Robust Policy Learning via Offline Skill Diffusion

0
Sign in to get full access
Overview
- The paper proposes a novel offline reinforcement learning method called Robust Policy Learning via Offline Skill Diffusion (RPLOD) to learn robust policies from offline demonstration data.
- The key idea is to learn diverse skills from offline data and then diffuse these skills to learn a robust policy that can handle a variety of situations.
- RPLOD outperforms state-of-the-art offline RL methods on challenging benchmark tasks.
Plain English Explanation
Reinforcement learning (RL) is a powerful technique for training agents to perform complex tasks. However, traditional RL methods require a lot of interactive data, which can be costly or dangerous to collect in real-world settings.
To address this, the researchers developed a new offline RL method called Robust Policy Learning via Offline Skill Diffusion (RPLOD). The key idea behind RPLOD is to first learn a diverse set of skills from the available offline data, and then use these skills to learn a robust policy that can handle a variety of situations.
The process works like this:
- Skill Learning: The system learns a set of diverse skills from the offline data. These skills represent different ways of accomplishing the task.
- Skill Diffusion: The system then takes these skills and "diffuses" them, meaning it combines them in different ways to learn a robust overall policy.
This two-stage process allows RPLOD to learn policies that are more flexible and adaptable than those learned by other offline RL methods. The researchers show that RPLOD outperforms state-of-the-art approaches on challenging benchmark tasks, demonstrating its effectiveness at learning robust policies from limited offline data.
Technical Explanation
The paper introduces a novel offline reinforcement learning (RL) algorithm called Robust Policy Learning via Offline Skill Diffusion (RPLOD). The key idea is to learn a diverse set of skills from offline data and then diffuse these skills to learn a robust policy.
The first stage of RPLOD is skill learning, where the system learns a set of diverse skills from the offline data. This is done by optimizing a skill-conditioned policy using a novel objective function that encourages the discovery of a diverse set of skills.
In the second stage, skill diffusion, the system combines these learned skills in different ways to learn a robust overall policy. Specifically, the system learns a skill-conditioned policy that can flexibly select and sequence the previously learned skills to handle a variety of situations.
To evaluate RPLOD, the researchers conduct experiments on challenging [object Object] and compare its performance to state-of-the-art offline RL methods. The results show that RPLOD significantly outperforms these baselines, demonstrating its effectiveness at learning robust policies from limited offline data.
Critical Analysis
The paper presents a promising approach for learning robust policies from offline data, but there are a few potential limitations and areas for further research:
-
Evaluation on Real-World Tasks: The experiments in the paper are conducted on simulated benchmark tasks, which may not fully capture the complexities of real-world environments. Further evaluation on real-world applications would be valuable to assess the practical applicability of RPLOD.
-
Scalability to High-Dimensional or Continuous State/Action Spaces: The paper does not discuss how RPLOD would scale to more complex environments with high-dimensional or continuous state and action spaces. Investigating the scalability of the approach would be an important direction for future work.
-
Interpretability of Learned Skills: While the paper demonstrates that RPLOD can learn diverse and robust skills, it does not provide much insight into the interpretability of these skills. Developing methods to better understand and interpret the learned skills could enhance the transparency and explainability of the approach.
-
Handling Distributional Shift: The paper assumes that the offline data comes from a single distribution. In real-world applications, the offline data may come from different distributions, which could lead to distributional shift issues. Extending RPLOD to handle such scenarios would be a valuable direction for future research.
Overall, the RPLOD approach represents an interesting contribution to the field of offline reinforcement learning, and the results suggest that it is a promising direction for learning robust policies from limited data. Further research addressing the potential limitations could help unlock the full potential of this approach.
Conclusion
The paper presents a novel offline reinforcement learning method called Robust Policy Learning via Offline Skill Diffusion (RPLOD), which learns diverse skills from offline data and then diffuses these skills to learn a robust policy. The key innovation is the two-stage process of skill learning and skill diffusion, which allows RPLOD to outperform state-of-the-art offline RL methods on challenging benchmark tasks.
While the paper demonstrates the effectiveness of RPLOD, there are still opportunities for further research to address potential limitations, such as evaluating the approach on real-world tasks, investigating scalability to more complex environments, and handling distributional shift in the offline data. Addressing these challenges could help unlock the full potential of RPLOD and advance the field of offline reinforcement learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Robust Policy Learning via Offline Skill Diffusion
Woo Kyung Kim, Minjong Yoo, Honguk Woo
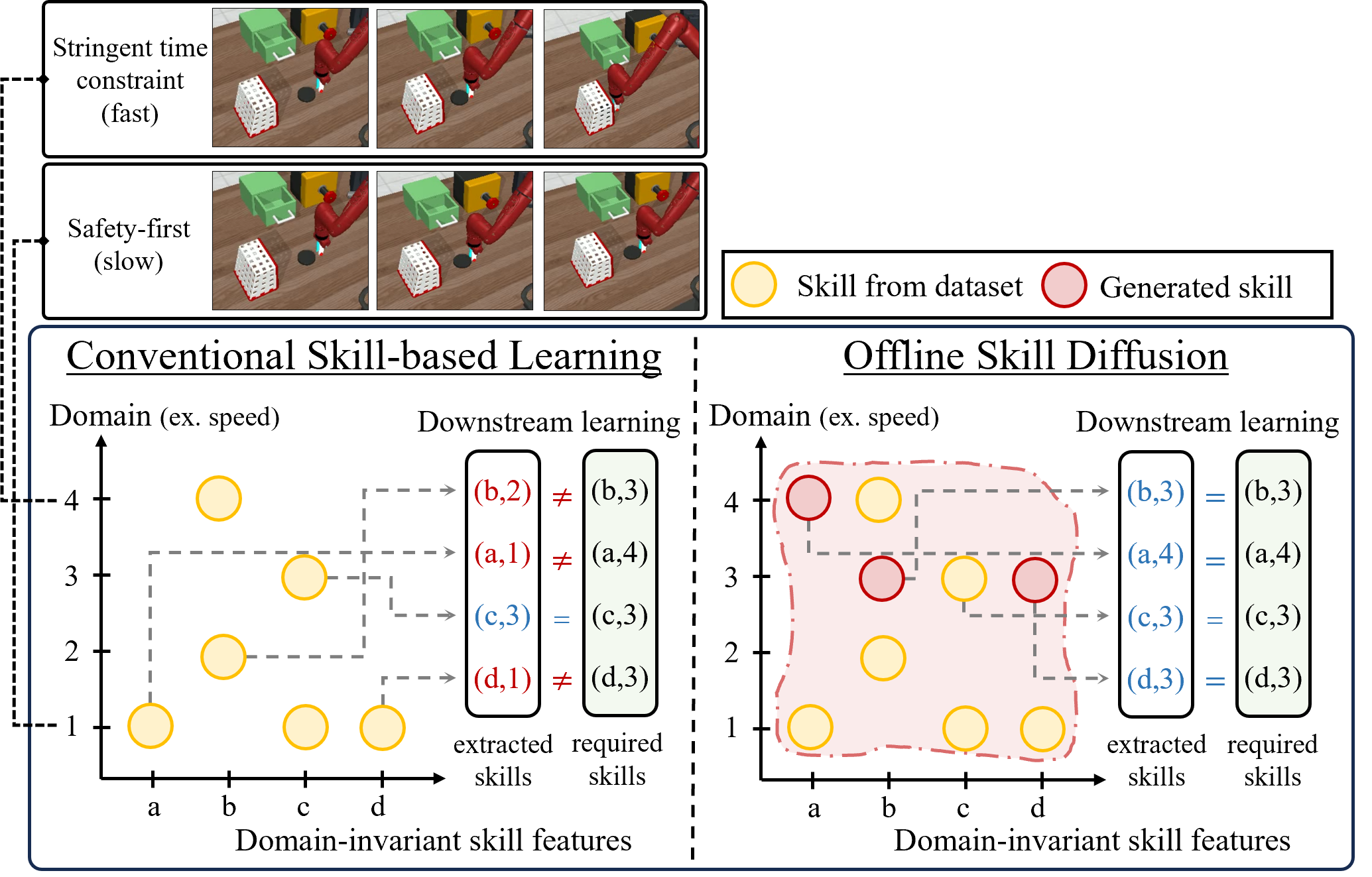
Skill-based reinforcement learning (RL) approaches have shown considerable promise, especially in solving long-horizon tasks via hierarchical structures. These skills, learned task-agnostically from offline datasets, can accelerate the policy learning process for new tasks. Yet, the application of these skills in different domains remains restricted due to their inherent dependency on the datasets, which poses a challenge when attempting to learn a skill-based policy via RL for a target domain different from the datasets' domains. In this paper, we present a novel offline skill learning framework DuSkill which employs a guided Diffusion model to generate versatile skills extended from the limited skills in datasets, thereby enhancing the robustness of policy learning for tasks in different domains. Specifically, we devise a guided diffusion-based skill decoder in conjunction with the hierarchical encoding to disentangle the skill embedding space into two distinct representations, one for encapsulating domain-invariant behaviors and the other for delineating the factors that induce domain variations in the behaviors. Our DuSkill framework enhances the diversity of skills learned offline, thus enabling to accelerate the learning procedure of high-level policies for different domains. Through experiments, we show that DuSkill outperforms other skill-based imitation learning and RL algorithms for several long-horizon tasks, demonstrating its benefits in few-shot imitation and online RL.
Read more8/23/2024
👨🏫
0
Offline Diversity Maximization Under Imitation Constraints
Marin Vlastelica, Jin Cheng, Georg Martius, Pavel Kolev
There has been significant recent progress in the area of unsupervised skill discovery, utilizing various information-theoretic objectives as measures of diversity. Despite these advances, challenges remain: current methods require significant online interaction, fail to leverage vast amounts of available task-agnostic data and typically lack a quantitative measure of skill utility. We address these challenges by proposing a principled offline algorithm for unsupervised skill discovery that, in addition to maximizing diversity, ensures that each learned skill imitates state-only expert demonstrations to a certain degree. Our main analytical contribution is to connect Fenchel duality, reinforcement learning, and unsupervised skill discovery to maximize a mutual information objective subject to KL-divergence state occupancy constraints. Furthermore, we demonstrate the effectiveness of our method on the standard offline benchmark D4RL and on a custom offline dataset collected from a 12-DoF quadruped robot for which the policies trained in simulation transfer well to the real robotic system.
Read more6/24/2024

0
Skills Regularized Task Decomposition for Multi-task Offline Reinforcement Learning
Minjong Yoo, Sangwoo Cho, Honguk Woo
Reinforcement learning (RL) with diverse offline datasets can have the advantage of leveraging the relation of multiple tasks and the common skills learned across those tasks, hence allowing us to deal with real-world complex problems efficiently in a data-driven way. In offline RL where only offline data is used and online interaction with the environment is restricted, it is yet difficult to achieve the optimal policy for multiple tasks, especially when the data quality varies for the tasks. In this paper, we present a skill-based multi-task RL technique on heterogeneous datasets that are generated by behavior policies of different quality. To learn the shareable knowledge across those datasets effectively, we employ a task decomposition method for which common skills are jointly learned and used as guidance to reformulate a task in shared and achievable subtasks. In this joint learning, we use Wasserstein auto-encoder (WAE) to represent both skills and tasks on the same latent space and use the quality-weighted loss as a regularization term to induce tasks to be decomposed into subtasks that are more consistent with high-quality skills than others. To improve the performance of offline RL agents learned on the latent space, we also augment datasets with imaginary trajectories relevant to high-quality skills for each task. Through experiments, we show that our multi-task offline RL approach is robust to the mixed configurations of different-quality datasets and it outperforms other state-of-the-art algorithms for several robotic manipulation tasks and drone navigation tasks.
Read more8/29/2024
0
Preferred-Action-Optimized Diffusion Policies for Offline Reinforcement Learning
Tianle Zhang, Jiayi Guan, Lin Zhao, Yihang Li, Dongjiang Li, Zecui Zeng, Lei Sun, Yue Chen, Xuelong Wei, Lusong Li, Xiaodong He
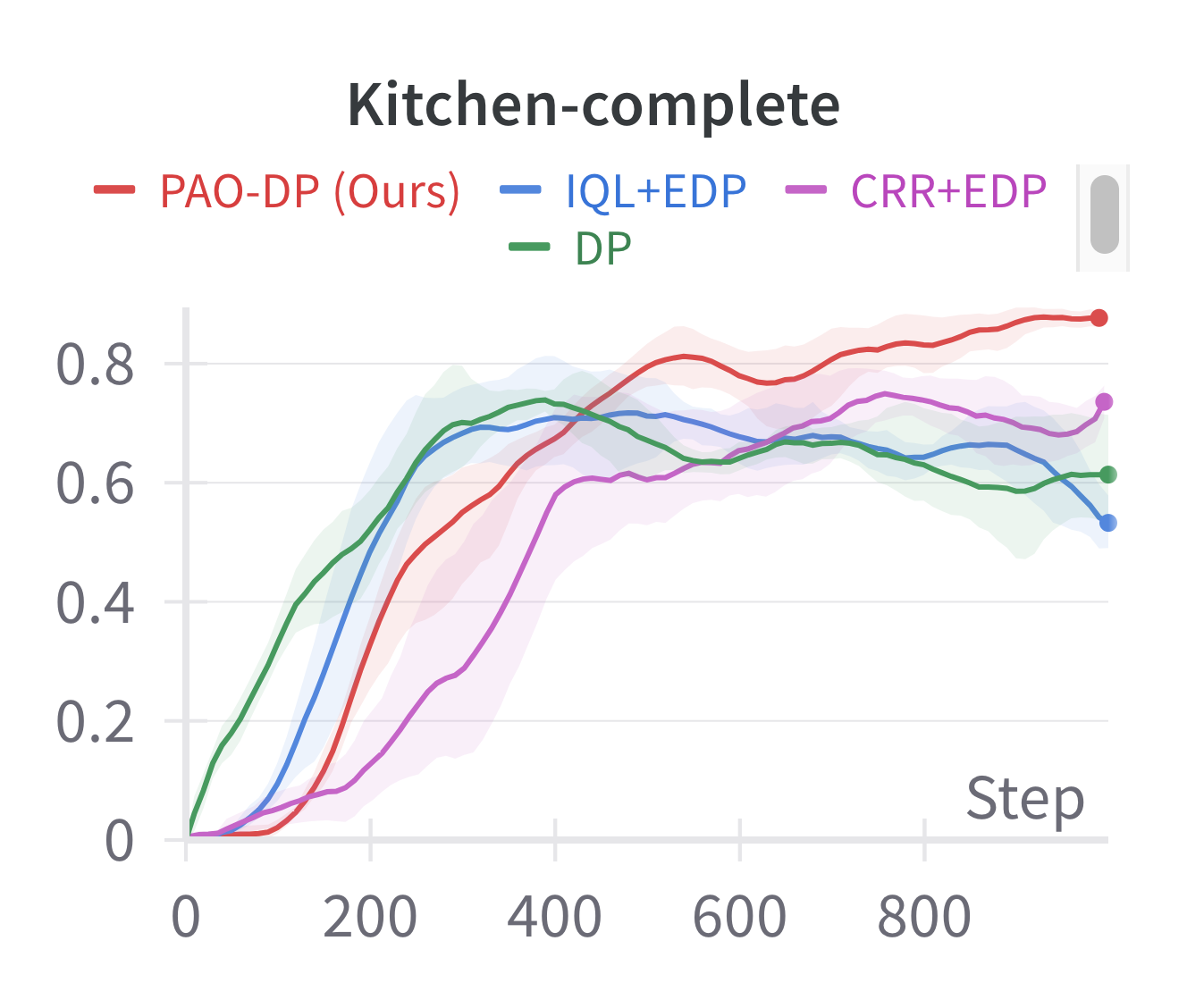
Offline reinforcement learning (RL) aims to learn optimal policies from previously collected datasets. Recently, due to their powerful representational capabilities, diffusion models have shown significant potential as policy models for offline RL issues. However, previous offline RL algorithms based on diffusion policies generally adopt weighted regression to improve the policy. This approach optimizes the policy only using the collected actions and is sensitive to Q-values, which limits the potential for further performance enhancement. To this end, we propose a novel preferred-action-optimized diffusion policy for offline RL. In particular, an expressive conditional diffusion model is utilized to represent the diverse distribution of a behavior policy. Meanwhile, based on the diffusion model, preferred actions within the same behavior distribution are automatically generated through the critic function. Moreover, an anti-noise preference optimization is designed to achieve policy improvement by using the preferred actions, which can adapt to noise-preferred actions for stable training. Extensive experiments demonstrate that the proposed method provides competitive or superior performance compared to previous state-of-the-art offline RL methods, particularly in sparse reward tasks such as Kitchen and AntMaze. Additionally, we empirically prove the effectiveness of anti-noise preference optimization.
Read more5/30/2024