SMCL: Saliency Masked Contrastive Learning for Long-tailed Recognition
2406.02223
0
0

Abstract
Real-world data often follow a long-tailed distribution with a high imbalance in the number of samples between classes. The problem with training from imbalanced data is that some background features, common to all classes, can be unobserved in classes with scarce samples. As a result, this background correlates to biased predictions into ``major classes. In this paper, we propose saliency masked contrastive learning, a new method that uses saliency masking and contrastive learning to mitigate the problem and improve the generalizability of a model. Our key idea is to mask the important part of an image using saliency detection and use contrastive learning to move the masked image towards minor classes in the feature space, so that background features present in the masked image are no longer correlated with the original class. Experiment results show that our method achieves state-of-the-art level performance on benchmark long-tailed datasets.
Create account to get full access
Overview
• This paper proposes a new approach called Saliency Masked Contrastive Learning (SMCL) to address the long-tailed visual recognition problem, where some classes have significantly fewer training examples than others.
• The key idea is to use saliency maps to identify the most informative regions of an image and focus the contrastive learning process on these salient regions, rather than treating the entire image equally.
Plain English Explanation
• In many real-world datasets, there is an imbalance in the number of examples for different classes. For example, there may be lots of images of common objects like cars, but far fewer images of rare objects like giraffes.
• This imbalance can make it challenging for machine learning models to learn to recognize the rare classes effectively. The paper "Exploring Contrastive Learning for Long-Tailed Multi-Label Classification" and the paper "A Latent-Based Diffusion Model for Long-Tailed Recognition"](https://aimodels.fyi/papers/arxiv/latent-based-diffusion-model-long-tailed-recognition) have also looked at this problem.
• The SMCL approach tries to address this by focusing the model's learning on the most important parts of each image, rather than treating all regions equally. It uses "saliency maps" to identify the most visually salient regions, and then uses these salient regions as the basis for the contrastive learning process.
• The intuition is that by emphasizing the most informative parts of each image, the model can learn more effectively, even for the rare classes that have fewer training examples. The paper "ContextRAST: Contextual Contrastive Learning for Semantic Segmentation" has also explored using context information to improve contrastive learning.
Technical Explanation
• The SMCL approach builds on the success of contrastive learning, a technique that has shown promise for long-tailed recognition tasks. Contrastive learning aims to learn representations by maximizing the similarity between "positive" examples (e.g., different views of the same image) and minimizing the similarity between "negative" examples (e.g., different images).
• However, the standard contrastive learning approach treats all regions of an image equally, which may not be optimal for long-tailed datasets where the most informative regions are crucial for recognizing rare classes.
• SMCL addresses this by using saliency maps to identify the most visually salient regions of each image. It then uses these salient regions as the basis for the contrastive learning process, rather than using the entire image.
• Specifically, SMCL first computes a saliency map for each input image using a pre-trained saliency detection model. It then masks the input image with the saliency map, effectively emphasizing the salient regions and de-emphasizing the less informative regions.
• This saliency-masked image is then used as the input to the contrastive learning process, where the model learns to maximize the similarity between positive examples (saliency-masked images of the same class) and minimize the similarity between negative examples (saliency-masked images of different classes).
• The authors show that this saliency-guided contrastive learning approach outperforms standard contrastive learning and other state-of-the-art methods for long-tailed visual recognition tasks. The paper "Neglected Tails in Vision-Language Models" has also explored issues with long-tailed distributions in vision-language models.
Critical Analysis
• One potential limitation of the SMCL approach is that it relies on a pre-trained saliency detection model, which may not be perfectly aligned with the most informative regions for the specific long-tailed recognition task at hand. The paper "A Clinical-Oriented Multi-Level Contrastive Learning Method" has explored ways to learn task-specific saliency maps in a more integrated way.
• Additionally, the SMCL approach may be sensitive to the quality and accuracy of the saliency maps, and it's not clear how robust the method would be to noisy or imperfect saliency information.
• Further research could explore ways to make the saliency detection more integrated with the contrastive learning process, or to learn saliency information directly from the data in a more end-to-end fashion.
Conclusion
• The SMCL approach represents an interesting and promising step towards addressing the long-tailed visual recognition problem, by leveraging saliency information to guide the contrastive learning process.
• By focusing the model's attention on the most informative regions of each image, SMCL can learn more effective representations, even for rare classes with limited training data.
• While the method has some potential limitations, it opens up new directions for research in long-tailed recognition, and could have important implications for real-world applications where data imbalance is a common challenge.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Masking Improves Contrastive Self-Supervised Learning for ConvNets, and Saliency Tells You Where
Zhi-Yi Chin, Chieh-Ming Jiang, Ching-Chun Huang, Pin-Yu Chen, Wei-Chen Chiu
0
0
While image data starts to enjoy the simple-but-effective self-supervised learning scheme built upon masking and self-reconstruction objective thanks to the introduction of tokenization procedure and vision transformer backbone, convolutional neural networks as another important and widely-adopted architecture for image data, though having contrastive-learning techniques to drive the self-supervised learning, still face the difficulty of leveraging such straightforward and general masking operation to benefit their learning process significantly. In this work, we aim to alleviate the burden of including masking operation into the contrastive-learning framework for convolutional neural networks as an extra augmentation method. In addition to the additive but unwanted edges (between masked and unmasked regions) as well as other adverse effects caused by the masking operations for ConvNets, which have been discussed by prior works, we particularly identify the potential problem where for one view in a contrastive sample-pair the randomly-sampled masking regions could be overly concentrated on important/salient objects thus resulting in misleading contrastiveness to the other view. To this end, we propose to explicitly take the saliency constraint into consideration in which the masked regions are more evenly distributed among the foreground and background for realizing the masking-based augmentation. Moreover, we introduce hard negative samples by masking larger regions of salient patches in an input image. Extensive experiments conducted on various datasets, contrastive learning mechanisms, and downstream tasks well verify the efficacy as well as the superior performance of our proposed method with respect to several state-of-the-art baselines.
6/11/2024

Saliency-guided and Patch-based Mixup for Long-tailed Skin Cancer Image Classification
Tianyunxi Wei, Yijin Huang, Li Lin, Pujin Cheng, Sirui Li, Xiaoying Tang
0
0
Medical image datasets often exhibit long-tailed distributions due to the inherent challenges in medical data collection and annotation. In long-tailed contexts, some common disease categories account for most of the data, while only a few samples are available in the rare disease categories, resulting in poor performance of deep learning methods. To address this issue, previous approaches have employed class re-sampling or re-weighting techniques, which often encounter challenges such as overfitting to tail classes or difficulties in optimization during training. In this work, we propose a novel approach, namely textbf{S}aliency-guided and textbf{P}atch-based textbf{Mix}up (SPMix) for long-tailed skin cancer image classification. Specifically, given a tail-class image and a head-class image, we generate a new tail-class image by mixing them under the guidance of saliency mapping, which allows for preserving and augmenting the discriminative features of the tail classes without any interference of the head-class features. Extensive experiments are conducted on the ISIC2018 dataset, demonstrating the superiority of SPMix over existing state-of-the-art methods.
6/18/2024
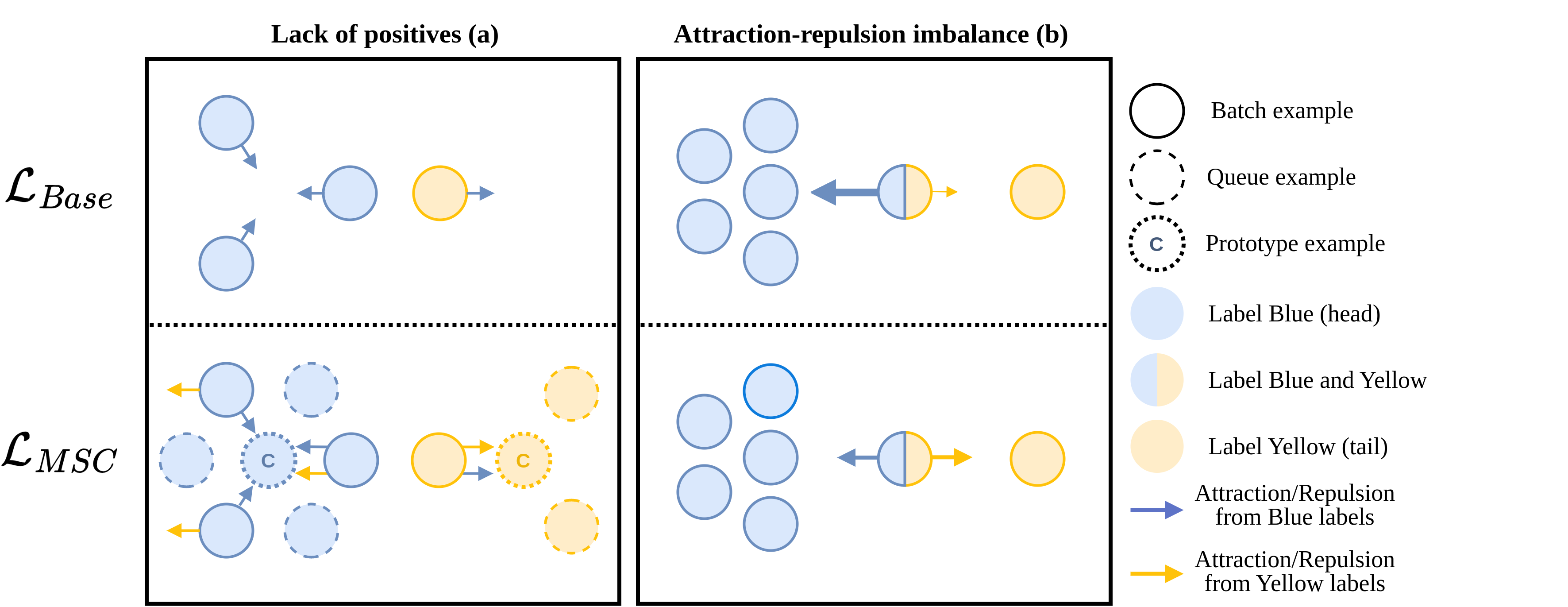
Exploring Contrastive Learning for Long-Tailed Multi-Label Text Classification
Alexandre Audibert, Aur'elien Gauffre, Massih-Reza Amini
0
0
Learning an effective representation in multi-label text classification (MLTC) is a significant challenge in NLP. This challenge arises from the inherent complexity of the task, which is shaped by two key factors: the intricate connections between labels and the widespread long-tailed distribution of the data. To overcome this issue, one potential approach involves integrating supervised contrastive learning with classical supervised loss functions. Although contrastive learning has shown remarkable performance in multi-class classification, its impact in the multi-label framework has not been thoroughly investigated. In this paper, we conduct an in-depth study of supervised contrastive learning and its influence on representation in MLTC context. We emphasize the importance of considering long-tailed data distributions to build a robust representation space, which effectively addresses two critical challenges associated with contrastive learning that we identify: the lack of positives and the attraction-repulsion imbalance. Building on this insight, we introduce a novel contrastive loss function for MLTC. It attains Micro-F1 scores that either match or surpass those obtained with other frequently employed loss functions, and demonstrates a significant improvement in Macro-F1 scores across three multi-label datasets.
4/16/2024
📶
Learning Discriminative Features for Crowd Counting
Yuehai Chen, Qingzhong Wang, Jing Yang, Badong Chen, Haoyi Xiong, Shaoyi Du
0
0
Crowd counting models in highly congested areas confront two main challenges: weak localization ability and difficulty in differentiating between foreground and background, leading to inaccurate estimations. The reason is that objects in highly congested areas are normally small and high level features extracted by convolutional neural networks are less discriminative to represent small objects. To address these problems, we propose a learning discriminative features framework for crowd counting, which is composed of a masked feature prediction module (MPM) and a supervised pixel-level contrastive learning module (CLM). The MPM randomly masks feature vectors in the feature map and then reconstructs them, allowing the model to learn about what is present in the masked regions and improving the model's ability to localize objects in high density regions. The CLM pulls targets close to each other and pushes them far away from background in the feature space, enabling the model to discriminate foreground objects from background. Additionally, the proposed modules can be beneficial in various computer vision tasks, such as crowd counting and object detection, where dense scenes or cluttered environments pose challenges to accurate localization. The proposed two modules are plug-and-play, incorporating the proposed modules into existing models can potentially boost their performance in these scenarios.
6/19/2024