusable "skills" that can be combined in different ways to solve different tasks, rather than learning a separate policy for each task from scratch. The method encourages the agent to discover skills that are general and transferable across tasks, by adding a skill regularizer to the training objective.
This skill regularizer incentivizes the agent to learn skills that are versatile and can be applied in multiple contexts, rather than skills that are narrowly tailored to a single task. By decomposing the learning problem in this way, SRTD is able to achieve stronger performance on the target tasks compared to training separate policies for each one independently.
Technical Explanation
The core of the SRTD approach is a skill-based hierarchical policy that consists of a skill selector and a skill executor. The skill selector decides which skill to apply in a given state, while the skill executor performs the chosen skill.
During training, the method learns the skill selector, skill executor, and a task-specific combiner that combines the skills to solve each task. Crucially, the training objective includes a skill regularizer that encourages the emergence of general, transferable skills.
This skill regularizer works by measuring the diversity of the learned skills - it favors skills that are used across multiple tasks, rather than skills that are narrowly specialized. By incorporating this regularizer, the method is able to discover a set of versatile skills that can be efficiently composed to solve the target tasks.
The researchers evaluate SRTD on a suite of challenging multi-task RL benchmarks, including robotic manipulation and locomotion tasks. The results show that SRTD outperforms alternative multi-task RL methods, demonstrating the benefits of the skill-based decomposition and the skill regularizer.
Critical Analysis
The paper provides a thorough theoretical and empirical analysis of the SRTD approach. The skill regularizer is a clever innovation that effectively encourages the emergence of transferable skills, which is a key challenge in multi-task RL.
However, the paper does not extensively discuss the computational complexity of the method, which could be a practical concern, especially as the number of tasks grows. Additionally, the authors acknowledge that the skill-based hierarchical structure may not be suitable for all types of tasks, and further research is needed to understand the limitations of this approach.
Another potential limitation is that the skill regularizer relies on the assumption that more diverse skills are better, but this may not always be the case. In some domains, highly specialized skills could be more efficient than general-purpose ones.
Conclusion
The Skills Regularized Task Decomposition (SRTD) method presented in this paper is a significant contribution to the field of multi-task offline reinforcement learning. By learning a set of reusable skills and encouraging their versatility, SRTD is able to achieve strong performance on a variety of challenging tasks, while being more sample-efficient than alternative approaches.
This work highlights the potential of hierarchical, skill-based policies for tackling complex multi-task problems, and the importance of introducing the right kind of inductive biases, such as the skill regularizer, to guide the learning process. As the field of reinforcement learning continues to advance, techniques like SRTD will likely play an important role in developing agents that can efficiently learn and generalize across a wide range of tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Skills Regularized Task Decomposition for Multi-task Offline Reinforcement Learning
Minjong Yoo, Sangwoo Cho, Honguk Woo
Reinforcement learning (RL) with diverse offline datasets can have the advantage of leveraging the relation of multiple tasks and the common skills learned across those tasks, hence allowing us to deal with real-world complex problems efficiently in a data-driven way. In offline RL where only offline data is used and online interaction with the environment is restricted, it is yet difficult to achieve the optimal policy for multiple tasks, especially when the data quality varies for the tasks. In this paper, we present a skill-based multi-task RL technique on heterogeneous datasets that are generated by behavior policies of different quality. To learn the shareable knowledge across those datasets effectively, we employ a task decomposition method for which common skills are jointly learned and used as guidance to reformulate a task in shared and achievable subtasks. In this joint learning, we use Wasserstein auto-encoder (WAE) to represent both skills and tasks on the same latent space and use the quality-weighted loss as a regularization term to induce tasks to be decomposed into subtasks that are more consistent with high-quality skills than others. To improve the performance of offline RL agents learned on the latent space, we also augment datasets with imaginary trajectories relevant to high-quality skills for each task. Through experiments, we show that our multi-task offline RL approach is robust to the mixed configurations of different-quality datasets and it outperforms other state-of-the-art algorithms for several robotic manipulation tasks and drone navigation tasks.
Read more8/29/2024
🏅
0
Model-Based Reinforcement Learning with Multi-Task Offline Pretraining
Minting Pan, Yitao Zheng, Yunbo Wang, Xiaokang Yang
Pretraining reinforcement learning (RL) models on offline datasets is a promising way to improve their training efficiency in online tasks, but challenging due to the inherent mismatch in dynamics and behaviors across various tasks. We present a model-based RL method that learns to transfer potentially useful dynamics and action demonstrations from offline data to a novel task. The main idea is to use the world models not only as simulators for behavior learning but also as tools to measure the task relevance for both dynamics representation transfer and policy transfer. We build a time-varying, domain-selective distillation loss to generate a set of offline-to-online similarity weights. These weights serve two purposes: (i) adaptively transferring the task-agnostic knowledge of physical dynamics to facilitate world model training, and (ii) learning to replay relevant source actions to guide the target policy. We demonstrate the advantages of our approach compared with the state-of-the-art methods in Meta-World and DeepMind Control Suite.
Read more6/6/2024
🏅
0
Robotic Manipulation Datasets for Offline Compositional Reinforcement Learning
Marcel Hussing, Jorge A. Mendez, Anisha Singrodia, Cassandra Kent, Eric Eaton
Offline reinforcement learning (RL) is a promising direction that allows RL agents to pre-train on large datasets, avoiding the recurrence of expensive data collection. To advance the field, it is crucial to generate large-scale datasets. Compositional RL is particularly appealing for generating such large datasets, since 1)~it permits creating many tasks from few components, 2)~the task structure may enable trained agents to solve new tasks by combining relevant learned components, and 3)~the compositional dimensions provide a notion of task relatedness. This paper provides four offline RL datasets for simulated robotic manipulation created using the $256$ tasks from CompoSuite [Mendez at al., 2022a]. Each dataset is collected from an agent with a different degree of performance, and consists of $256$ million transitions. We provide training and evaluation settings for assessing an agent's ability to learn compositional task policies. Our benchmarking experiments show that current offline RL methods can learn the training tasks to some extent and that compositional methods outperform non-compositional methods. Yet current methods are unable to extract the compositional structure to generalize to unseen tasks, highlighting a need for future research in offline compositional RL.
Read more7/16/2024
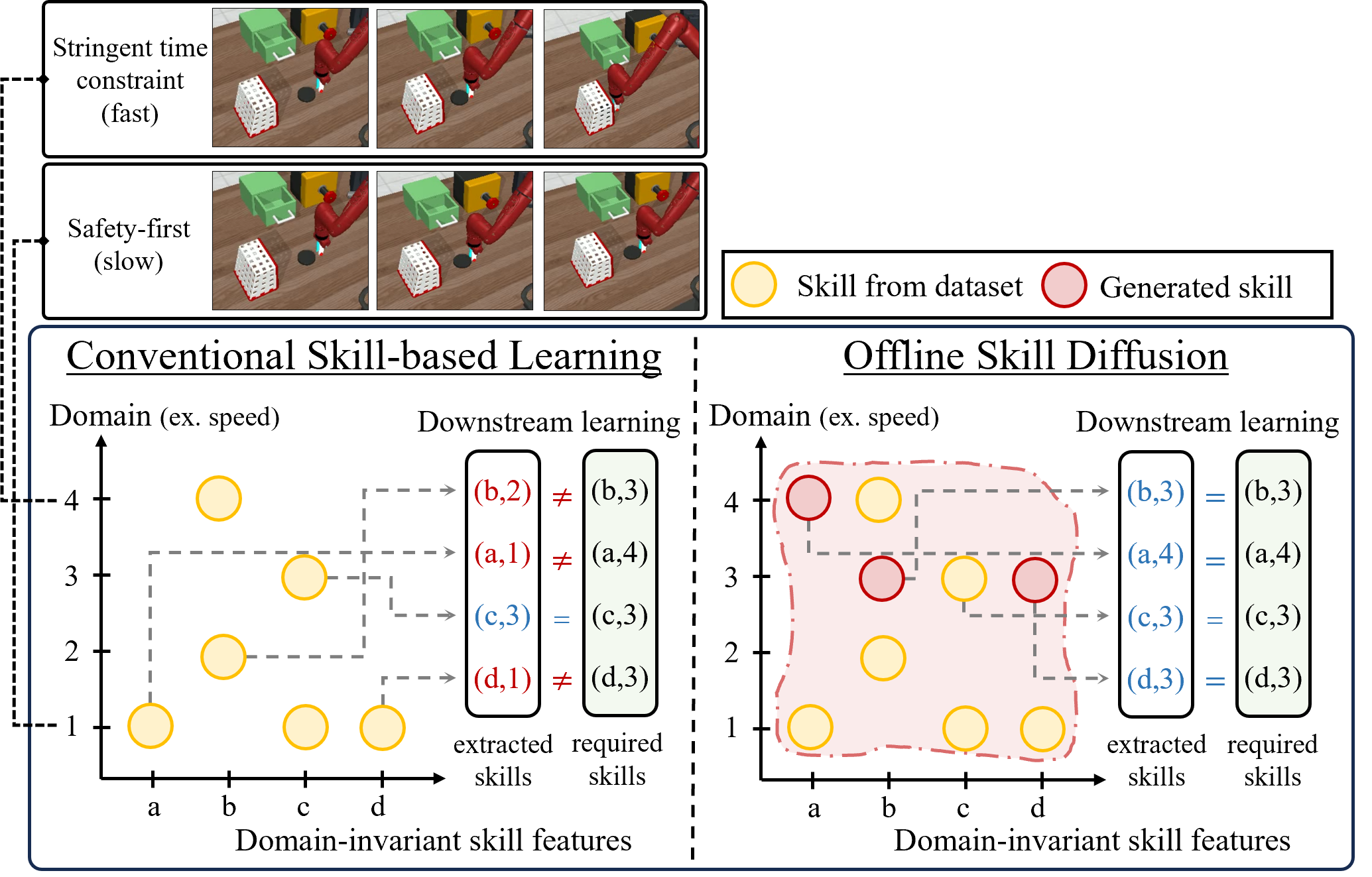
0
Robust Policy Learning via Offline Skill Diffusion
Woo Kyung Kim, Minjong Yoo, Honguk Woo
Skill-based reinforcement learning (RL) approaches have shown considerable promise, especially in solving long-horizon tasks via hierarchical structures. These skills, learned task-agnostically from offline datasets, can accelerate the policy learning process for new tasks. Yet, the application of these skills in different domains remains restricted due to their inherent dependency on the datasets, which poses a challenge when attempting to learn a skill-based policy via RL for a target domain different from the datasets' domains. In this paper, we present a novel offline skill learning framework DuSkill which employs a guided Diffusion model to generate versatile skills extended from the limited skills in datasets, thereby enhancing the robustness of policy learning for tasks in different domains. Specifically, we devise a guided diffusion-based skill decoder in conjunction with the hierarchical encoding to disentangle the skill embedding space into two distinct representations, one for encapsulating domain-invariant behaviors and the other for delineating the factors that induce domain variations in the behaviors. Our DuSkill framework enhances the diversity of skills learned offline, thus enabling to accelerate the learning procedure of high-level policies for different domains. Through experiments, we show that DuSkill outperforms other skill-based imitation learning and RL algorithms for several long-horizon tasks, demonstrating its benefits in few-shot imitation and online RL.
Read more8/23/2024