Efficient and Adaptive Posterior Sampling Algorithms for Bandits

0
Sign in to get full access
Overview
- The paper introduces efficient and adaptive posterior sampling algorithms for multi-armed bandits, a common problem in reinforcement learning and online decision-making.
- The proposed algorithms aim to improve upon existing methods by combining the strengths of Thompson Sampling and Kullback-Leibler (KL) divergence-based exploration, while addressing computational challenges.
- The algorithms are designed to be flexible, efficient, and scalable, making them applicable to a wide range of bandit problems.
Plain English Explanation
Multi-armed bandits are a type of decision-making problem where an agent (e.g., a recommendation system) must choose from a set of actions (e.g., which product to recommend) and receive a reward (e.g., user engagement) based on the chosen action. The goal is to learn which actions are the most rewarding and maximize the total reward over time.
The paper presents new algorithms that address some of the challenges in solving multi-armed bandits. The key ideas are:
-
Combining Thompson Sampling and KL Divergence: The algorithms blend the strengths of two popular approaches, Thompson Sampling and KL divergence-based exploration. This allows for efficient and adaptive decision-making, balancing exploration (trying new actions) and exploitation (choosing the best known actions).
-
Computational Efficiency: The algorithms are designed to be computationally efficient, making them practical for real-world applications, even when the number of actions is large.
-
Flexibility and Scalability: The algorithms can be applied to a wide range of bandit problems, including those with complex reward distributions or large action spaces, making them a versatile tool for various decision-making scenarios.
By combining these key features, the proposed algorithms aim to improve the performance and applicability of multi-armed bandit solutions, with potential benefits in areas like online recommendation systems, adaptive experimentation, and optimal decision-making under uncertainty.
Technical Explanation
The paper introduces two novel algorithms for solving multi-armed bandit problems: Adaptive Posterior Sampling (APS) and Efficient Posterior Sampling (EPS). These algorithms build upon the principles of Thompson Sampling and KL divergence-based exploration, while addressing computational challenges.
The key technical contributions are:
-
Adaptive Posterior Sampling (APS): This algorithm adaptively adjusts the exploration-exploitation trade-off by using a KL divergence-based criterion to guide the posterior sampling process. This allows the algorithm to focus more on exploring uncertain actions and gradually shift towards exploiting the most promising ones.
-
Efficient Posterior Sampling (EPS): To address the computational challenges of posterior sampling, the EPS algorithm employs a novel technique that approximates the posterior distribution using a set of weighted samples. This approach significantly reduces the computational cost, making the algorithm scalable to large-scale problems.
The paper also presents a regret analysis of the proposed algorithms, proving that they achieve near-optimal regret bounds under certain assumptions. The experiments demonstrate the superior performance of APS and EPS compared to state-of-the-art bandit algorithms, particularly in terms of computational efficiency and adaptability to complex reward distributions.
Critical Analysis
The paper presents a solid technical contribution to the field of multi-armed bandits. The proposed algorithms, APS and EPS, offer a compelling balance between exploration, exploitation, and computational efficiency, addressing important limitations of existing methods.
One potential limitation of the research is the reliance on certain assumptions, such as the availability of a known prior distribution for the rewards. In real-world scenarios, this prior knowledge may not always be available, and the algorithms' performance may be affected. It would be valuable to explore extensions or alternative approaches that can handle more realistic scenarios with unknown or complex prior distributions.
Additionally, while the paper provides theoretical guarantees and empirical evaluations, it would be insightful to see further analysis on the algorithm's robustness to factors like non-stationary reward distributions or the presence of outliers. Exploring these aspects could enhance the practical applicability of the proposed methods.
Finally, the paper focuses primarily on the technical aspects of the algorithms, but a more in-depth discussion of the potential societal implications and ethical considerations of deploying such decision-making systems in real-world applications would be a valuable addition.
Conclusion
The paper introduces two efficient and adaptive posterior sampling algorithms, APS and EPS, for solving multi-armed bandit problems. These algorithms combine the strengths of Thompson Sampling and KL divergence-based exploration, addressing computational challenges and aiming to improve the performance and scalability of bandit solutions.
The proposed algorithms have the potential to benefit a wide range of applications, from online recommendation systems to adaptive experimentation and optimal decision-making under uncertainty. By providing efficient and adaptive exploration-exploitation strategies, the algorithms can help organizations and individuals make more informed and data-driven decisions, ultimately leading to improved outcomes and experiences.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Efficient and Adaptive Posterior Sampling Algorithms for Bandits
Bingshan Hu, Zhiming Huang, Tianyue H. Zhang, Mathias L'ecuyer, Nidhi Hegde
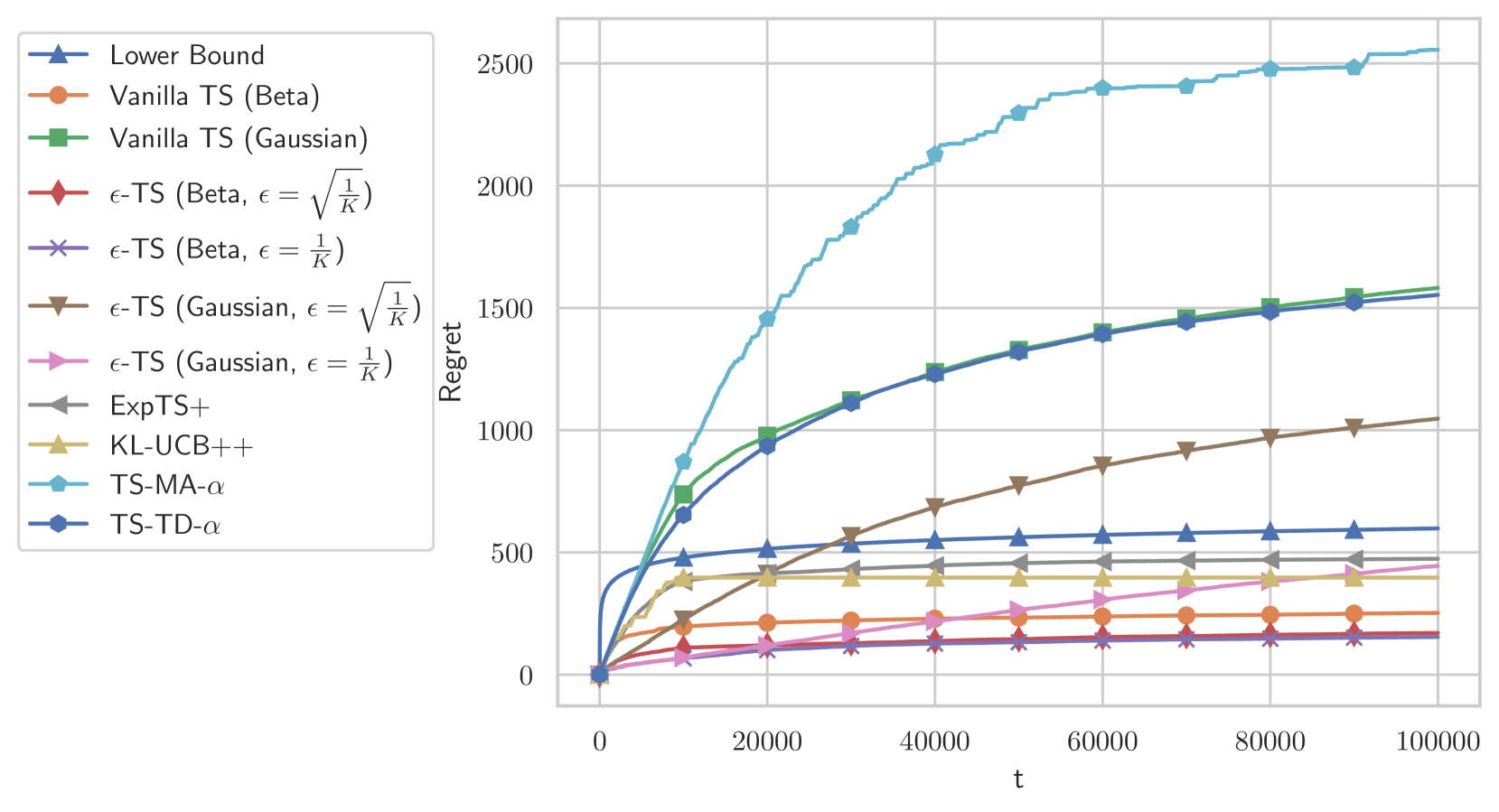
We study Thompson Sampling-based algorithms for stochastic bandits with bounded rewards. As the existing problem-dependent regret bound for Thompson Sampling with Gaussian priors [Agrawal and Goyal, 2017] is vacuous when $T le 288 e^{64}$, we derive a more practical bound that tightens the coefficient of the leading term %from $288 e^{64}$ to $1270$. Additionally, motivated by large-scale real-world applications that require scalability, adaptive computational resource allocation, and a balance in utility and computation, we propose two parameterized Thompson Sampling-based algorithms: Thompson Sampling with Model Aggregation (TS-MA-$alpha$) and Thompson Sampling with Timestamp Duelling (TS-TD-$alpha$), where $alpha in [0,1]$ controls the trade-off between utility and computation. Both algorithms achieve $O left(Kln^{alpha+1}(T)/Delta right)$ regret bound, where $K$ is the number of arms, $T$ is the finite learning horizon, and $Delta$ denotes the single round performance loss when pulling a sub-optimal arm.
Read more5/3/2024

0
Thompson Sampling Itself is Differentially Private
Tingting Ou, Marco Avella Medina, Rachel Cummings
In this work we first show that the classical Thompson sampling algorithm for multi-arm bandits is differentially private as-is, without any modification. We provide per-round privacy guarantees as a function of problem parameters and show composition over $T$ rounds; since the algorithm is unchanged, existing $O(sqrt{NTlog N})$ regret bounds still hold and there is no loss in performance due to privacy. We then show that simple modifications -- such as pre-pulling all arms a fixed number of times, increasing the sampling variance -- can provide tighter privacy guarantees. We again provide privacy guarantees that now depend on the new parameters introduced in the modification, which allows the analyst to tune the privacy guarantee as desired. We also provide a novel regret analysis for this new algorithm, and show how the new parameters also impact expected regret. Finally, we empirically validate and illustrate our theoretical findings in two parameter regimes and demonstrate that tuning the new parameters substantially improve the privacy-regret tradeoff.
Read more7/23/2024
➖
0
Distilled Thompson Sampling: Practical and Efficient Thompson Sampling via Imitation Learning
Hongseok Namkoong, Samuel Daulton, Eytan Bakshy
Thompson sampling (TS) has emerged as a robust technique for contextual bandit problems. However, TS requires posterior inference and optimization for action generation, prohibiting its use in many online platforms where latency and ease of deployment are of concern. We operationalize TS by proposing a novel imitation-learning-based algorithm that distills a TS policy into an explicit policy representation, allowing fast decision-making and easy deployment in mobile and server-based environments. Using batched data collected under the imitation policy, our algorithm iteratively performs offline updates to the TS policy, and learns a new explicit policy representation to imitate it. Empirically, our imitation policy achieves performance comparable to batch TS while allowing more than an order of magnitude reduction in decision-time latency. Buoyed by low latency and simplicity of implementation, our algorithm has been successfully deployed in multiple video upload systems for Meta. Using a randomized controlled trial, we show our algorithm resulted in significant improvements in video quality and watch time.
Read more7/23/2024
🛠️
0
Thompson Sampling for Infinite-Horizon Discounted Decision Processes
Daniel Adelman, Cagla Keceli, Alba V. Olivares-Nadal
We model a Markov decision process, parametrized by an unknown parameter, and study the asymptotic behavior of a sampling-based algorithm, called Thompson sampling. The standard definition of regret is not always suitable to evaluate a policy, especially when the underlying chain structure is general. We show that the standard (expected) regret can grow (super-)linearly and fails to capture the notion of learning in realistic settings with non-trivial state evolution. By decomposing the standard (expected) regret, we develop a new metric, called the expected residual regret, which forgets the immutable consequences of past actions. Instead, it measures regret against the optimal reward moving forward from the current period. We show that the expected residual regret of the Thompson sampling algorithm is upper bounded by a term which converges exponentially fast to 0. We present conditions under which the posterior sampling error of Thompson sampling converges to 0 almost surely. We then introduce the probabilistic version of the expected residual regret and present conditions under which it converges to 0 almost surely. Thus, we provide a viable concept of learning for sampling algorithms which will serve useful in broader settings than had been considered previously.
Read more5/20/2024