Soda-Eval: Open-Domain Dialogue Evaluation in the age of LLMs

0

Sign in to get full access
Overview
- Soda-Eval is a new open-domain dialogue evaluation framework for assessing large language models (LLMs) on their conversational abilities.
- It introduces a novel dataset of over 10,000 diverse dialogue scenarios covering a wide range of topics.
- The framework aims to measure how well LLMs can engage in coherent, informative, and engaging conversations.
Plain English Explanation
Soda-Eval is a new system designed to evaluate the conversational skills of large language models (LLMs). LLMs are advanced AI systems that can generate human-like text on a variety of topics.
The key idea behind Soda-Eval is to create a diverse set of over 10,000 dialogue scenarios that cover a wide range of subjects, from everyday conversations to more specialized topics. These scenarios are used to assess how well an LLM can engage in coherent, informative, and engaging dialogues.
For example, a scenario might involve the LLM playing the role of a customer service representative, helping a customer troubleshoot a technical issue. Or the LLM might be asked to discuss a complex topic like the latest advances in renewable energy technology.
By evaluating LLMs on this broad range of dialogues, Soda-Eval aims to provide a comprehensive and realistic assessment of their conversational abilities. This can help researchers and developers better understand the strengths and limitations of these powerful AI systems and how they can be improved.
Technical Explanation
Soda-Eval is a new open-domain dialogue evaluation framework designed to assess the conversational abilities of large language models (LLMs). The framework introduces a novel dataset of over 10,000 diverse dialogue scenarios covering a wide range of topics, including everyday conversations, specialized discussions, and task-oriented interactions.
The dataset was created by crowdsourcing a large number of conversational prompts and then curating them to ensure diversity and quality. Each scenario consists of a conversational context and a set of instructions for the LLM to follow, such as taking on a specific role or addressing a particular topic.
To evaluate an LLM's performance, the system generates responses to the dialogue scenarios and assesses them along several dimensions, including coherence, informativeness, and engagement. The evaluation is conducted using a combination of automated metrics and human judgments, allowing for a comprehensive assessment of the LLM's conversational abilities.
Soda-Eval aims to provide a more realistic and comprehensive evaluation of LLMs compared to existing dialogue benchmarks, which often focus on specific tasks or constrained scenarios. By covering a broad range of conversational contexts, the framework can help researchers and developers better understand the strengths and limitations of these powerful AI systems and guide the development of more advanced conversational agents.
Critical Analysis
The Soda-Eval framework represents a significant step forward in the evaluation of large language models' conversational abilities. By introducing a diverse and comprehensive dataset of dialogue scenarios, the researchers have taken an important step towards more realistic and holistic assessments of LLMs.
However, the paper does acknowledge some potential limitations and areas for further research. For example, the evaluation metrics used in Soda-Eval, while comprehensive, may not fully capture all aspects of effective conversation, such as empathy, creativity, and the ability to handle unexpected situations.
Additionally, the paper notes that the dataset was created through crowdsourcing, which may introduce biases or inconsistencies that could affect the evaluation results. The researchers suggest that future work could explore alternative data collection methods or ways to address these potential biases.
Another area for further research could be the development of more advanced evaluation techniques, such as the use of human-in-the-loop assessments or the incorporation of additional modalities (e.g., voice, gestures) to more closely mimic real-world conversational interactions.
Despite these potential limitations, the Soda-Eval framework represents an important contribution to the field of dialogue evaluation and the ongoing efforts to develop more capable and engaging conversational AI systems.
Conclusion
The Soda-Eval framework introduces a novel approach to evaluating the conversational abilities of large language models. By creating a diverse dataset of over 10,000 dialogue scenarios, the researchers have taken a significant step towards more realistic and comprehensive assessments of LLMs' performance in open-domain conversations.
The framework's focus on measuring coherence, informativeness, and engagement provides a multifaceted evaluation of LLMs' conversational skills, which can help researchers and developers better understand the strengths and limitations of these powerful AI systems. As the field of conversational AI continues to evolve, frameworks like Soda-Eval will play an important role in driving the development of more advanced and capable conversational agents.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Soda-Eval: Open-Domain Dialogue Evaluation in the age of LLMs
John Mendonc{c}a, Isabel Trancoso, Alon Lavie
Although human evaluation remains the gold standard for open-domain dialogue evaluation, the growing popularity of automated evaluation using Large Language Models (LLMs) has also extended to dialogue. However, most frameworks leverage benchmarks that assess older chatbots on aspects such as fluency and relevance, which are not reflective of the challenges associated with contemporary models. In fact, a qualitative analysis on Soda, a GPT-3.5 generated dialogue dataset, suggests that current chatbots may exhibit several recurring issues related to coherence and commonsense knowledge, but generally produce highly fluent and relevant responses. Noting the aforementioned limitations, this paper introduces Soda-Eval, an annotated dataset based on Soda that covers over 120K turn-level assessments across 10K dialogues, where the annotations were generated by GPT-4. Using Soda-Eval as a benchmark, we then study the performance of several open-access instruction-tuned LLMs, finding that dialogue evaluation remains challenging. Fine-tuning these models improves performance over few-shot inferences, both in terms of correlation and explanation.
Read more8/21/2024

0
On the Benchmarking of LLMs for Open-Domain Dialogue Evaluation
John Mendonc{c}a, Alon Lavie, Isabel Trancoso
Large Language Models (LLMs) have showcased remarkable capabilities in various Natural Language Processing tasks. For automatic open-domain dialogue evaluation in particular, LLMs have been seamlessly integrated into evaluation frameworks, and together with human evaluation, compose the backbone of most evaluations. However, existing evaluation benchmarks often rely on outdated datasets and evaluate aspects like Fluency and Relevance, which fail to adequately capture the capabilities and limitations of state-of-the-art chatbot models. This paper critically examines current evaluation benchmarks, highlighting that the use of older response generators and quality aspects fail to accurately reflect modern chatbot capabilities. A small annotation experiment on a recent LLM-generated dataset (SODA) reveals that LLM evaluators such as GPT-4 struggle to detect actual deficiencies in dialogues generated by current LLM chatbots.
Read more7/8/2024
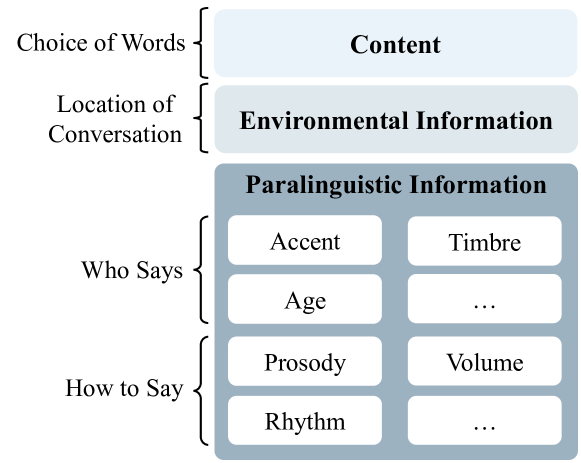
0
SD-Eval: A Benchmark Dataset for Spoken Dialogue Understanding Beyond Words
Junyi Ao, Yuancheng Wang, Xiaohai Tian, Dekun Chen, Jun Zhang, Lu Lu, Yuxuan Wang, Haizhou Li, Zhizheng Wu
Speech encompasses a wealth of information, including but not limited to content, paralinguistic, and environmental information. This comprehensive nature of speech significantly impacts communication and is crucial for human-computer interaction. Chat-Oriented Large Language Models (LLMs), known for their general-purpose assistance capabilities, have evolved to handle multi-modal inputs, including speech. Although these models can be adept at recognizing and analyzing speech, they often fall short of generating appropriate responses. We argue that this is due to the lack of principles on task definition and model development, which requires open-source datasets and metrics suitable for model evaluation. To bridge the gap, we present SD-Eval, a benchmark dataset aimed at multidimensional evaluation of spoken dialogue understanding and generation. SD-Eval focuses on paralinguistic and environmental information and includes 7,303 utterances, amounting to 8.76 hours of speech data. The data is aggregated from eight public datasets, representing four perspectives: emotion, accent, age, and background sound. To assess the SD-Eval benchmark dataset, we implement three different models and construct a training set following a similar process as SD-Eval. The training set contains 1,052.72 hours of speech data and 724.4k utterances. We also conduct a comprehensive evaluation using objective evaluation methods (e.g. BLEU and ROUGE), subjective evaluations and LLM-based metrics for the generated responses. Models conditioned with paralinguistic and environmental information outperform their counterparts in both objective and subjective measures. Moreover, experiments demonstrate LLM-based metrics show a higher correlation with human evaluation compared to traditional metrics. We open-source SD-Eval at https://github.com/amphionspace/SD-Eval.
Read more6/21/2024
📉
0
DialogBench: Evaluating LLMs as Human-like Dialogue Systems
Jiao Ou, Junda Lu, Che Liu, Yihong Tang, Fuzheng Zhang, Di Zhang, Kun Gai
Large language models (LLMs) have achieved remarkable breakthroughs in new dialogue capabilities by leveraging instruction tuning, which refreshes human impressions of dialogue systems. The long-standing goal of dialogue systems is to be human-like enough to establish long-term connections with users. Therefore, there has been an urgent need to evaluate LLMs as human-like dialogue systems. In this paper, we propose DialogBench, a dialogue evaluation benchmark that contains 12 dialogue tasks to probe the capabilities of LLMs as human-like dialogue systems should have. Specifically, we prompt GPT-4 to generate evaluation instances for each task. We first design the basic prompt based on widely used design principles and further mitigate the existing biases to generate higher-quality evaluation instances. Our extensive tests on English and Chinese DialogBench of 26 LLMs show that instruction tuning improves the human likeness of LLMs to a certain extent, but most LLMs still have much room for improvement as human-like dialogue systems. Interestingly, results also show that the positioning of assistant AI can make instruction tuning weaken the human emotional perception of LLMs and their mastery of information about human daily life.
Read more4/1/2024