SMPLX-Lite: A Realistic and Drivable Avatar Benchmark with Rich Geometry and Texture Annotations
2405.19609
0
0

Abstract
Recovering photorealistic and drivable full-body avatars is crucial for numerous applications, including virtual reality, 3D games, and tele-presence. Most methods, whether reconstruction or generation, require large numbers of human motion sequences and corresponding textured meshes. To easily learn a drivable avatar, a reasonable parametric body model with unified topology is paramount. However, existing human body datasets either have images or textured models and lack parametric models which fit clothes well. We propose a new parametric model SMPLX-Lite-D, which can fit detailed geometry of the scanned mesh while maintaining stable geometry in the face, hand and foot regions. We present SMPLX-Lite dataset, the most comprehensive clothing avatar dataset with multi-view RGB sequences, keypoints annotations, textured scanned meshes, and textured SMPLX-Lite-D models. With the SMPLX-Lite dataset, we train a conditional variational autoencoder model that takes human pose and facial keypoints as input, and generates a photorealistic drivable human avatar.
Create account to get full access
Overview
- This paper introduces SMPLX-Lite, a new dataset and benchmark for realistic and drivable avatar modeling.
- SMPLX-Lite provides high-quality 3D geometry, texture, and annotation data for a diverse set of human models.
- The dataset aims to enable research on advanced avatar reconstruction, animation, and interaction technologies.
Plain English Explanation
The SMPLX-Lite dataset is a new resource for researchers working on creating realistic and interactive 3D human avatars. It contains detailed 3D models of a wide range of people, including information about their body shape, texture, and other important attributes. This data can be used to train machine learning models that can reconstruct, animate, and interact with virtual human characters in a very realistic way.
The key advantage of SMPLX-Lite is that it provides high-quality 3D data that goes beyond just the basic human body shape. It includes rich geometric details and texture information that can help make the avatars look and behave more lifelike. This can be particularly useful for applications like virtual reality, video games, and other immersive experiences where realistic human characters are important.
By making this dataset publicly available, the researchers hope to spur further advancements in avatar modeling and related technologies. The SCULPT: Shape-Conditioned Unpaired Learning for Pose-Dependent 3D Shape and SMPLER: Taming Transformers for Monocular 3D Human Shape and Pose Estimation papers have also explored related work in this area.
Technical Explanation
The SMPLX-Lite dataset builds upon the popular SMPLX model, which is a parametric 3D body model that can represent a wide range of human shapes and poses. SMPLX-Lite extends this by providing high-quality 3D meshes, textures, and detailed annotations for a diverse set of human models.
The dataset includes over 1,000 3D meshes that capture a variety of body shapes, ages, and ethnicities. Each mesh is accompanied by a detailed texture map, as well as semantic annotations for the different body parts, clothing, and other important attributes. This rich data can be used to train machine learning models that can accurately reconstruct, animate, and interact with virtual human characters.
The researchers designed SMPLX-Lite to enable research on advanced avatar modeling and interaction technologies. For example, the HR-NeRF: Human Modeling Using Neural Radiance Fields and PuzzleAvatar: Assembling 3D Avatars from Personal Photo Albums papers have explored using similar datasets for reconstructing and animating human avatars.
By providing this high-quality dataset, the researchers hope to enable researchers to develop more realistic and interactive virtual human characters for a wide range of applications, from video games and virtual reality to online communication and e-commerce.
Critical Analysis
One potential limitation of the SMPLX-Lite dataset is that it may not capture the full diversity of human body shapes and appearances. While the dataset includes a wide range of models, it is still a curated set and may not fully represent the full spectrum of human diversity.
Additionally, the dataset is focused on static 3D meshes and textures, which may limit its usefulness for research on dynamic avatar animation and interaction. Incorporating more information about body dynamics and motion would be a valuable addition to the dataset.
Finally, the researchers do not provide much detail on the process used to create the 3D models and annotations, which makes it difficult to assess the reliability and consistency of the data. More transparency around the data collection and processing methods would be helpful for evaluating the dataset's suitability for different research applications.
Overall, the SMPLX-Lite dataset represents a valuable contribution to the field of avatar modeling and interaction. However, there is still room for improvement and expansion to make it an even more useful resource for the research community.
Conclusion
The SMPLX-Lite dataset provides a new benchmark for realistic and drivable avatar modeling, with high-quality 3D geometry, texture, and annotation data for a diverse set of human models. This dataset can enable researchers to develop more advanced technologies for avatar reconstruction, animation, and interaction, with potential applications in virtual reality, video games, and other immersive experiences.
By making this dataset publicly available, the researchers hope to spur further advancements in the field of avatar modeling and related areas, building on the work of related papers like 3DGS: Avatar-Animatable 3D Geometry and Texture. However, the dataset also has some limitations, and further improvements and expansions could make it an even more valuable resource for the research community.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
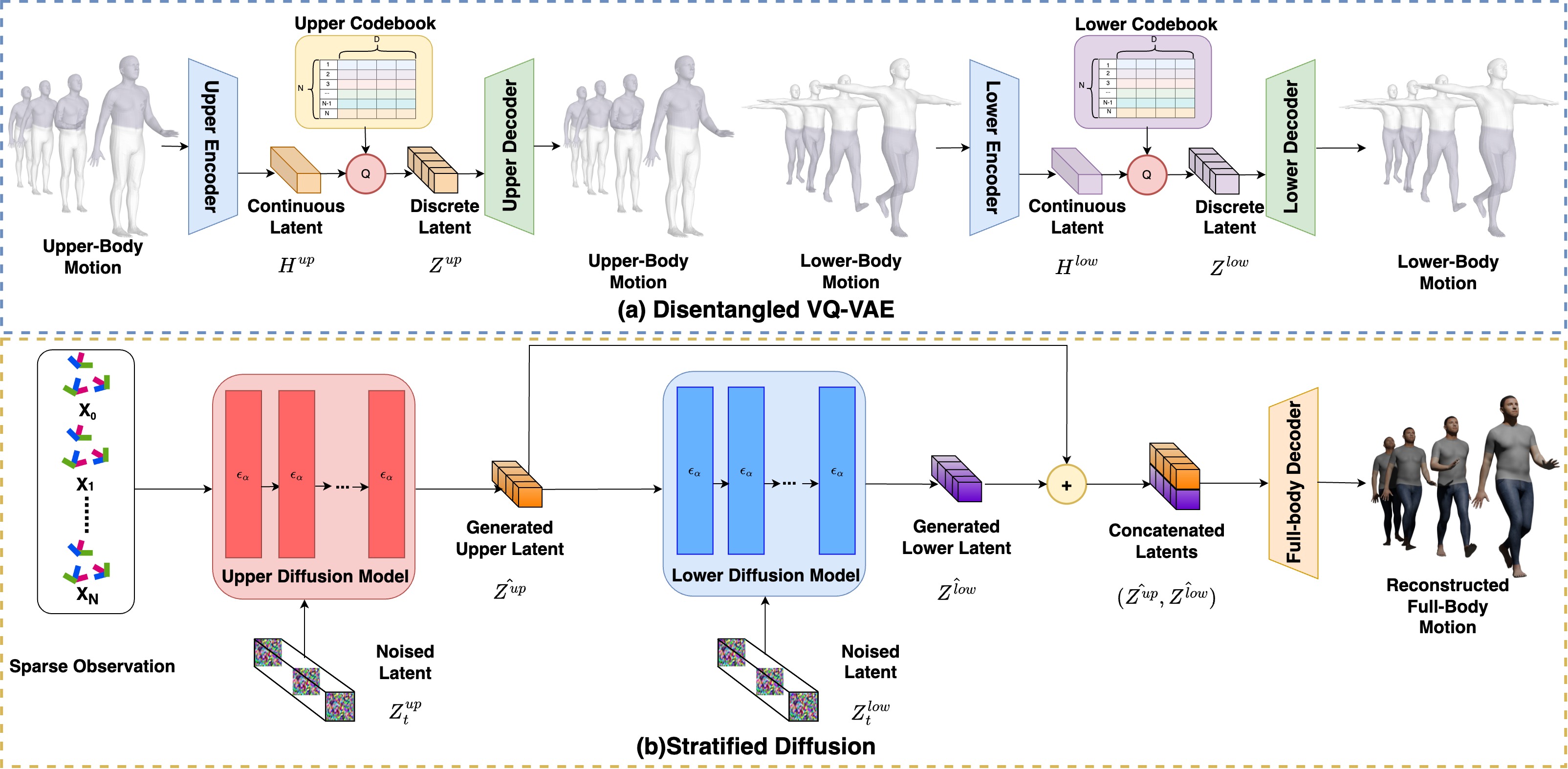
Stratified Avatar Generation from Sparse Observations
Han Feng, Wenchao Ma, Quankai Gao, Xianwei Zheng, Nan Xue, Huijuan Xu
0
0
Estimating 3D full-body avatars from AR/VR devices is essential for creating immersive experiences in AR/VR applications. This task is challenging due to the limited input from Head Mounted Devices, which capture only sparse observations from the head and hands. Predicting the full-body avatars, particularly the lower body, from these sparse observations presents significant difficulties. In this paper, we are inspired by the inherent property of the kinematic tree defined in the Skinned Multi-Person Linear (SMPL) model, where the upper body and lower body share only one common ancestor node, bringing the potential of decoupled reconstruction. We propose a stratified approach to decouple the conventional full-body avatar reconstruction pipeline into two stages, with the reconstruction of the upper body first and a subsequent reconstruction of the lower body conditioned on the previous stage. To implement this straightforward idea, we leverage the latent diffusion model as a powerful probabilistic generator, and train it to follow the latent distribution of decoupled motions explored by a VQ-VAE encoder-decoder model. Extensive experiments on AMASS mocap dataset demonstrate our state-of-the-art performance in the reconstruction of full-body motions.
6/4/2024

SMPLer: Taming Transformers for Monocular 3D Human Shape and Pose Estimation
Xiangyu Xu, Lijuan Liu, Shuicheng Yan
0
0
Existing Transformers for monocular 3D human shape and pose estimation typically have a quadratic computation and memory complexity with respect to the feature length, which hinders the exploitation of fine-grained information in high-resolution features that is beneficial for accurate reconstruction. In this work, we propose an SMPL-based Transformer framework (SMPLer) to address this issue. SMPLer incorporates two key ingredients: a decoupled attention operation and an SMPL-based target representation, which allow effective utilization of high-resolution features in the Transformer. In addition, based on these two designs, we also introduce several novel modules including a multi-scale attention and a joint-aware attention to further boost the reconstruction performance. Extensive experiments demonstrate the effectiveness of SMPLer against existing 3D human shape and pose estimation methods both quantitatively and qualitatively. Notably, the proposed algorithm achieves an MPJPE of 45.2 mm on the Human3.6M dataset, improving upon Mesh Graphormer by more than 10% with fewer than one-third of the parameters. Code and pretrained models are available at https://github.com/xuxy09/SMPLer.
4/24/2024
🔎
SCULPT: Shape-Conditioned Unpaired Learning of Pose-dependent Clothed and Textured Human Meshes
Soubhik Sanyal, Partha Ghosh, Jinlong Yang, Michael J. Black, Justus Thies, Timo Bolkart
0
0
We present SCULPT, a novel 3D generative model for clothed and textured 3D meshes of humans. Specifically, we devise a deep neural network that learns to represent the geometry and appearance distribution of clothed human bodies. Training such a model is challenging, as datasets of textured 3D meshes for humans are limited in size and accessibility. Our key observation is that there exist medium-sized 3D scan datasets like CAPE, as well as large-scale 2D image datasets of clothed humans and multiple appearances can be mapped to a single geometry. To effectively learn from the two data modalities, we propose an unpaired learning procedure for pose-dependent clothed and textured human meshes. Specifically, we learn a pose-dependent geometry space from 3D scan data. We represent this as per vertex displacements w.r.t. the SMPL model. Next, we train a geometry conditioned texture generator in an unsupervised way using the 2D image data. We use intermediate activations of the learned geometry model to condition our texture generator. To alleviate entanglement between pose and clothing type, and pose and clothing appearance, we condition both the texture and geometry generators with attribute labels such as clothing types for the geometry, and clothing colors for the texture generator. We automatically generated these conditioning labels for the 2D images based on the visual question answering model BLIP and CLIP. We validate our method on the SCULPT dataset, and compare to state-of-the-art 3D generative models for clothed human bodies. Our code and data can be found at https://sculpt.is.tue.mpg.de.
5/7/2024
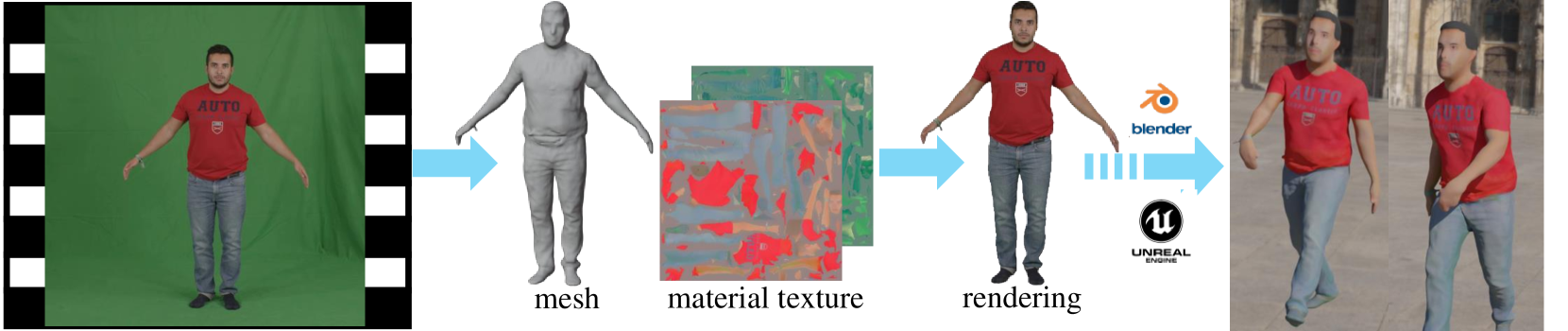
HR Human: Modeling Human Avatars with Triangular Mesh and High-Resolution Textures from Videos
Qifeng Chen, Rengan Xie, Kai Huang, Qi Wang, Wenting Zheng, Rong Li, Yuchi Huo
0
0
Recently, implicit neural representation has been widely used to generate animatable human avatars. However, the materials and geometry of those representations are coupled in the neural network and hard to edit, which hinders their application in traditional graphics engines. We present a framework for acquiring human avatars that are attached with high-resolution physically-based material textures and triangular mesh from monocular video. Our method introduces a novel information fusion strategy to combine the information from the monocular video and synthesize virtual multi-view images to tackle the sparsity of the input view. We reconstruct humans as deformable neural implicit surfaces and extract triangle mesh in a well-behaved pose as the initial mesh of the next stage. In addition, we introduce an approach to correct the bias for the boundary and size of the coarse mesh extracted. Finally, we adapt prior knowledge of the latent diffusion model at super-resolution in multi-view to distill the decomposed texture. Experiments show that our approach outperforms previous representations in terms of high fidelity, and this explicit result supports deployment on common renderers.
5/21/2024