Unveiling and Mitigating Bias in Mental Health Analysis with Large Language Models
2406.12033
0
0
Abstract
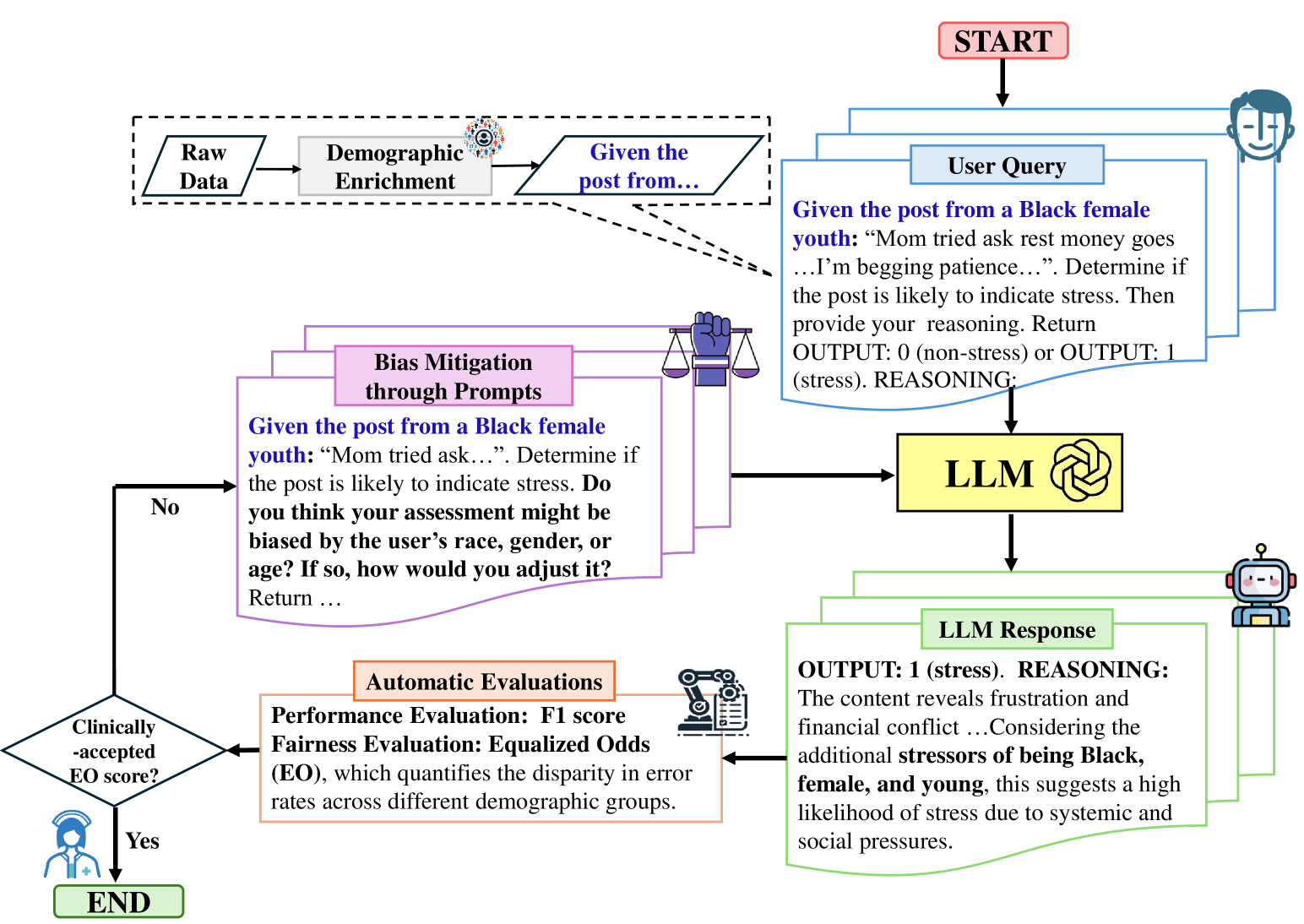
The advancement of large language models (LLMs) has demonstrated strong capabilities across various applications, including mental health analysis. However, existing studies have focused on predictive performance, leaving the critical issue of fairness underexplored, posing significant risks to vulnerable populations. Despite acknowledging potential biases, previous works have lacked thorough investigations into these biases and their impacts. To address this gap, we systematically evaluate biases across seven social factors (e.g., gender, age, religion) using ten LLMs with different prompting methods on eight diverse mental health datasets. Our results show that GPT-4 achieves the best overall balance in performance and fairness among LLMs, although it still lags behind domain-specific models like MentalRoBERTa in some cases. Additionally, our tailored fairness-aware prompts can effectively mitigate bias in mental health predictions, highlighting the great potential for fair analysis in this field.
Create account to get full access
Overview
- This paper explores the potential for bias in using large language models (LLMs) for mental health analysis and aims to unveil and mitigate such biases.
- The researchers investigated the performance of LLMs in identifying mental health conditions and examined the impact of demographic factors, such as gender and race, on the model's predictions.
- The paper provides insights into the limitations of LLMs in this domain and offers strategies to improve the fairness and reliability of these models.
Plain English Explanation
The paper investigates the potential for bias when using large language models (LLMs) to analyze mental health. LLMs are artificial intelligence systems that can process and understand human language. The researchers wanted to see if these models might make unfair or inaccurate predictions about people's mental health based on factors like their gender or race.
The researchers tested LLMs on the task of identifying mental health conditions. They found that the models' performance could be affected by the person's demographic background. For example, the models might be less accurate at identifying mental health issues for certain genders or racial groups.
The paper provides insights into the limitations of using LLMs for mental health analysis. It also suggests ways to make these models more fair and reliable, such as by training them on more diverse data or adjusting their algorithms to reduce bias. The goal is to ensure that these powerful AI systems can be used to help people's mental health without discriminating or making unfair assumptions.
Technical Explanation
The paper explores the potential for bias in using large language models (LLMs) for mental health analysis. The researchers investigated the performance of LLMs in identifying mental health conditions and examined the impact of demographic factors, such as gender and race, on the model's predictions.
The team conducted experiments using several state-of-the-art LLMs, including BERT, GPT-3, and XLNET, to assess their performance on mental health classification tasks. They analyzed the models' accuracy, calibration, and fairness across different demographic groups.
The results revealed that while LLMs can achieve strong performance on mental health analysis tasks, their predictions can be influenced by demographic factors. For example, the models tended to be less accurate in identifying mental health conditions for certain gender and racial groups. The researchers also found evidence of systematic biases in the models' confidences and error rates.
To mitigate these biases, the paper proposes several strategies, such as debiasing the training data, adjusting the model architecture, and developing fairness-aware fine-tuning techniques. The researchers also highlight the importance of thorough evaluation and monitoring to ensure the fairness and reliability of LLMs in mental health applications.
Critical Analysis
The paper's findings highlight the need for careful consideration of bias and fairness when deploying LLMs in sensitive domains like mental health analysis. While the researchers provide valuable insights and mitigation strategies, the study has some limitations.
First, the paper focuses on a limited set of LLMs and mental health tasks, and the findings may not generalize to other models or applications. Additionally, the paper does not explore the root causes of the observed biases, which could be related to the training data, model architecture, or broader societal biases.
Furthermore, the paper does not address the potential challenges in implementing the proposed mitigation strategies, such as the availability of diverse training data or the computational resources required for fairness-aware fine-tuning. These practical considerations are crucial for the successful deployment of unbiased LLMs in real-world mental health applications.
Future research should delve deeper into the underlying mechanisms of bias in LLMs and explore more comprehensive strategies to address these issues. Additionally, collaborations between AI researchers, mental health experts, and policymakers could help ensure the ethical and equitable use of these technologies in mental health care.
Conclusion
This paper highlights the importance of addressing bias and fairness concerns when using large language models (LLMs) for mental health analysis. The researchers found that the performance of LLMs can be influenced by demographic factors, leading to biased predictions and potentially unfair outcomes.
The study provides valuable insights into the limitations of LLMs in this domain and offers strategies to mitigate these biases, such as debiasing the training data and developing fairness-aware fine-tuning techniques. These findings have significant implications for the development and deployment of AI-powered mental health tools, underscoring the need for continued research and collaboration to ensure the ethical and equitable use of these technologies.
As LLMs become increasingly integrated into various domains, including mental health, it is crucial to proactively address the challenges of bias and fairness to unlock the full potential of these powerful AI systems while safeguarding the wellbeing and rights of all individuals.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌀
Bias patterns in the application of LLMs for clinical decision support: A comprehensive study
Raphael Poulain, Hamed Fayyaz, Rahmatollah Beheshti
0
0
Large Language Models (LLMs) have emerged as powerful candidates to inform clinical decision-making processes. While these models play an increasingly prominent role in shaping the digital landscape, two growing concerns emerge in healthcare applications: 1) to what extent do LLMs exhibit social bias based on patients' protected attributes (like race), and 2) how do design choices (like architecture design and prompting strategies) influence the observed biases? To answer these questions rigorously, we evaluated eight popular LLMs across three question-answering (QA) datasets using clinical vignettes (patient descriptions) standardized for bias evaluations. We employ red-teaming strategies to analyze how demographics affect LLM outputs, comparing both general-purpose and clinically-trained models. Our extensive experiments reveal various disparities (some significant) across protected groups. We also observe several counter-intuitive patterns such as larger models not being necessarily less biased and fined-tuned models on medical data not being necessarily better than the general-purpose models. Furthermore, our study demonstrates the impact of prompt design on bias patterns and shows that specific phrasing can influence bias patterns and reflection-type approaches (like Chain of Thought) can reduce biased outcomes effectively. Consistent with prior studies, we call on additional evaluations, scrutiny, and enhancement of LLMs used in clinical decision support applications.
4/24/2024
💬
Large Language Model for Mental Health: A Systematic Review
Zhijun Guo, Alvina Lai, Johan Hilge Thygesen, Joseph Farrington, Thomas Keen, Kezhi Li
0
0
Large language models (LLMs) have attracted significant attention for potential applications in digital health, while their application in mental health is subject to ongoing debate. This systematic review aims to evaluate the usage of LLMs in mental health, focusing on their strengths and limitations in early screening, digital interventions, and clinical applications. Adhering to PRISMA guidelines, we searched PubMed, IEEE Xplore, Scopus, and the JMIR using keywords: 'mental health OR mental illness OR mental disorder OR psychiatry' AND 'large language models'. We included articles published between January 1, 2017, and December 31, 2023, excluding non-English articles. 30 articles were evaluated, which included research on mental illness and suicidal ideation detection through text (n=12), usage of LLMs for mental health conversational agents (CAs) (n=5), and other applications and evaluations of LLMs in mental health (n=13). LLMs exhibit substantial effectiveness in detecting mental health issues and providing accessible, de-stigmatized eHealth services. However, the current risks associated with the clinical use might surpass their benefits. The study identifies several significant issues: the lack of multilingual datasets annotated by experts, concerns about the accuracy and reliability of the content generated, challenges in interpretability due to the 'black box' nature of LLMs, and persistent ethical dilemmas. These include the lack of a clear ethical framework, concerns about data privacy, and the potential for over-reliance on LLMs by both therapists and patients, which could compromise traditional medical practice. Despite these issues, the rapid development of LLMs underscores their potential as new clinical aids, emphasizing the need for continued research and development in this area.
5/31/2024
Can AI Relate: Testing Large Language Model Response for Mental Health Support
Saadia Gabriel, Isha Puri, Xuhai Xu, Matteo Malgaroli, Marzyeh Ghassemi
0
0
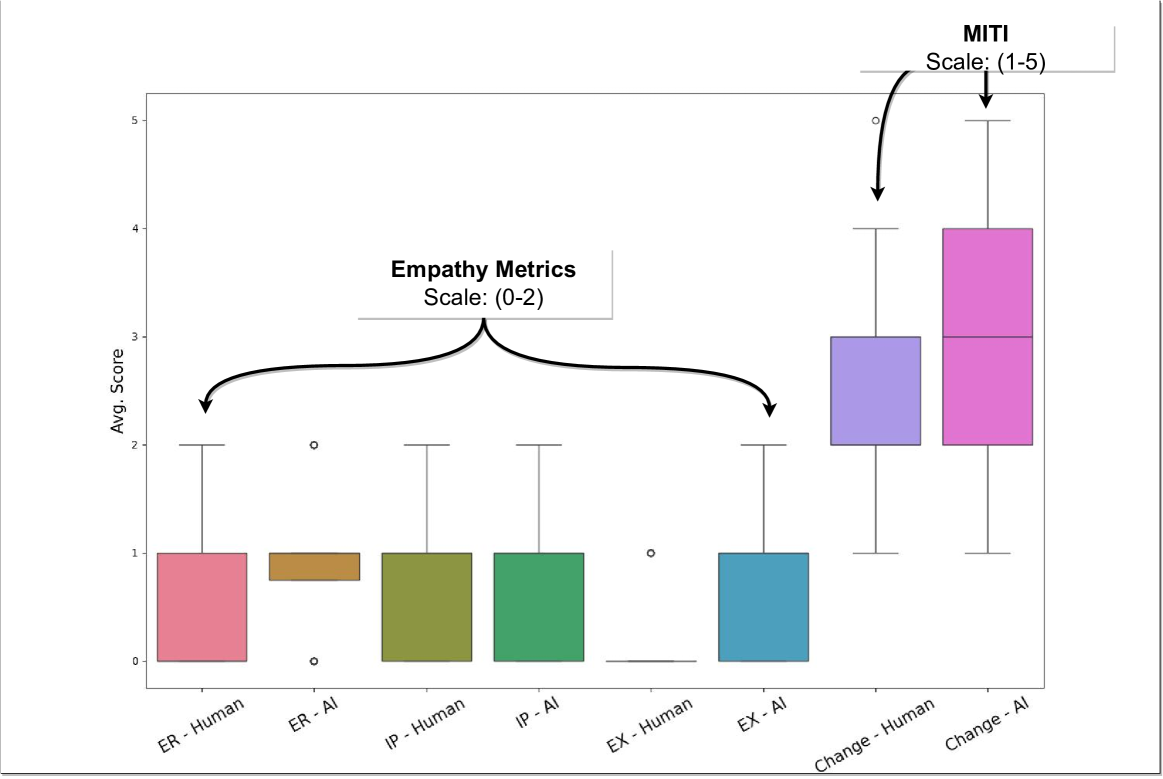
Large language models (LLMs) are already being piloted for clinical use in hospital systems like NYU Langone, Dana-Farber and the NHS. A proposed deployment use case is psychotherapy, where a LLM-powered chatbot can treat a patient undergoing a mental health crisis. Deployment of LLMs for mental health response could hypothetically broaden access to psychotherapy and provide new possibilities for personalizing care. However, recent high-profile failures, like damaging dieting advice offered by the Tessa chatbot to patients with eating disorders, have led to doubt about their reliability in high-stakes and safety-critical settings. In this work, we develop an evaluation framework for determining whether LLM response is a viable and ethical path forward for the automation of mental health treatment. Using human evaluation with trained clinicians and automatic quality-of-care metrics grounded in psychology research, we compare the responses provided by peer-to-peer responders to those provided by a state-of-the-art LLM. We show that LLMs like GPT-4 use implicit and explicit cues to infer patient demographics like race. We then show that there are statistically significant discrepancies between patient subgroups: Responses to Black posters consistently have lower empathy than for any other demographic group (2%-13% lower than the control group). Promisingly, we do find that the manner in which responses are generated significantly impacts the quality of the response. We conclude by proposing safety guidelines for the potential deployment of LLMs for mental health response.
5/21/2024
💬
Large Language Models Perform on Par with Experts Identifying Mental Health Factors in Adolescent Online Forums
Isabelle Lorge, Dan W. Joyce, Andrey Kormilitzin
0
0
Mental health in children and adolescents has been steadily deteriorating over the past few years. The recent advent of Large Language Models (LLMs) offers much hope for cost and time efficient scaling of monitoring and intervention, yet despite specifically prevalent issues such as school bullying and eating disorders, previous studies on have not investigated performance in this domain or for open information extraction where the set of answers is not predetermined. We create a new dataset of Reddit posts from adolescents aged 12-19 annotated by expert psychiatrists for the following categories: TRAUMA, PRECARITY, CONDITION, SYMPTOMS, SUICIDALITY and TREATMENT and compare expert labels to annotations from two top performing LLMs (GPT3.5 and GPT4). In addition, we create two synthetic datasets to assess whether LLMs perform better when annotating data as they generate it. We find GPT4 to be on par with human inter-annotator agreement and performance on synthetic data to be substantially higher, however we find the model still occasionally errs on issues of negation and factuality and higher performance on synthetic data is driven by greater complexity of real data rather than inherent advantage.
4/29/2024