Exploring Contrastive Learning for Long-Tailed Multi-Label Text Classification
2404.08720
0
0
Abstract
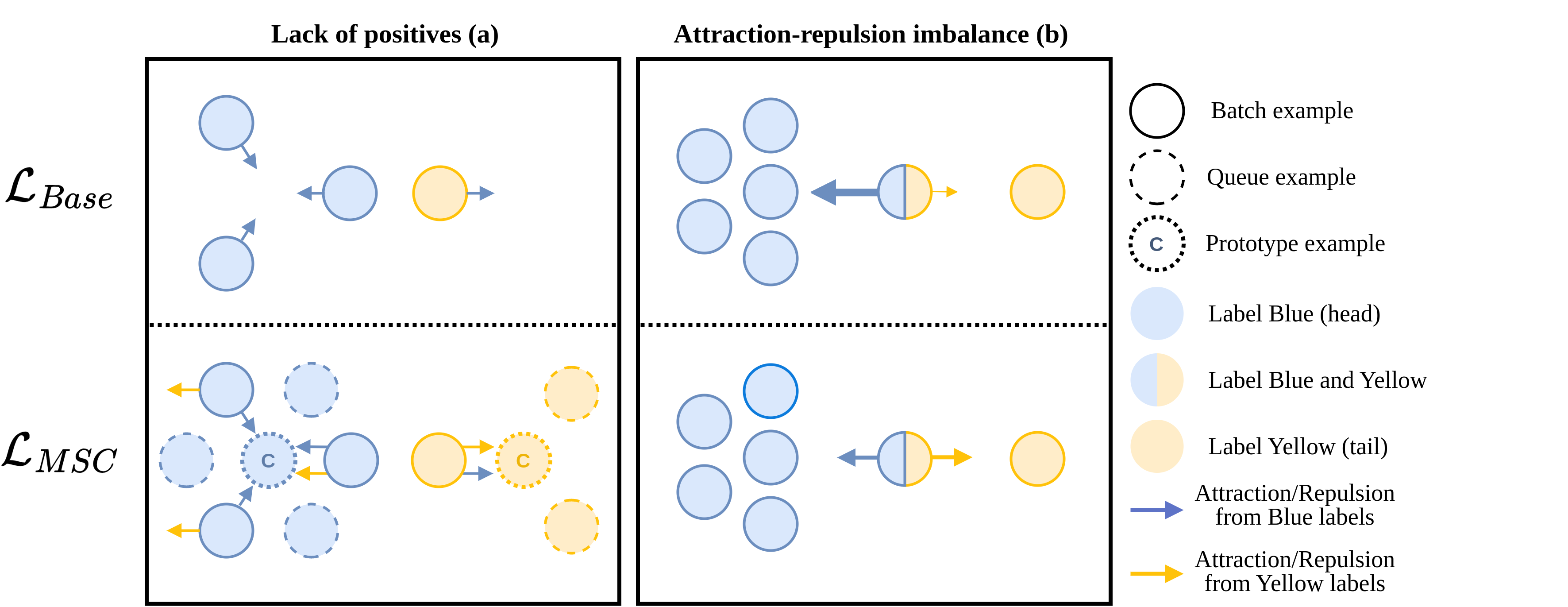
Learning an effective representation in multi-label text classification (MLTC) is a significant challenge in NLP. This challenge arises from the inherent complexity of the task, which is shaped by two key factors: the intricate connections between labels and the widespread long-tailed distribution of the data. To overcome this issue, one potential approach involves integrating supervised contrastive learning with classical supervised loss functions. Although contrastive learning has shown remarkable performance in multi-class classification, its impact in the multi-label framework has not been thoroughly investigated. In this paper, we conduct an in-depth study of supervised contrastive learning and its influence on representation in MLTC context. We emphasize the importance of considering long-tailed data distributions to build a robust representation space, which effectively addresses two critical challenges associated with contrastive learning that we identify: the lack of positives and the attraction-repulsion imbalance. Building on this insight, we introduce a novel contrastive loss function for MLTC. It attains Micro-F1 scores that either match or surpass those obtained with other frequently employed loss functions, and demonstrates a significant improvement in Macro-F1 scores across three multi-label datasets.
Create account to get full access
Overview
- This paper explores contrastive learning as a way to address the challenge of long-tailed multi-label text classification.
- Long-tailed distributions, where a few labels have many examples and most labels have few examples, are common in real-world datasets.
- Contrastive learning is a technique that can help models learn more effectively from these imbalanced datasets.
Plain English Explanation
Contrastive learning is a machine learning technique that can help models learn better from datasets where some labels (or categories) have many examples, while most labels have only a few examples. This is a common problem, known as a "long-tailed distribution."
In a long-tailed dataset, the model may struggle to learn the less common labels properly. Contrastive learning can address this by training the model to not only learn the content of each example, but also to recognize how examples with the same label are different from examples with other labels. This helps the model better distinguish between the various labels, even the rare ones.
The researchers in this paper investigated how contrastive learning techniques can be applied to long-tailed multi-label text classification problems. Multi-label means that each example can have multiple labels assigned to it, rather than just a single label. The paper explores different ways of incorporating contrastive learning into the model architecture and training process to improve performance on these challenging datasets.
Technical Explanation
The paper proposes a contrastive learning framework for long-tailed multi-label text classification. The key elements of their approach include:
-
Supervised Contrastive Learning: The model is trained not only to predict the correct labels for each example, but also to ensure that examples with the same label are embedded closer together in the model's representation space, while examples with different labels are pushed further apart. This helps the model better distinguish between the various labels, even the rare ones.
-
Focal Contrastive Loss: The researchers introduce a focal contrastive loss function that applies higher weights to the less common labels, ensuring the model pays more attention to learning the rare labels effectively.
-
Label-Aware Contrastive Sampling: The model selects positive and negative examples for the contrastive loss in a label-aware manner, focusing on harder-to-learn labels during training.
The researchers evaluate their approach on several long-tailed multi-label text classification datasets and show that it outperforms previous state-of-the-art methods, particularly in terms of improving performance on the rare labels.
Critical Analysis
The paper presents a promising approach for addressing the challenges of long-tailed multi-label text classification. The use of contrastive learning techniques is well-motivated and the experimental results demonstrate the effectiveness of the proposed methods.
However, the paper does not discuss potential limitations or caveats of the approach. For example, it would be helpful to understand how the performance of the contrastive learning methods scale with the degree of label imbalance in the dataset, or how sensitive the results are to the specific hyperparameter settings.
Additionally, the paper could have provided more insights into the underlying reasons why the contrastive learning techniques are so effective for this problem. A deeper analysis of the learned representations or the behavior of the model on rare labels could have contributed to a better understanding of the strengths and weaknesses of the approach.
Conclusion
This paper demonstrates the value of contrastive learning for tackling the long-tailed multi-label text classification problem. By training the model to not only predict the correct labels but also to learn distinctive representations for each label, the proposed methods can significantly improve performance, especially on the rare labels that are often overlooked by traditional approaches.
The findings in this paper have the potential to benefit a wide range of real-world applications, such as multi-label text classification in areas like customer service, content moderation, and scientific literature analysis, where long-tailed label distributions are common. The techniques explored in this work could also be extended to other domains beyond text, providing a valuable contribution to the field of machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Simple-Sampling and Hard-Mixup with Prototypes to Rebalance Contrastive Learning for Text Classification
Mengyu Li, Yonghao Liu, Fausto Giunchiglia, Xiaoyue Feng, Renchu Guan
0
0
Text classification is a crucial and fundamental task in natural language processing. Compared with the previous learning paradigm of pre-training and fine-tuning by cross entropy loss, the recently proposed supervised contrastive learning approach has received tremendous attention due to its powerful feature learning capability and robustness. Although several studies have incorporated this technique for text classification, some limitations remain. First, many text datasets are imbalanced, and the learning mechanism of supervised contrastive learning is sensitive to data imbalance, which may harm the model performance. Moreover, these models leverage separate classification branch with cross entropy and supervised contrastive learning branch without explicit mutual guidance. To this end, we propose a novel model named SharpReCL for imbalanced text classification tasks. First, we obtain the prototype vector of each class in the balanced classification branch to act as a representation of each class. Then, by further explicitly leveraging the prototype vectors, we construct a proper and sufficient target sample set with the same size for each class to perform the supervised contrastive learning procedure. The empirical results show the effectiveness of our model, which even outperforms popular large language models across several datasets.
5/21/2024
Bayesian Learning-driven Prototypical Contrastive Loss for Class-Incremental Learning
Nisha L. Raichur, Lucas Heublein, Tobias Feigl, Alexander Rugamer, Christopher Mutschler, Felix Ott
0
0
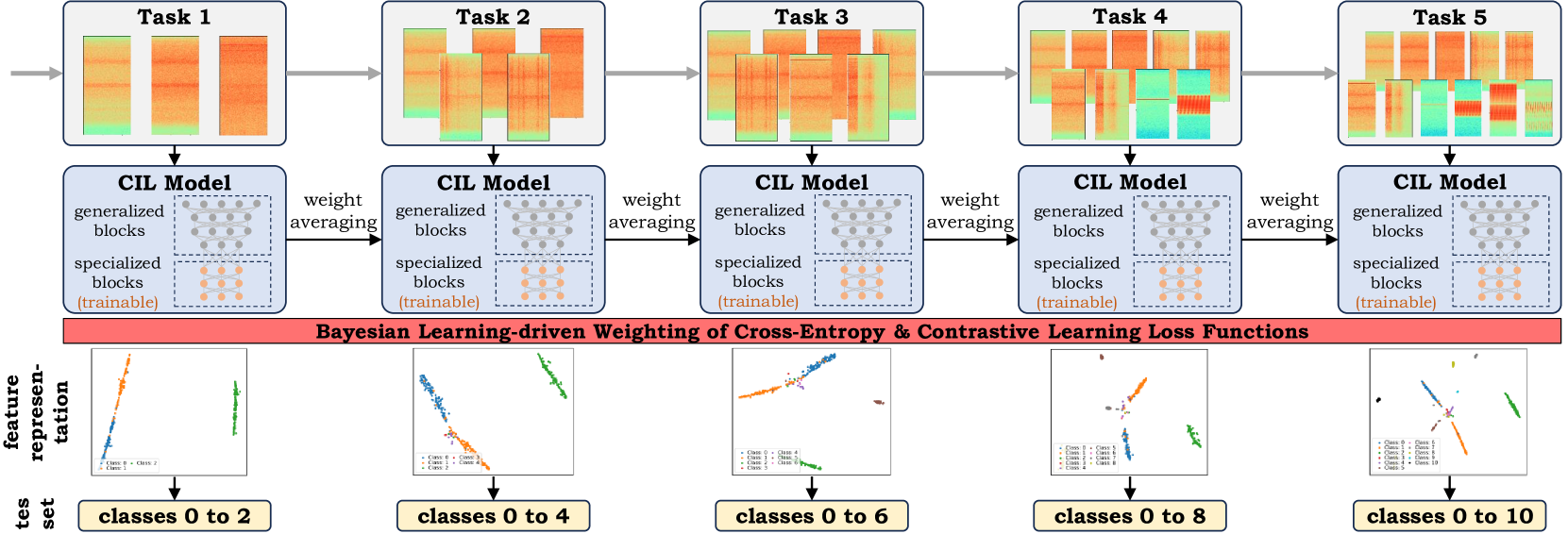
The primary objective of methods in continual learning is to learn tasks in a sequential manner over time from a stream of data, while mitigating the detrimental phenomenon of catastrophic forgetting. In this paper, we focus on learning an optimal representation between previous class prototypes and newly encountered ones. We propose a prototypical network with a Bayesian learning-driven contrastive loss (BLCL) tailored specifically for class-incremental learning scenarios. Therefore, we introduce a contrastive loss that incorporates new classes into the latent representation by reducing the intra-class distance and increasing the inter-class distance. Our approach dynamically adapts the balance between the cross-entropy and contrastive loss functions with a Bayesian learning technique. Empirical evaluations conducted on both the CIFAR-10 dataset for image classification and images of a GNSS-based dataset for interference classification validate the efficacy of our method, showcasing its superiority over existing state-of-the-art approaches.
5/21/2024

SMCL: Saliency Masked Contrastive Learning for Long-tailed Recognition
Sanglee Park, Seung-won Hwang, Jungmin So
0
0
Real-world data often follow a long-tailed distribution with a high imbalance in the number of samples between classes. The problem with training from imbalanced data is that some background features, common to all classes, can be unobserved in classes with scarce samples. As a result, this background correlates to biased predictions into ``major classes. In this paper, we propose saliency masked contrastive learning, a new method that uses saliency masking and contrastive learning to mitigate the problem and improve the generalizability of a model. Our key idea is to mask the important part of an image using saliency detection and use contrastive learning to move the masked image towards minor classes in the feature space, so that background features present in the masked image are no longer correlated with the original class. Experiment results show that our method achieves state-of-the-art level performance on benchmark long-tailed datasets.
6/5/2024
DELTA: Decoupling Long-Tailed Online Continual Learning
Siddeshwar Raghavan, Jiangpeng He, Fengqing Zhu
0
0
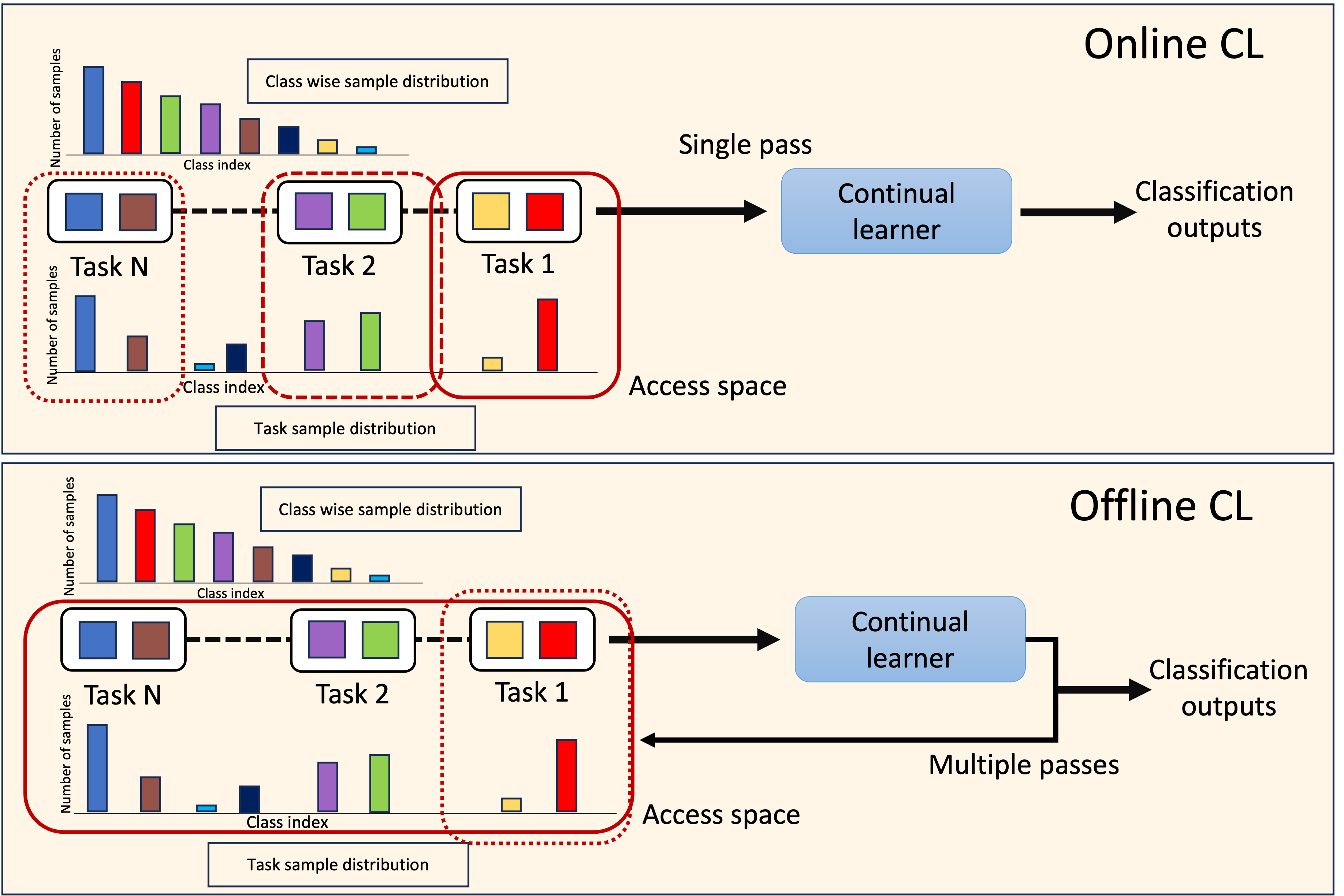
A significant challenge in achieving ubiquitous Artificial Intelligence is the limited ability of models to rapidly learn new information in real-world scenarios where data follows long-tailed distributions, all while avoiding forgetting previously acquired knowledge. In this work, we study the under-explored problem of Long-Tailed Online Continual Learning (LTOCL), which aims to learn new tasks from sequentially arriving class-imbalanced data streams. Each data is observed only once for training without knowing the task data distribution. We present DELTA, a decoupled learning approach designed to enhance learning representations and address the substantial imbalance in LTOCL. We enhance the learning process by adapting supervised contrastive learning to attract similar samples and repel dissimilar (out-of-class) samples. Further, by balancing gradients during training using an equalization loss, DELTA significantly enhances learning outcomes and successfully mitigates catastrophic forgetting. Through extensive evaluation, we demonstrate that DELTA improves the capacity for incremental learning, surpassing existing OCL methods. Our results suggest considerable promise for applying OCL in real-world applications.
4/9/2024