PuzzleAvatar: Assembling 3D Avatars from Personal Albums
2405.14869
0
0
🏅
Abstract
Generating personalized 3D avatars is crucial for AR/VR. However, recent text-to-3D methods that generate avatars for celebrities or fictional characters, struggle with everyday people. Methods for faithful reconstruction typically require full-body images in controlled settings. What if a user could just upload their personal OOTD (Outfit Of The Day) photo collection and get a faithful avatar in return? The challenge is that such casual photo collections contain diverse poses, challenging viewpoints, cropped views, and occlusion (albeit with a consistent outfit, accessories and hairstyle). We address this novel Album2Human task by developing PuzzleAvatar, a novel model that generates a faithful 3D avatar (in a canonical pose) from a personal OOTD album, while bypassing the challenging estimation of body and camera pose. To this end, we fine-tune a foundational vision-language model (VLM) on such photos, encoding the appearance, identity, garments, hairstyles, and accessories of a person into (separate) learned tokens and instilling these cues into the VLM. In effect, we exploit the learned tokens as puzzle pieces from which we assemble a faithful, personalized 3D avatar. Importantly, we can customize avatars by simply inter-changing tokens. As a benchmark for this new task, we collect a new dataset, called PuzzleIOI, with 41 subjects in a total of nearly 1K OOTD configurations, in challenging partial photos with paired ground-truth 3D bodies. Evaluation shows that PuzzleAvatar not only has high reconstruction accuracy, outperforming TeCH and MVDreamBooth, but also a unique scalability to album photos, and strong robustness. Our model and data will be public.
Create account to get full access
Overview
- Generating personalized 3D avatars for augmented reality (AR) and virtual reality (VR) is crucial, but recent text-to-3D methods struggle with everyday people.
- Traditional methods for faithful reconstruction typically require full-body images in controlled settings.
- This paper introduces a novel "Album2Human" task: generating a faithful 3D avatar from a personal "Outfit of the Day" (OOTD) photo collection, which contains diverse poses, viewpoints, and occlusions.
Plain English Explanation
Creating personalized 3D avatars is important for AR and VR experiences, but current methods have difficulty with everyday people, not just celebrities or fictional characters. Typical ways to accurately recreate a 3D model of a person usually need full-body photos taken in a controlled setting.
What if you could just upload your own personal collection of outfit photos and get a realistic 3D avatar in return? The challenge is that these casual photo collections have a lot of variety, with different poses, camera angles, and parts of the body hidden. But if you have a consistent outfit, accessories, and hairstyle, this information could be used to assemble a faithful 3D model.
The researchers developed a new model called "PuzzleAvatar" that can generate a 3D avatar from a personal OOTD photo album, without needing to estimate the person's body or camera pose. It does this by fine-tuning a vision-language model to encode the appearance, identity, clothing, hairstyle, and accessories into separate learned "tokens." These tokens act like puzzle pieces that can be assembled into a personalized 3D avatar. The model can also customize the avatar by simply swapping out certain tokens.
To test this new "Album2Human" task, the researchers created a new dataset called "PuzzleIOI" with 41 people and nearly 1,000 challenging OOTD photos with paired 3D ground truth. The evaluation shows that PuzzleAvatar not only has high accuracy, outperforming other methods, but is also scalable to full photo albums and robust to the challenges in these casual photo collections.
Technical Explanation
The key innovation of this work is the "PuzzleAvatar" model, which generates a faithful 3D avatar from a personal OOTD photo collection, without requiring the estimation of body or camera pose. This is achieved by fine-tuning a foundational vision-language model (VLM) to encode the appearance, identity, garments, hairstyles, and accessories of a person into separate learned "tokens." These tokens are then assembled into a personalized 3D avatar in a canonical pose.
The researchers collect a new benchmark dataset called "PuzzleIOI," which contains 41 subjects with nearly 1,000 OOTD configurations in challenging partial photos, paired with ground-truth 3D body models. Evaluation shows that PuzzleAvatar not only achieves high reconstruction accuracy, outperforming prior methods like TeCH and MVDreamBooth, but also demonstrates strong scalability to full photo albums and robustness to the diverse poses, viewpoints, and occlusions present in these casual photo collections.
Importantly, the modular token-based representation of PuzzleAvatar allows for easy customization of the generated avatars by simply swapping out certain tokens, such as clothing or hairstyle. This flexibility enables applications like virtual try-on or personalized character creation in games and metaverse experiences.
Critical Analysis
While the PuzzleAvatar model demonstrates impressive performance on the new "Album2Human" task, there are a few potential limitations and areas for further research:
- The dataset, while comprehensive, is still relatively small, with only 41 subjects. Scaling to larger and more diverse photo collections would be an important next step.
- The model currently focuses on generating a static 3D avatar in a canonical pose. Extending the approach to enable dynamic animation and expression of the avatars could further expand its utility.
- The paper does not deeply explore the potential biases or fairness implications of the model, which is an important consideration for any AI system that generates personalized content.
Additionally, the researchers could investigate ways to further improve the token-based representation, such as exploring hierarchical or generative approaches, or integrating volumetric representations for more detailed and expressive avatars.
Overall, the PuzzleAvatar model and the new "Album2Human" task represent an exciting step forward in personalized 3D avatar generation, with promising implications for AR/VR, virtual fashion, and digital identity applications.
Conclusion
This paper introduces the novel "Album2Human" task of generating personalized 3D avatars from a user's casual "Outfit of the Day" photo collection. The researchers' PuzzleAvatar model addresses this challenge by fine-tuning a vision-language model to encode appearance, identity, and outfit details into separate learned tokens, which are then assembled into a faithful 3D avatar.
The new PuzzleIOI dataset and the strong performance of PuzzleAvatar, outpacing prior methods, demonstrate the potential of this approach. The modularity of the token-based representation also enables easy customization of the generated avatars. As AR/VR and virtual identity applications continue to grow, innovations like PuzzleAvatar could play a crucial role in empowering users to create personalized 3D representations of themselves.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Instant 3D Human Avatar Generation using Image Diffusion Models
Nikos Kolotouros, Thiemo Alldieck, Enric Corona, Eduard Gabriel Bazavan, Cristian Sminchisescu
0
0
We present AvatarPopUp, a method for fast, high quality 3D human avatar generation from different input modalities, such as images and text prompts and with control over the generated pose and shape. The common theme is the use of diffusion-based image generation networks that are specialized for each particular task, followed by a 3D lifting network. We purposefully decouple the generation from the 3D modeling which allow us to leverage powerful image synthesis priors, trained on billions of text-image pairs. We fine-tune latent diffusion networks with additional image conditioning to solve tasks such as image generation and back-view prediction, and to support qualitatively different multiple 3D hypotheses. Our partial fine-tuning approach allows to adapt the networks for each task without inducing catastrophic forgetting. In our experiments, we demonstrate that our method produces accurate, high-quality 3D avatars with diverse appearance that respect the multimodal text, image, and body control signals. Our approach can produce a 3D model in as few as 2 seconds, a four orders of magnitude speedup w.r.t. the vast majority of existing methods, most of which solve only a subset of our tasks, and with fewer controls, thus enabling applications that require the controlled 3D generation of human avatars at scale. The project website can be found at https://www.nikoskolot.com/avatarpopup/.
6/12/2024
📶
Privacy-preserving Pseudonym Schemes for Personalized 3D Avatars in Mobile Social Metaverses
Cheng Su, Xiaofeng Luo, Zhenmou Liu, Jiawen Kang, Min Hao, Zehui Xiong, Zhaohui Yang, Chongwen Huang
0
0
The emergence of mobile social metaverses, a novel paradigm bridging physical and virtual realms, has led to the widespread adoption of avatars as digital representations for Social Metaverse Users (SMUs) within virtual spaces. Equipped with immersive devices, SMUs leverage Edge Servers (ESs) to deploy their avatars and engage with other SMUs in virtual spaces. To enhance immersion, SMUs incline to opt for 3D avatars for social interactions. However, existing 3D avatars are typically generated through scanning the real faces of SMUs, which can raise concerns regarding information privacy and security, such as profile identity leakages. To tackle this, we introduce a new framework for personalized 3D avatar construction, leveraging a two-layer network model that provides SMUs with the option to customize their personal avatars for privacy preservation. Specifically, our approach introduces avatar pseudonyms to jointly safeguard the profile and digital identity privacy of the generated avatars. Then, we design a novel metric named Privacy of Personalized Avatars (PoPA), to evaluate effectiveness of the avatar pseudonyms. To optimize pseudonym resource, we model the pseudonym distribution process as a Stackelberg game and employ Deep Reinforcement Learning (DRL) to learn equilibrium strategies under incomplete information. Simulation results validate the efficacy and feasibility of our proposed schemes for mobile social metaverses.
6/18/2024
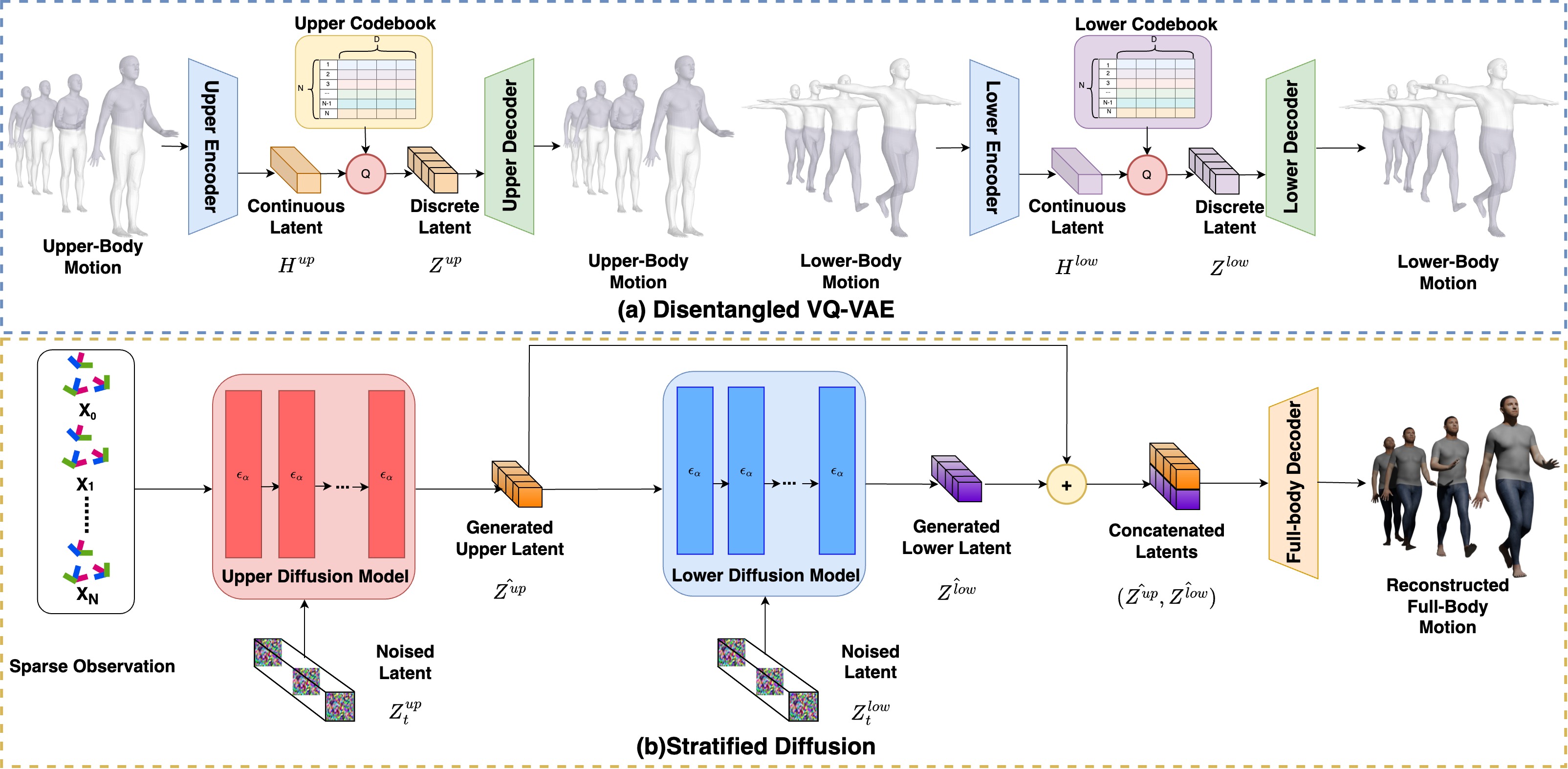
Stratified Avatar Generation from Sparse Observations
Han Feng, Wenchao Ma, Quankai Gao, Xianwei Zheng, Nan Xue, Huijuan Xu
0
0
Estimating 3D full-body avatars from AR/VR devices is essential for creating immersive experiences in AR/VR applications. This task is challenging due to the limited input from Head Mounted Devices, which capture only sparse observations from the head and hands. Predicting the full-body avatars, particularly the lower body, from these sparse observations presents significant difficulties. In this paper, we are inspired by the inherent property of the kinematic tree defined in the Skinned Multi-Person Linear (SMPL) model, where the upper body and lower body share only one common ancestor node, bringing the potential of decoupled reconstruction. We propose a stratified approach to decouple the conventional full-body avatar reconstruction pipeline into two stages, with the reconstruction of the upper body first and a subsequent reconstruction of the lower body conditioned on the previous stage. To implement this straightforward idea, we leverage the latent diffusion model as a powerful probabilistic generator, and train it to follow the latent distribution of decoupled motions explored by a VQ-VAE encoder-decoder model. Extensive experiments on AMASS mocap dataset demonstrate our state-of-the-art performance in the reconstruction of full-body motions.
6/4/2024
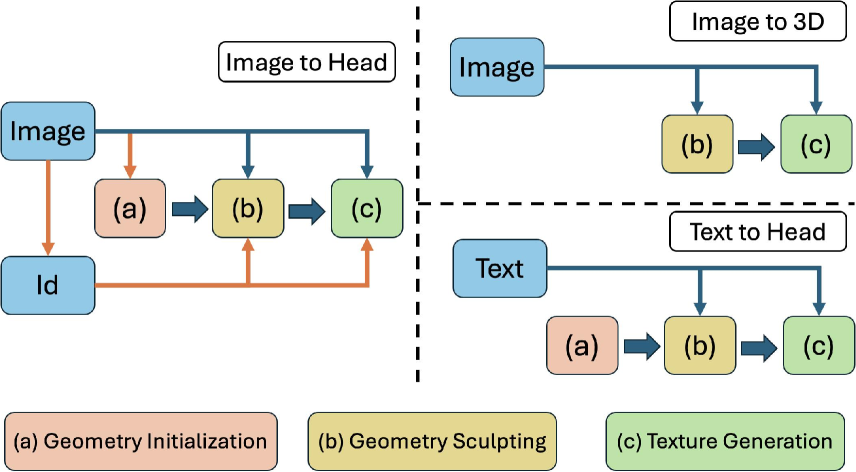
Portrait3D: 3D Head Generation from Single In-the-wild Portrait Image
Jinkun Hao, Junshu Tang, Jiangning Zhang, Ran Yi, Yijia Hong, Moran Li, Weijian Cao, Yating Wang, Lizhuang Ma
0
0
While recent works have achieved great success on one-shot 3D common object generation, high quality and fidelity 3D head generation from a single image remains a great challenge. Previous text-based methods for generating 3D heads were limited by text descriptions and image-based methods struggled to produce high-quality head geometry. To handle this challenging problem, we propose a novel framework, Portrait3D, to generate high-quality 3D heads while preserving their identities. Our work incorporates the identity information of the portrait image into three parts: 1) geometry initialization, 2) geometry sculpting, and 3) texture generation stages. Given a reference portrait image, we first align the identity features with text features to realize ID-aware guidance enhancement, which contains the control signals representing the face information. We then use the canny map, ID features of the portrait image, and a pre-trained text-to-normal/depth diffusion model to generate ID-aware geometry supervision, and 3D-GAN inversion is employed to generate ID-aware geometry initialization. Furthermore, with the ability to inject identity information into 3D head generation, we use ID-aware guidance to calculate ID-aware Score Distillation (ISD) for geometry sculpting. For texture generation, we adopt the ID Consistent Texture Inpainting and Refinement which progressively expands the view for texture inpainting to obtain an initialization UV texture map. We then use the id-aware guidance to provide image-level supervision for noisy multi-view images to obtain a refined texture map. Extensive experiments demonstrate that we can generate high-quality 3D heads with accurate geometry and texture from single in-the-wild portrait images. The project page is at https://jinkun-hao.github.io/Portrait3D/.
6/26/2024