Smooth Anonymity for Sparse Graphs

0
📉
Sign in to get full access
Overview
- Researchers aim to share an entire sparse dataset with a third party while guaranteeing privacy
- Differential privacy is the gold standard for privacy, but it has limitations when it comes to sparse datasets
- The researchers propose a variation of k-anonymity called smooth-k-anonymity and design efficient algorithms to achieve it
Plain English Explanation
The researchers are working on a challenging problem: how can we share an entire dataset, like a social network, with another party without compromising people's privacy? Differential privacy is considered the best way to do this, but the researchers found that it doesn't work well for sparse datasets, like social networks.
Instead, the researchers propose a new approach called "smooth-k-anonymity." This is a variation of an existing privacy technique called k-anonymity. Basically, it ensures that each person's data is "hidden" among at least k other people's data, so it's hard to identify individuals. The researchers developed efficient algorithms to apply this smooth-k-anonymity technique to large datasets.
The key idea is to find a way to share data widely while still protecting individual privacy, even for specialized datasets that don't work well with the standard differential privacy approach.
Technical Explanation
The researchers start by proving that any differentially private mechanism that maintains a reasonable similarity with the initial sparse dataset, such as a social network, will have very weak privacy guarantees. This is a significant limitation of differential privacy for this type of data.
To address this, the researchers introduce a new privacy notion called "smooth-k-anonymity," which is a variation of the classic k-anonymity concept. They design efficient large-scale algorithms to achieve smooth-k-anonymity on sparse datasets.
The researchers then empirically evaluate their algorithms, showing that the anonymized data maintains utility for downstream machine learning tasks better than other approaches. This demonstrates the practical benefits of their smooth-k-anonymity techniques.
Critical Analysis
The researchers acknowledge that smooth-k-anonymity, like other privacy techniques, has limitations. For example, it may not provide the same strong theoretical guarantees as differential privacy in some cases. Additionally, the evaluation is performed on a limited set of datasets and tasks.
Further research is needed to fully understand the tradeoffs and limitations of smooth-k-anonymity, especially when compared to other privacy-preserving data synthesis techniques or causal discovery under local privacy. Exploring the computational complexity of private high-dimensional model selection could also yield valuable insights.
Overall, the researchers have made a compelling case for smooth-k-anonymity as a practical solution for preserving privacy in sparse datasets, but more work is needed to fully understand its strengths and weaknesses.
Conclusion
This research presents a novel approach to preserving privacy when sharing sparse datasets, such as social networks, with third parties. By introducing smooth-k-anonymity and designing efficient algorithms to achieve it, the researchers have provided a practical solution to a challenging problem.
While smooth-k-anonymity may not offer the same theoretical guarantees as differential privacy in all cases, it appears to be a useful technique for maintaining data utility while protecting individual privacy. As the field of privacy-preserving data sharing continues to evolve, this work contributes an important new tool to the researcher's toolkit.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📉
0
Smooth Anonymity for Sparse Graphs
Alessandro Epasto, Hossein Esfandiari, Vahab Mirrokni, Andres Munoz Medina
When working with user data providing well-defined privacy guarantees is paramount. In this work, we aim to manipulate and share an entire sparse dataset with a third party privately. In fact, differential privacy has emerged as the gold standard of privacy, however, when it comes to sharing sparse datasets, e.g. sparse networks, as one of our main results, we prove that emph{any} differentially private mechanism that maintains a reasonable similarity with the initial dataset is doomed to have a very weak privacy guarantee. In such situations, we need to look into other privacy notions such as $k$-anonymity. In this work, we consider a variation of $k$-anonymity, which we call smooth-$k$-anonymity, and design simple large-scale algorithms that efficiently provide smooth-$k$-anonymity. We further perform an empirical evaluation to back our theoretical guarantees and show that our algorithm improves the performance in downstream machine learning tasks on anonymized data.
Read more5/16/2024

0
Differentially Private Synthetic Data with Private Density Estimation
Nikolija Bojkovic, Po-Ling Loh
The need to analyze sensitive data, such as medical records or financial data, has created a critical research challenge in recent years. In this paper, we adopt the framework of differential privacy, and explore mechanisms for generating an entire dataset which accurately captures characteristics of the original data. We build upon the work of Boedihardjo et al, which laid the foundations for a new optimization-based algorithm for generating private synthetic data. Importantly, we adapt their algorithm by replacing a uniform sampling step with a private distribution estimator; this allows us to obtain better computational guarantees for discrete distributions, and develop a novel algorithm suitable for continuous distributions. We also explore applications of our work to several statistical tasks.
Read more5/9/2024
🔎
0
Differentially Private Densest Subgraph Detection
Dung Nguyen, Anil Vullikanti
Densest subgraph detection is a fundamental graph mining problem, with a large number of applications. There has been a lot of work on efficient algorithms for finding the densest subgraph in massive networks. However, in many domains, the network is private, and returning a densest subgraph can reveal information about the network. Differential privacy is a powerful framework to handle such settings. We study the densest subgraph problem in the edge privacy model, in which the edges of the graph are private. We present the first sequential and parallel differentially private algorithms for this problem. We show that our algorithms have an additive approximation guarantee. We evaluate our algorithms on a large number of real-world networks, and observe a good privacy-accuracy tradeoff when the network has high density.
Read more6/5/2024
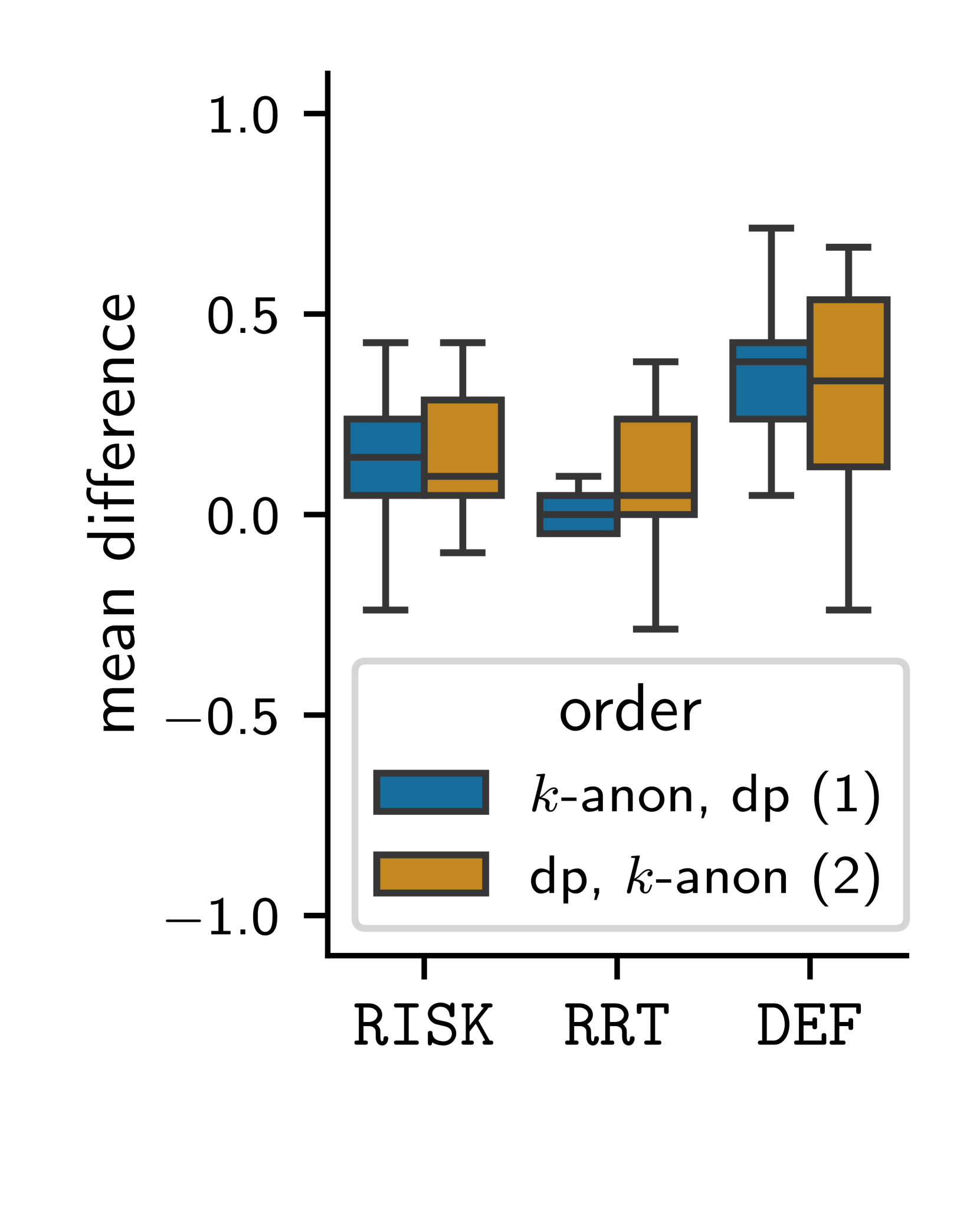
0
From Theory to Comprehension: A Comparative Study of Differential Privacy and $k$-Anonymity
Saskia Nu~nez von Voigt, Luise Mehner, Florian Tschorsch
The notion of $varepsilon$-differential privacy is a widely used concept of providing quantifiable privacy to individuals. However, it is unclear how to explain the level of privacy protection provided by a differential privacy mechanism with a set $varepsilon$. In this study, we focus on users' comprehension of the privacy protection provided by a differential privacy mechanism. To do so, we study three variants of explaining the privacy protection provided by differential privacy: (1) the original mathematical definition; (2) $varepsilon$ translated into a specific privacy risk; and (3) an explanation using the randomized response technique. We compare users' comprehension of privacy protection employing these explanatory models with their comprehension of privacy protection of $k$-anonymity as baseline comprehensibility. Our findings suggest that participants' comprehension of differential privacy protection is enhanced by the privacy risk model and the randomized response-based model. Moreover, our results confirm our intuition that privacy protection provided by $k$-anonymity is more comprehensible.
Read more4/8/2024