SONICS: Synthetic Or Not -- Identifying Counterfeit Songs

0

Sign in to get full access
Overview
- This paper presents SONICS, a system for identifying counterfeit songs by detecting if they are synthesized or not.
- SONICS uses deep learning models to analyze audio features and classify songs as either real or synthetic.
- The goal is to help combat the growing problem of audio deepfakes and music piracy.
Plain English Explanation
The paper discusses a system called SONICS that can detect if a song is real or artificially created (synthesized). This is important because there is an increasing problem with "audio deepfakes" - fake audio that is made to sound like real people or music.
SONICS uses advanced machine learning techniques to analyze the audio features of a song and determine if it was actually performed by real musicians or if it was generated by a computer. This can help identify counterfeit or pirated music, which is valuable for the music industry and consumers.
The system is designed to be accurate and efficient, so it can be used to quickly screen large catalogs of music. This could be helpful for music platforms, record labels, and others who need to validate the authenticity of songs.
Technical Explanation
The core of SONICS is a deep learning model that extracts various audio features from song recordings, such as spectral characteristics, temporal patterns, and harmonic information. These features are then fed into a classifier that determines whether the song is real or synthesized.
The researchers experimented with different neural network architectures and training approaches to optimize the model's performance. This included techniques like transfer learning and few-shot learning to improve the system's ability to identify synthetic songs, even with limited training data.
Overall, the SONICS system demonstrated high accuracy in distinguishing real songs from those that were artificially generated. The authors believe it could be a valuable tool for combating audio deepfakes and protecting the integrity of the music industry.
Critical Analysis
The paper provides a thorough technical explanation of the SONICS system and its underlying methodology. However, the authors do acknowledge some limitations and areas for further research.
For example, the system was primarily evaluated on a specific dataset of synthesized songs, so its performance on a broader range of real-world audio deepfakes is still uncertain. Additionally, the researchers note that the model's effectiveness may degrade over time as synthesis techniques continue to improve.
It would also be useful to better understand the model's failure modes and the types of synthetic audio it struggles to identify. This could help guide future improvements to the system and address any potential vulnerabilities.
Overall, the SONICS research represents a promising step forward in the fight against audio deepfakes, but more work is likely needed to make it a truly robust and comprehensive solution.
Conclusion
This paper introduces SONICS, a deep learning-based system for detecting whether a song is real or synthesized. The goal is to help combat the growing problem of audio deepfakes and music piracy by providing a reliable way to verify the authenticity of songs.
The SONICS system demonstrated high accuracy in distinguishing real and synthetic audio, suggesting it could be a valuable tool for the music industry and others who need to ensure the integrity of audio content. However, the authors acknowledge some limitations and areas for further research to improve the system's robustness and adaptability over time.
Overall, the SONICS paper represents an important contribution to the field of audio deepfake detection, and the techniques it explores could have broader applications in media authentication and digital content verification.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SONICS: Synthetic Or Not -- Identifying Counterfeit Songs
Md Awsafur Rahman, Zaber Ibn Abdul Hakim, Najibul Haque Sarker, Bishmoy Paul, Shaikh Anowarul Fattah
The recent surge in AI-generated songs presents exciting possibilities and challenges. While these tools democratize music creation, they also necessitate the ability to distinguish between human-composed and AI-generated songs for safeguarding artistic integrity and content curation. Existing research and datasets in fake song detection only focus on singing voice deepfake detection (SVDD), where the vocals are AI-generated but the instrumental music is sourced from real songs. However, this approach is inadequate for contemporary end-to-end AI-generated songs where all components (vocals, lyrics, music, and style) could be AI-generated. Additionally, existing datasets lack lyrics-music diversity, long-duration songs, and open fake songs. To address these gaps, we introduce SONICS, a novel dataset for end-to-end Synthetic Song Detection (SSD), comprising over 97k songs with over 49k synthetic songs from popular platforms like Suno and Udio. Furthermore, we highlight the importance of modeling long-range temporal dependencies in songs for effective authenticity detection, an aspect overlooked in existing methods. To capture these patterns, we propose a novel model, SpecTTTra, that is up to 3 times faster and 6 times more memory efficient compared to popular CNN and Transformer-based models while maintaining competitive performance. Finally, we offer both AI-based and Human evaluation benchmarks, addressing another deficiency in current research.
Read more8/28/2024
🤯
0
Detecting Synthetic Lyrics with Few-Shot Inference
Yanis Labrak, Gabriel Meseguer-Brocal, Elena V. Epure
In recent years, generated content in music has gained significant popularity, with large language models being effectively utilized to produce human-like lyrics in various styles, themes, and linguistic structures. This technological advancement supports artists in their creative processes but also raises issues of authorship infringement, consumer satisfaction and content spamming. To address these challenges, methods for detecting generated lyrics are necessary. However, existing works have not yet focused on this specific modality or on creative text in general regarding machine-generated content detection methods and datasets. In response, we have curated the first dataset of high-quality synthetic lyrics and conducted a comprehensive quantitative evaluation of various few-shot content detection approaches, testing their generalization capabilities and complementing this with a human evaluation. Our best few-shot detector, based on LLM2Vec, surpasses stylistic and statistical methods, which are shown competitive in other domains at distinguishing human-written from machine-generated content. It also shows good generalization capabilities to new artists and models, and effectively detects post-generation paraphrasing. This study emphasizes the need for further research on creative content detection, particularly in terms of generalization and scalability with larger song catalogs. All datasets, pre-processing scripts, and code are available publicly on GitHub and Hugging Face under the Apache 2.0 license.
Read more6/24/2024
0
Detecting music deepfakes is easy but actually hard
Darius Afchar, Gabriel Meseguer-Brocal, Romain Hennequin
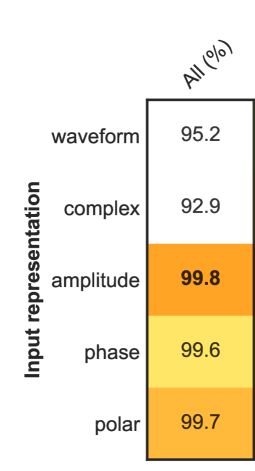
In the face of a new era of generative models, the detection of artificially generated content has become a matter of utmost importance. The ability to create credible minute-long music deepfakes in a few seconds on user-friendly platforms poses a real threat of fraud on streaming services and unfair competition to human artists. This paper demonstrates the possibility (and surprising ease) of training classifiers on datasets comprising real audio and fake reconstructions, achieving a convincing accuracy of 99.8%. To our knowledge, this marks the first publication of a music deepfake detector, a tool that will help in the regulation of music forgery. Nevertheless, informed by decades of literature on forgery detection in other fields, we stress that a good test score is not the end of the story. We step back from the straightforward ML framework and expose many facets that could be problematic with such a deployed detector: calibration, robustness to audio manipulation, generalisation to unseen models, interpretability and possibility for recourse. This second part acts as a position for future research steps in the field and a caveat to a flourishing market of fake content checkers.
Read more5/24/2024
0
From Real to Cloned Singer Identification
Dorian Desblancs, Gabriel Meseguer-Brocal, Romain Hennequin, Manuel Moussallam
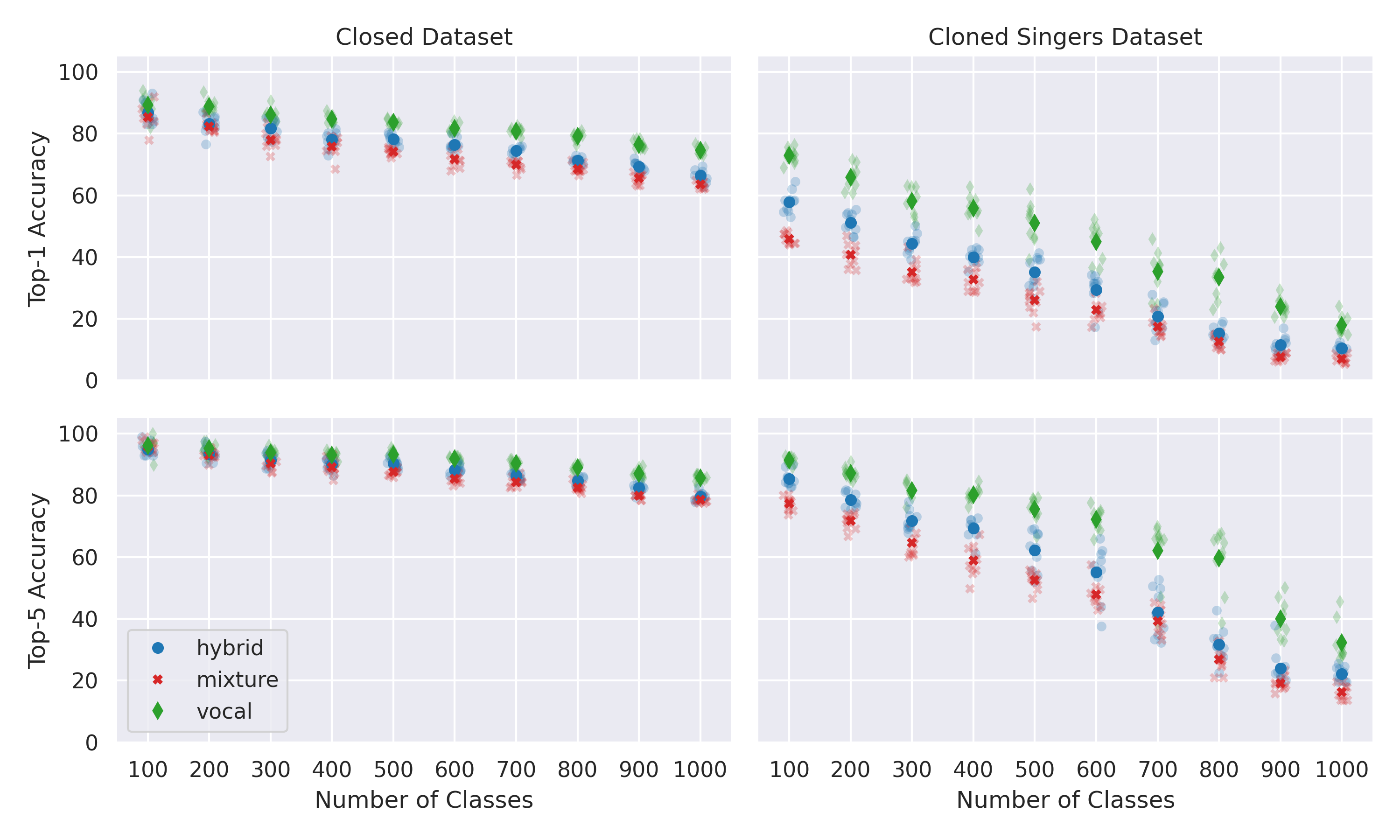
Cloned voices of popular singers sound increasingly realistic and have gained popularity over the past few years. They however pose a threat to the industry due to personality rights concerns. As such, methods to identify the original singer in synthetic voices are needed. In this paper, we investigate how singer identification methods could be used for such a task. We present three embedding models that are trained using a singer-level contrastive learning scheme, where positive pairs consist of segments with vocals from the same singers. These segments can be mixtures for the first model, vocals for the second, and both for the third. We demonstrate that all three models are highly capable of identifying real singers. However, their performance deteriorates when classifying cloned versions of singers in our evaluation set. This is especially true for models that use mixtures as an input. These findings highlight the need to understand the biases that exist within singer identification systems, and how they can influence the identification of voice deepfakes in music.
Read more7/12/2024