Solving Motion Planning Tasks with a Scalable Generative Model

0

Sign in to get full access
Overview
- This paper presents a scalable generative model for solving motion planning tasks, such as those encountered in autonomous driving applications.
- The model is designed to be efficient and adaptable, allowing it to handle a wide range of motion planning scenarios.
- The authors demonstrate the effectiveness of their approach through a series of experiments, showcasing its ability to generate realistic and feasible motion plans.
Plain English Explanation
In this paper, the researchers have developed a new type of AI model that can help with motion planning tasks, which are crucial for autonomous vehicles and other robotic systems. The model is designed to be scalable, meaning it can handle a wide variety of motion planning scenarios without becoming too complex or slow.
The key idea behind the model is to use a generative approach, which means the model can create new, realistic-looking motion plans from scratch, rather than just selecting from a pre-defined set of options. This allows the model to be more flexible and adaptable to different situations.
The researchers tested their model on a range of motion planning tasks, and found that it was able to generate high-quality plans that were both feasible and realistic. This suggests the model could be very useful for applications like autonomous driving, multi-agent simulations, and end-to-end autonomous driving systems.
Overall, this research represents an important step towards more general-purpose motion planning for autonomous vehicles, which could help make self-driving cars and other robotic systems more capable and reliable. The model's scalability and adaptability also suggest it could generalize to a wide range of realistic scenarios.
Technical Explanation
The researchers' approach is based on a generative model that can produce diverse and feasible motion plans for a variety of tasks. The model uses a hierarchical architecture that allows it to efficiently capture the complex structure of motion planning problems.
At the core of the model is a variational autoencoder (VAE), which is trained to learn a compact, low-dimensional representation of feasible motion plans. This learned representation can then be used to quickly generate new motion plans by sampling from the VAE's latent space.
To make the model more scalable, the researchers also incorporate a modular design, where different components of the motion planning problem (such as obstacles, dynamics, and task constraints) are handled by separate sub-models. This allows the overall system to be more efficient and adaptable to different scenarios.
The researchers evaluate their model on a range of motion planning benchmarks, including both simulated and real-world environments. They demonstrate that their approach can generate motion plans that are collision-free, dynamically feasible, and aligned with the task objectives. Importantly, the model is able to maintain this level of performance even as the complexity of the planning problems increases.
Critical Analysis
One potential limitation of the presented approach is that it relies on a pre-defined set of task constraints and environment models. While the modular design allows the system to be more flexible, it may still struggle to generalize to completely novel or unexpected scenarios.
Additionally, the researchers only evaluate their model on relatively simple motion planning tasks, such as navigation in static environments. It's unclear how well the approach would scale to more complex, dynamic, and uncertain environments, which are commonly encountered in real-world applications like autonomous driving.
Further research would be needed to investigate the robustness and safety of the generated motion plans, especially when deployed in real-world settings. Careful analysis of edge cases and failure modes would be crucial to ensure the reliability and trustworthiness of the system.
Finally, the paper does not provide much insight into the training process and computational resources required to learn the generative model. This information would be important for understanding the practical feasibility and scalability of the approach, particularly for large-scale or resource-constrained applications.
Conclusion
The researchers have presented a promising approach for solving motion planning tasks using a scalable generative model. By leveraging a hierarchical and modular architecture, the model is able to efficiently capture the complex structure of motion planning problems and generate diverse, feasible plans.
The results demonstrate the potential of this approach for applications like autonomous driving, where the ability to quickly adapt to changing environments and task constraints is crucial. However, further research is needed to fully understand the limitations and real-world performance of the system.
Overall, this work represents an important step towards more general-purpose and adaptable motion planning solutions, which could have a significant impact on the development of autonomous systems and robotics.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Solving Motion Planning Tasks with a Scalable Generative Model
Yihan Hu, Siqi Chai, Zhening Yang, Jingyu Qian, Kun Li, Wenxin Shao, Haichao Zhang, Wei Xu, Qiang Liu
As autonomous driving systems being deployed to millions of vehicles, there is a pressing need of improving the system's scalability, safety and reducing the engineering cost. A realistic, scalable, and practical simulator of the driving world is highly desired. In this paper, we present an efficient solution based on generative models which learns the dynamics of the driving scenes. With this model, we can not only simulate the diverse futures of a given driving scenario but also generate a variety of driving scenarios conditioned on various prompts. Our innovative design allows the model to operate in both full-Autoregressive and partial-Autoregressive modes, significantly improving inference and training speed without sacrificing generative capability. This efficiency makes it ideal for being used as an online reactive environment for reinforcement learning, an evaluator for planning policies, and a high-fidelity simulator for testing. We evaluated our model against two real-world datasets: the Waymo motion dataset and the nuPlan dataset. On the simulation realism and scene generation benchmark, our model achieves the state-of-the-art performance. And in the planning benchmarks, our planner outperforms the prior arts. We conclude that the proposed generative model may serve as a foundation for a variety of motion planning tasks, including data generation, simulation, planning, and online training. Source code is public at https://github.com/HorizonRobotics/GUMP/
Read more7/4/2024

0
Planning with Adaptive World Models for Autonomous Driving
Arun Balajee Vasudevan, Neehar Peri, Jeff Schneider, Deva Ramanan
Motion planning is crucial for safe navigation in complex urban environments. Historically, motion planners (MPs) have been evaluated with procedurally-generated simulators like CARLA. However, such synthetic benchmarks do not capture real-world multi-agent interactions. nuPlan, a recently released MP benchmark, addresses this limitation by augmenting real-world driving logs with closed-loop simulation logic, effectively turning the fixed dataset into a reactive simulator. We analyze the characteristics of nuPlan's recorded logs and find that each city has its own unique driving behaviors, suggesting that robust planners must adapt to different environments. We learn to model such unique behaviors with BehaviorNet, a graph convolutional neural network (GCNN) that predicts reactive agent behaviors using features derived from recently-observed agent histories; intuitively, some aggressive agents may tailgate lead vehicles, while others may not. To model such phenomena, BehaviorNet predicts parameters of an agent's motion controller rather than predicting its spacetime trajectory (as most forecasters do). Finally, we present AdaptiveDriver, a model-predictive control (MPC) based planner that unrolls different world models conditioned on BehaviorNet's predictions. Our extensive experiments demonstrate that AdaptiveDriver achieves state-of-the-art results on the nuPlan closed-loop planning benchmark, reducing test error from 6.4% to 4.6%, even when applied to never-before-seen cities.
Read more6/18/2024
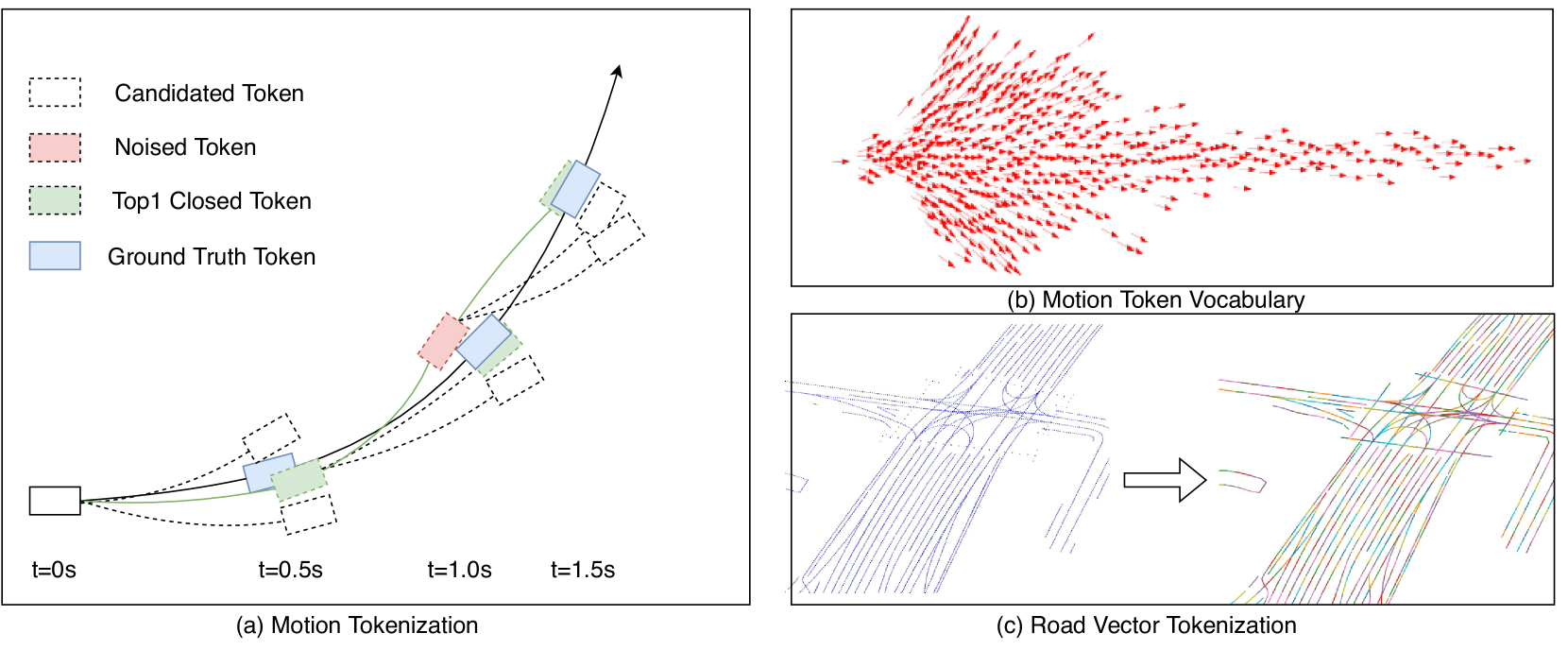
0
SMART: Scalable Multi-agent Real-time Simulation via Next-token Prediction
Wei Wu, Xiaoxin Feng, Ziyan Gao, Yuheng Kan
Data-driven autonomous driving motion generation tasks are frequently impacted by the limitations of dataset size and the domain gap between datasets, which precludes their extensive application in real-world scenarios. To address this issue, we introduce SMART, a novel autonomous driving motion generation paradigm that models vectorized map and agent trajectory data into discrete sequence tokens. These tokens are then processed through a decoder-only transformer architecture to train for the next token prediction task across spatial-temporal series. This GPT-style method allows the model to learn the motion distribution in real driving scenarios. SMART achieves state-of-the-art performance across most of the metrics on the generative Sim Agents challenge, ranking 1st on the leaderboards of Waymo Open Motion Dataset (WOMD), demonstrating remarkable inference speed. Moreover, SMART represents the generative model in the autonomous driving motion domain, exhibiting zero-shot generalization capabilities: Using only the NuPlan dataset for training and WOMD for validation, SMART achieved a competitive score of 0.71 on the Sim Agents challenge. Lastly, we have collected over 1 billion motion tokens from multiple datasets, validating the model's scalability. These results suggest that SMART has initially emulated two important properties: scalability and zero-shot generalization, and preliminarily meets the needs of large-scale real-time simulation applications. We have released all the code to promote the exploration of models for motion generation in the autonomous driving field.
Read more5/27/2024

0
GenAD: Generative End-to-End Autonomous Driving
Wenzhao Zheng, Ruiqi Song, Xianda Guo, Chenming Zhang, Long Chen
Directly producing planning results from raw sensors has been a long-desired solution for autonomous driving and has attracted increasing attention recently. Most existing end-to-end autonomous driving methods factorize this problem into perception, motion prediction, and planning. However, we argue that the conventional progressive pipeline still cannot comprehensively model the entire traffic evolution process, e.g., the future interaction between the ego car and other traffic participants and the structural trajectory prior. In this paper, we explore a new paradigm for end-to-end autonomous driving, where the key is to predict how the ego car and the surroundings evolve given past scenes. We propose GenAD, a generative framework that casts autonomous driving into a generative modeling problem. We propose an instance-centric scene tokenizer that first transforms the surrounding scenes into map-aware instance tokens. We then employ a variational autoencoder to learn the future trajectory distribution in a structural latent space for trajectory prior modeling. We further adopt a temporal model to capture the agent and ego movements in the latent space to generate more effective future trajectories. GenAD finally simultaneously performs motion prediction and planning by sampling distributions in the learned structural latent space conditioned on the instance tokens and using the learned temporal model to generate futures. Extensive experiments on the widely used nuScenes benchmark show that the proposed GenAD achieves state-of-the-art performance on vision-centric end-to-end autonomous driving with high efficiency. Code: https://github.com/wzzheng/GenAD.
Read more4/9/2024