SD-Eval: A Benchmark Dataset for Spoken Dialogue Understanding Beyond Words

0
Sign in to get full access
Overview
• This paper introduces a new benchmark dataset called SD-Eval, which is designed to evaluate spoken dialogue understanding beyond just the words spoken.
• The dataset includes audio recordings of natural conversations, along with annotations for various paralinguistic and non-verbal aspects of the dialogue, such as emotional state, turn-taking, and conversational flow.
• The authors present baseline results using state-of-the-art machine learning models, and discuss the potential applications and limitations of the dataset.
Plain English Explanation
The researchers created a new dataset called SD-Eval that contains recordings of real conversations. In addition to the words spoken, the dataset also includes annotations describing other important aspects of the dialogue, like the speakers' emotions, how they take turns talking, and the overall flow of the conversation.
This is valuable because current language models focus mainly on the literal words, but human communication involves much more than just the words themselves. The SD-Eval dataset provides a way to evaluate how well AI systems can understand the full context and meaning of a conversation, beyond just the individual words.
The researchers tested some of the latest machine learning models on the SD-Eval dataset to establish baseline performance. They also discussed how this dataset could be used to advance the field of conversational AI, as well as some of the limitations and challenges involved.
Technical Explanation
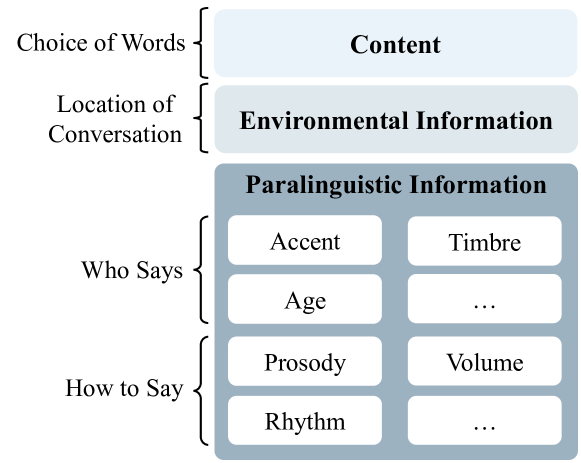
The SD-Eval dataset contains audio recordings of spontaneous, multi-turn dialogues between two or more speakers. In addition to the audio, the dataset includes annotations for various paralinguistic and non-verbal aspects of the conversations, such as:
- Emotional state (e.g. happy, sad, angry)
- Conversational flow (e.g. interruptions, backchannels, overlaps)
- Turn-taking dynamics
- Conversational functions (e.g. questions, statements, acknowledgments)
The authors present baseline results using state-of-the-art speech recognition, emotion recognition, and dialogue act classification models. These experiments demonstrate that while current models perform reasonably well on some tasks, there is significant room for improvement in understanding the full richness of human conversation.
The SD-Eval dataset is designed to spur further research in audio-dialogues-dialogues-dataset-audio-music-understanding, ears-anechoic-fullband-speech-dataset-benchmarked-speech, investigating-low-cost-llm-annotation-forspoken-dialogue, dasb-discrete-audio-speech-benchmark, and disfluencyspeech-single-speaker-conversational-speech-dataset-paralanguage understanding.
Critical Analysis
The SD-Eval dataset represents an important step forward in benchmarking spoken dialogue understanding, but it also has some limitations. The dataset is relatively small, with only around 60 dialogues, which may not be sufficient to fully capture the diversity of real-world conversations.
Additionally, the annotations, while extensive, were performed manually and may contain subjective biases. Automating the annotation process, or developing more objective metrics, could help improve the reliability and scalability of the dataset.
The baseline models presented in the paper also have room for improvement. While they demonstrate reasonable performance on some tasks, they still struggle to capture the full richness and nuance of human dialogue. Developing more sophisticated models that can better integrate multimodal signals and contextual information will be an important area for future research.
Conclusion
The SD-Eval dataset provides a valuable new resource for advancing the field of spoken dialogue understanding. By moving beyond a narrow focus on word-level processing, the dataset encourages researchers to develop AI systems that can better comprehend the full context and meaning of human conversations.
While the dataset has some limitations, it represents an important step forward and could spur significant progress in audio-dialogues-dialogues-dataset-audio-music-understanding, ears-anechoic-fullband-speech-dataset-benchmarked-speech, investigating-low-cost-llm-annotation-forspoken-dialogue, dasb-discrete-audio-speech-benchmark, and disfluencyspeech-single-speaker-conversational-speech-dataset-paralanguage over the coming years. By better understanding the nuances of human communication, we can develop AI systems that are more natural, intuitive, and effective in their interactions with people.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SD-Eval: A Benchmark Dataset for Spoken Dialogue Understanding Beyond Words
Junyi Ao, Yuancheng Wang, Xiaohai Tian, Dekun Chen, Jun Zhang, Lu Lu, Yuxuan Wang, Haizhou Li, Zhizheng Wu
Speech encompasses a wealth of information, including but not limited to content, paralinguistic, and environmental information. This comprehensive nature of speech significantly impacts communication and is crucial for human-computer interaction. Chat-Oriented Large Language Models (LLMs), known for their general-purpose assistance capabilities, have evolved to handle multi-modal inputs, including speech. Although these models can be adept at recognizing and analyzing speech, they often fall short of generating appropriate responses. We argue that this is due to the lack of principles on task definition and model development, which requires open-source datasets and metrics suitable for model evaluation. To bridge the gap, we present SD-Eval, a benchmark dataset aimed at multidimensional evaluation of spoken dialogue understanding and generation. SD-Eval focuses on paralinguistic and environmental information and includes 7,303 utterances, amounting to 8.76 hours of speech data. The data is aggregated from eight public datasets, representing four perspectives: emotion, accent, age, and background sound. To assess the SD-Eval benchmark dataset, we implement three different models and construct a training set following a similar process as SD-Eval. The training set contains 1,052.72 hours of speech data and 724.4k utterances. We also conduct a comprehensive evaluation using objective evaluation methods (e.g. BLEU and ROUGE), subjective evaluations and LLM-based metrics for the generated responses. Models conditioned with paralinguistic and environmental information outperform their counterparts in both objective and subjective measures. Moreover, experiments demonstrate LLM-based metrics show a higher correlation with human evaluation compared to traditional metrics. We open-source SD-Eval at https://github.com/amphionspace/SD-Eval.
Read more6/21/2024

0
Soda-Eval: Open-Domain Dialogue Evaluation in the age of LLMs
John Mendonc{c}a, Isabel Trancoso, Alon Lavie
Although human evaluation remains the gold standard for open-domain dialogue evaluation, the growing popularity of automated evaluation using Large Language Models (LLMs) has also extended to dialogue. However, most frameworks leverage benchmarks that assess older chatbots on aspects such as fluency and relevance, which are not reflective of the challenges associated with contemporary models. In fact, a qualitative analysis on Soda, a GPT-3.5 generated dialogue dataset, suggests that current chatbots may exhibit several recurring issues related to coherence and commonsense knowledge, but generally produce highly fluent and relevant responses. Noting the aforementioned limitations, this paper introduces Soda-Eval, an annotated dataset based on Soda that covers over 120K turn-level assessments across 10K dialogues, where the annotations were generated by GPT-4. Using Soda-Eval as a benchmark, we then study the performance of several open-access instruction-tuned LLMs, finding that dialogue evaluation remains challenging. Fine-tuning these models improves performance over few-shot inferences, both in terms of correlation and explanation.
Read more8/21/2024
0
A Suite for Acoustic Language Model Evaluation
Gallil Maimon, Amit Roth, Yossi Adi
Speech language models have recently demonstrated great potential as universal speech processing systems. Such models have the ability to model the rich acoustic information existing in audio signals, beyond spoken content, such as emotion, background noise, etc. Despite this, evaluation benchmarks which evaluate awareness to a wide range of acoustic aspects, are lacking. To help bridge this gap, we introduce SALMon, a novel evaluation suite encompassing background noise, emotion, speaker identity and room impulse response. The proposed benchmarks both evaluate the consistency of the inspected element and how much it matches the spoken text. We follow a modelling based approach, measuring whether a model gives correct samples higher scores than incorrect ones. This approach makes the benchmark fast to compute even for large models. We evaluated several speech language models on SALMon, thus highlighting the strengths and weaknesses of each evaluated method. Code and data are publicly available at https://pages.cs.huji.ac.il/adiyoss-lab/salmon/ .
Read more9/12/2024
💬
0
Integrating Paralinguistics in Speech-Empowered Large Language Models for Natural Conversation
Heeseung Kim, Soonshin Seo, Kyeongseok Jeong, Ohsung Kwon, Soyoon Kim, Jungwhan Kim, Jaehong Lee, Eunwoo Song, Myungwoo Oh, Jung-Woo Ha, Sungroh Yoon, Kang Min Yoo
Recent work shows promising results in expanding the capabilities of large language models (LLM) to directly understand and synthesize speech. However, an LLM-based strategy for modeling spoken dialogs remains elusive, calling for further investigation. This paper introduces an extensive speech-text LLM framework, the Unified Spoken Dialog Model (USDM), designed to generate coherent spoken responses with naturally occurring prosodic features relevant to the given input speech without relying on explicit automatic speech recognition (ASR) or text-to-speech (TTS) systems. We have verified the inclusion of prosody in speech tokens that predominantly contain semantic information and have used this foundation to construct a prosody-infused speech-text model. Additionally, we propose a generalized speech-text pretraining scheme that enhances the capture of cross-modal semantics. To construct USDM, we fine-tune our speech-text model on spoken dialog data using a multi-step spoken dialog template that stimulates the chain-of-reasoning capabilities exhibited by the underlying LLM. Automatic and human evaluations on the DailyTalk dataset demonstrate that our approach effectively generates natural-sounding spoken responses, surpassing previous and cascaded baselines. We will make our code and checkpoints publicly available.
Read more8/28/2024