Sliding-Window Thompson Sampling for Non-Stationary Settings

0
🔮
Sign in to get full access
Overview
- Restless Bandits are sequential decision-making problems where rewards change over time independently of the actions taken.
- Classical Bandit algorithms fail in non-stationary environments, requiring specialized algorithms to handle this additional complexity.
- This paper analyzes two Thompson-Sampling inspired algorithms, BETA-SWTS and γ-SWGTS, for Restless Bandits with Bernoulli and Subgaussian rewards.
- The authors derive a general regret formulation for these algorithms in any arbitrary Restless environment, and identify key factors contributing to the algorithms' errors.
- The paper also infers regret bounds for two common non-stationary settings: Abruptly Changing and Smoothly Changing environments.
Plain English Explanation
Restless Bandits are a type of decision-making problem where the rewards you get for different actions change over time, even if you don't change what you're doing. This makes them more challenging than classical Bandit problems, where the rewards stay the same.
In this paper, the authors look at two algorithms inspired by Thompson Sampling that are designed to handle these Restless Bandit problems. The algorithms are called BETA-SWTS and γ-SWGTS, and they can deal with rewards that follow either a Bernoulli or Subgaussian distribution.
The key contribution of the paper is that the authors derive a general formula for how much "regret" (i.e., how much worse your decisions are compared to the optimal decisions) these algorithms will have in any kind of Restless Bandit environment. They also identify the specific factors that contribute to the algorithms' errors.
Additionally, the paper looks at two common types of non-stationary environments - Abruptly Changing and Smoothly Changing - and calculates the expected regret for those specific cases.
Technical Explanation
The paper analyzes the performance of two Thompson-Sampling inspired algorithms, BETA-SWTS and γ-SWGTS, in the context of Restless Bandits.
For both Bernoulli and Subgaussian reward distributions, the authors derive a general regret formulation that holds for any arbitrary Restless environment. This is a significant contribution, as it allows the analysis of these algorithms beyond specific non-stationary setups.
The general regret bound introduced in the paper depends on several key quantities, including the "sliding window" size used by the algorithms, the magnitude and frequency of reward changes, and the intrinsic "complexity" of the Restless environment. By isolating the impact of these factors, the authors are able to provide insight into the core drivers of the algorithms' performance.
The paper also specializes the general regret bounds to two common non-stationary settings - Abruptly Changing and Smoothly Changing environments. This allows for a more concrete understanding of the algorithms' behavior in these practically-relevant scenarios.
Critical Analysis
The paper provides a rigorous and comprehensive analysis of the BETA-SWTS and γ-SWGTS algorithms for Restless Bandits. The authors' derivation of general regret bounds is a notable strength, as it allows the performance of these algorithms to be understood in a broader context beyond just specific non-stationary environments.
That said, the analysis is quite technical and mathematical in nature, which may limit its accessibility to a general audience. The use of domain-specific terminology and formal mathematical notation could make it challenging for readers without a strong background in Machine Learning and optimization to fully appreciate the insights.
Additionally, the paper does not provide extensive experimental validation of the theoretical results. While the authors do mention some simulation results, a more thorough empirical evaluation comparing the algorithms to other state-of-the-art approaches would help strengthen the practical relevance of the findings.
Finally, the paper does not address potential limitations or caveats of the proposed algorithms. For example, it would be helpful to understand the sensitivity of the algorithms to the choice of hyperparameters, such as the sliding window size, or their performance in the presence of other types of non-stationarity beyond the two considered settings.
Conclusion
This paper presents a rigorous analysis of two Thompson-Sampling inspired algorithms, BETA-SWTS and γ-SWGTS, for solving Restless Bandit problems. The key contribution is the derivation of general regret bounds that capture the impact of various factors, such as the magnitude and frequency of reward changes, on the algorithms' performance.
By providing this deeper understanding of the core drivers of the algorithms' errors, the paper lays important groundwork for developing more robust and effective techniques for decision-making in non-stationary environments. This has significant implications for a wide range of real-world applications, from recommendation systems to financial trading, where rewards are subject to continuous evolution over time.
While the technical nature of the analysis may limit the accessibility of the work to a general audience, the insights gained can inform the design of future Restless Bandit algorithms and inspire further research into this important class of sequential decision-making problems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔮
0
Sliding-Window Thompson Sampling for Non-Stationary Settings
Marco Fiandri, Alberto Maria Metelli, Francesco Trov`o
$textit{Restless Bandits}$ describe sequential decision-making problems in which the rewards evolve with time independently from the actions taken by the policy-maker. It has been shown that classical Bandit algorithms fail when the underlying environment is changing, making clear that in order to tackle more challenging scenarios specifically crafted algorithms are needed. In this paper, extending and correcting the work by cite{trovo2020sliding}, we analyze two Thompson-Sampling inspired algorithms, namely $texttt{BETA-SWTS}$ and $texttt{$gamma$-SWGTS}$, introduced to face the additional complexity given by the non-stationary nature of the settings; in particular we derive a general formulation for the regret in $textit{any}$ arbitrary restless environment for both Bernoulli and Subgaussian rewards, and, through the introduction of new quantities, we delve in what contribution lays the deeper foundations of the error made by the algorithms. Finally, we infer from the general formulation the regret for two of the most common non-stationary settings: the $textit{Abruptly Changing}$ and the $textit{Smoothly Changing}$ environments.
Read more9/14/2024
0
Efficient and Adaptive Posterior Sampling Algorithms for Bandits
Bingshan Hu, Zhiming Huang, Tianyue H. Zhang, Mathias L'ecuyer, Nidhi Hegde
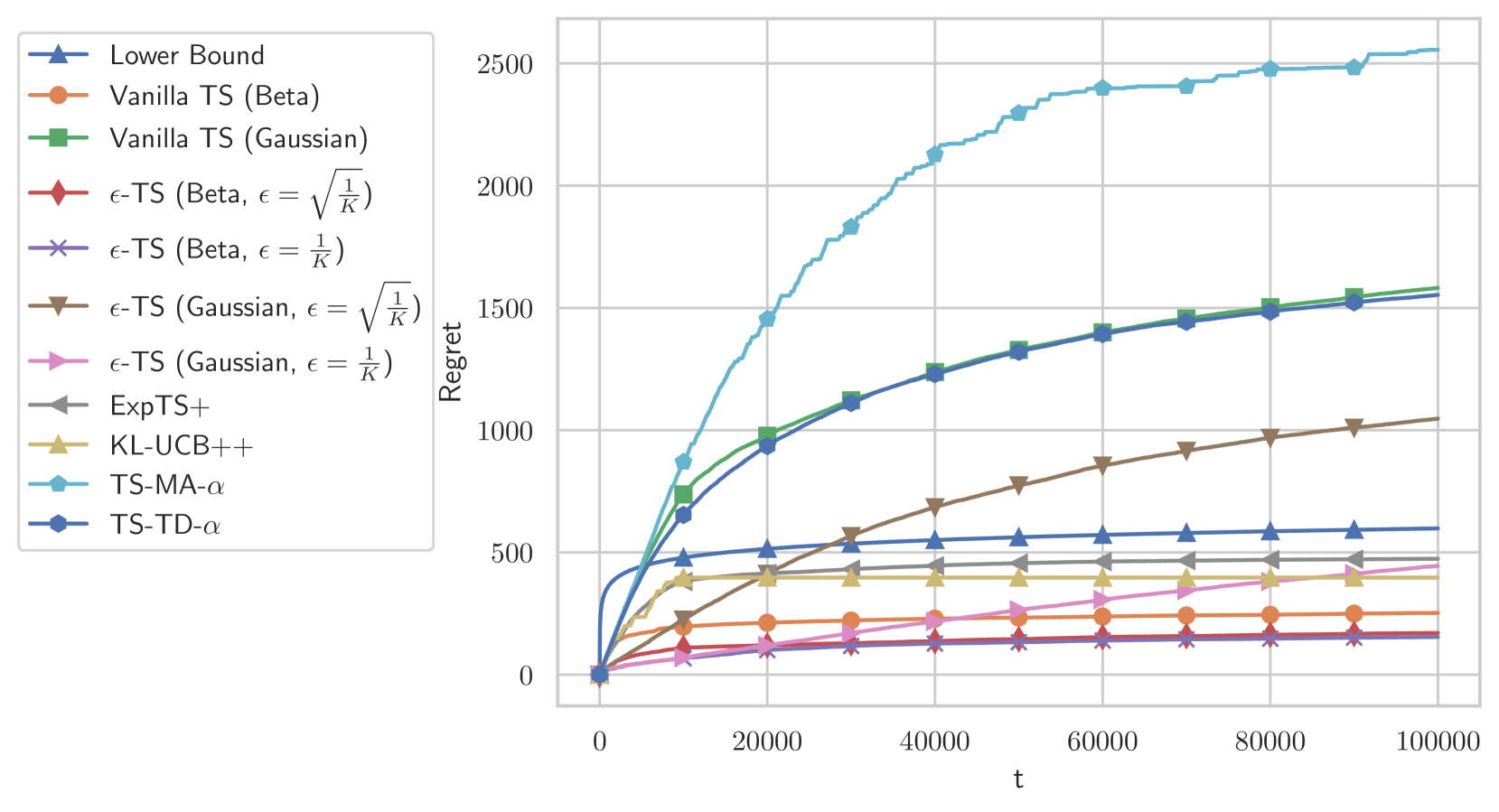
We study Thompson Sampling-based algorithms for stochastic bandits with bounded rewards. As the existing problem-dependent regret bound for Thompson Sampling with Gaussian priors [Agrawal and Goyal, 2017] is vacuous when $T le 288 e^{64}$, we derive a more practical bound that tightens the coefficient of the leading term %from $288 e^{64}$ to $1270$. Additionally, motivated by large-scale real-world applications that require scalability, adaptive computational resource allocation, and a balance in utility and computation, we propose two parameterized Thompson Sampling-based algorithms: Thompson Sampling with Model Aggregation (TS-MA-$alpha$) and Thompson Sampling with Timestamp Duelling (TS-TD-$alpha$), where $alpha in [0,1]$ controls the trade-off between utility and computation. Both algorithms achieve $O left(Kln^{alpha+1}(T)/Delta right)$ regret bound, where $K$ is the number of arms, $T$ is the finite learning horizon, and $Delta$ denotes the single round performance loss when pulling a sub-optimal arm.
Read more5/3/2024
🏷️
0
Adaptive Smooth Non-Stationary Bandits
Joe Suk
We study a $K$-armed non-stationary bandit model where rewards change smoothly, as captured by H{o}lder class assumptions on rewards as functions of time. Such smooth changes are parametrized by a H{o}lder exponent $beta$ and coefficient $lambda$. While various sub-cases of this general model have been studied in isolation, we first establish the minimax dynamic regret rate generally for all $K,beta,lambda$. Next, we show this optimal dynamic regret can be attained adaptively, without knowledge of $beta,lambda$. To contrast, even with parameter knowledge, upper bounds were only previously known for limited regimes $betaleq 1$ and $beta=2$ (Slivkins, 2014; Krishnamurthy and Gopalan, 2021; Manegueu et al., 2021; Jia et al.,2023). Thus, our work resolves open questions raised by these disparate threads of the literature. We also study the problem of attaining faster gap-dependent regret rates in non-stationary bandits. While such rates are long known to be impossible in general (Garivier and Moulines, 2011), we show that environments admitting a safe arm (Suk and Kpotufe, 2022) allow for much faster rates than the worst-case scaling with $sqrt{T}$. While previous works in this direction focused on attaining the usual logarithmic regret bounds, as summed over stationary periods, our new gap-dependent rates reveal new optimistic regimes of non-stationarity where even the logarithmic bounds are pessimistic. We show our new gap-dependent rate is tight and that its achievability (i.e., as made possible by a safe arm) has a surprisingly simple and clean characterization within the smooth H{o}lder class model.
Read more7/12/2024
✨
0
Non-Stationary Latent Auto-Regressive Bandits
Anna L. Trella, Walter Dempsey, Finale Doshi-Velez, Susan A. Murphy
We consider the stochastic multi-armed bandit problem with non-stationary rewards. We present a novel formulation of non-stationarity in the environment where changes in the mean reward of the arms over time are due to some unknown, latent, auto-regressive (AR) state of order $k$. We call this new environment the latent AR bandit. Different forms of the latent AR bandit appear in many real-world settings, especially in emerging scientific fields such as behavioral health or education where there are few mechanistic models of the environment. If the AR order $k$ is known, we propose an algorithm that achieves $tilde{O}(ksqrt{T})$ regret in this setting. Empirically, our algorithm outperforms standard UCB across multiple non-stationary environments, even if $k$ is mis-specified.
Read more8/13/2024