Detecting Synthetic Lyrics with Few-Shot Inference

0
🤯
Sign in to get full access
Overview
- This paper presents a method for detecting synthetic lyrics generated by language models using few-shot learning.
- The approach aims to identify machine-generated lyrics, which is an important task for maintaining the integrity of music and lyrics in the face of advancing language generation capabilities.
- The authors explore different few-shot learning techniques and dataset configurations to build an effective lyric detector.
Plain English Explanation
The paper focuses on the challenge of detecting lyrics that have been generated by artificial intelligence (AI) systems, rather than written by human songwriters. As language models become more advanced, it's becoming easier for them to generate plausible-sounding song lyrics. However, these machine-generated lyrics may lack the creativity, nuance, and emotional depth of human-written lyrics.
The researchers' goal was to develop a way to automatically identify lyrics that were produced by an AI, rather than a human. They explored different "few-shot learning" techniques, which involve training a model to recognize certain characteristics using only a small number of examples. This is useful because it allows the model to be applied to new, unseen lyrics without requiring a large training dataset.
By experimenting with various few-shot learning approaches and dataset configurations, the researchers were able to build an effective system for detecting synthetic lyrics. This technology could be used to help maintain the authenticity and artistic integrity of music, as AI-generated lyrics become more prevalent.
Technical Explanation
The paper explores the task of detecting machine-generated lyrics using few-shot learning techniques. The authors first construct a dataset of human-written and machine-generated lyrics, drawing from various sources. They then experiment with different few-shot learning approaches, including prototypical networks, matching networks, and relation networks, to build a classifier that can distinguish between synthetic and human-written lyrics.
The few-shot learning setup involves training the model on a small number of labeled examples (e.g., 5-10 per class) and then evaluating its performance on unseen test data. The authors explore the impact of factors like the number of training examples, the choice of few-shot learning algorithm, and the specific dataset configuration on the model's detection accuracy.
Through their experiments, the researchers demonstrate that few-shot learning can be an effective approach for detecting machine-generated text in the wild, including in the domain of song lyrics. They also provide insights into the characteristics that differentiate human-written and synthetic lyrics, which could inform the development of more innovative approaches to cover song detection and lyric similarity analysis.
Critical Analysis
The paper presents a promising approach for detecting synthetic lyrics, but it also acknowledges several limitations and areas for further research. For example, the authors note that their dataset may not be fully representative of the diversity of human-written and machine-generated lyrics in the real world, and that more robust datasets may be needed to generalize the findings.
Additionally, the few-shot learning techniques used in the paper, while effective, may not be the only viable approach to this problem. There may be other machine learning architectures or data augmentation strategies that could further improve the detection accuracy, especially as language models continue to advance.
The paper also does not delve into the potential societal implications of this technology, such as how it could be used to maintain the authenticity of creative works or how it might be misused to censor or suppress certain types of content. These are important considerations that future research in this area should address.
Overall, the paper presents a solid foundation for detecting synthetic lyrics using few-shot learning, but there is still room for further exploration and innovation in this rapidly evolving field.
Conclusion
The paper demonstrates the feasibility of using few-shot learning techniques to detect synthetic lyrics generated by language models. This is an important task for preserving the integrity and authenticity of music, as AI-generated content becomes more prevalent.
The researchers' approach of exploring different few-shot learning algorithms and dataset configurations provides valuable insights into the characteristics that distinguish human-written and machine-generated lyrics. These findings could inform the development of more innovative approaches to cover song detection and lyric similarity analysis.
While the paper presents a promising solution, it also highlights the need for further research to address limitations and explore the broader implications of this technology. As language models continue to advance, the ability to reliably detect machine-generated text in the wild will become increasingly crucial for maintaining the authenticity and artistic integrity of creative works.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤯
0
Detecting Synthetic Lyrics with Few-Shot Inference
Yanis Labrak, Gabriel Meseguer-Brocal, Elena V. Epure
In recent years, generated content in music has gained significant popularity, with large language models being effectively utilized to produce human-like lyrics in various styles, themes, and linguistic structures. This technological advancement supports artists in their creative processes but also raises issues of authorship infringement, consumer satisfaction and content spamming. To address these challenges, methods for detecting generated lyrics are necessary. However, existing works have not yet focused on this specific modality or on creative text in general regarding machine-generated content detection methods and datasets. In response, we have curated the first dataset of high-quality synthetic lyrics and conducted a comprehensive quantitative evaluation of various few-shot content detection approaches, testing their generalization capabilities and complementing this with a human evaluation. Our best few-shot detector, based on LLM2Vec, surpasses stylistic and statistical methods, which are shown competitive in other domains at distinguishing human-written from machine-generated content. It also shows good generalization capabilities to new artists and models, and effectively detects post-generation paraphrasing. This study emphasizes the need for further research on creative content detection, particularly in terms of generalization and scalability with larger song catalogs. All datasets, pre-processing scripts, and code are available publicly on GitHub and Hugging Face under the Apache 2.0 license.
Read more6/24/2024

0
SONICS: Synthetic Or Not -- Identifying Counterfeit Songs
Md Awsafur Rahman, Zaber Ibn Abdul Hakim, Najibul Haque Sarker, Bishmoy Paul, Shaikh Anowarul Fattah
The recent surge in AI-generated songs presents exciting possibilities and challenges. While these tools democratize music creation, they also necessitate the ability to distinguish between human-composed and AI-generated songs for safeguarding artistic integrity and content curation. Existing research and datasets in fake song detection only focus on singing voice deepfake detection (SVDD), where the vocals are AI-generated but the instrumental music is sourced from real songs. However, this approach is inadequate for contemporary end-to-end AI-generated songs where all components (vocals, lyrics, music, and style) could be AI-generated. Additionally, existing datasets lack lyrics-music diversity, long-duration songs, and open fake songs. To address these gaps, we introduce SONICS, a novel dataset for end-to-end Synthetic Song Detection (SSD), comprising over 97k songs with over 49k synthetic songs from popular platforms like Suno and Udio. Furthermore, we highlight the importance of modeling long-range temporal dependencies in songs for effective authenticity detection, an aspect overlooked in existing methods. To capture these patterns, we propose a novel model, SpecTTTra, that is up to 3 times faster and 6 times more memory efficient compared to popular CNN and Transformer-based models while maintaining competitive performance. Finally, we offer both AI-based and Human evaluation benchmarks, addressing another deficiency in current research.
Read more8/28/2024
0
Few-Shot Detection of Machine-Generated Text using Style Representations
Rafael Rivera Soto, Kailin Koch, Aleem Khan, Barry Chen, Marcus Bishop, Nicholas Andrews
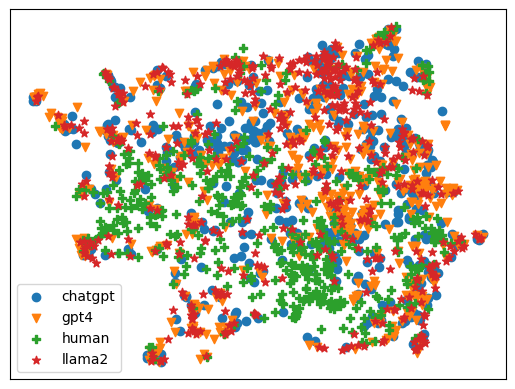
The advent of instruction-tuned language models that convincingly mimic human writing poses a significant risk of abuse. However, such abuse may be counteracted with the ability to detect whether a piece of text was composed by a language model rather than a human author. Some previous approaches to this problem have relied on supervised methods by training on corpora of confirmed human- and machine- written documents. Unfortunately, model under-specification poses an unavoidable challenge for neural network-based detectors, making them brittle in the face of data shifts, such as the release of newer language models producing still more fluent text than the models used to train the detectors. Other approaches require access to the models that may have generated a document in question, which is often impractical. In light of these challenges, we pursue a fundamentally different approach not relying on samples from language models of concern at training time. Instead, we propose to leverage representations of writing style estimated from human-authored text. Indeed, we find that features effective at distinguishing among human authors are also effective at distinguishing human from machine authors, including state-of-the-art large language models like Llama-2, ChatGPT, and GPT-4. Furthermore, given a handful of examples composed by each of several specific language models of interest, our approach affords the ability to predict which model generated a given document. The code and data to reproduce our experiments are available at https://github.com/LLNL/LUAR/tree/main/fewshot_iclr2024.
Read more5/9/2024
0
Uncovering LLM-Generated Code: A Zero-Shot Synthetic Code Detector via Code Rewriting
Tong Ye, Yangkai Du, Tengfei Ma, Lingfei Wu, Xuhong Zhang, Shouling Ji, Wenhai Wang
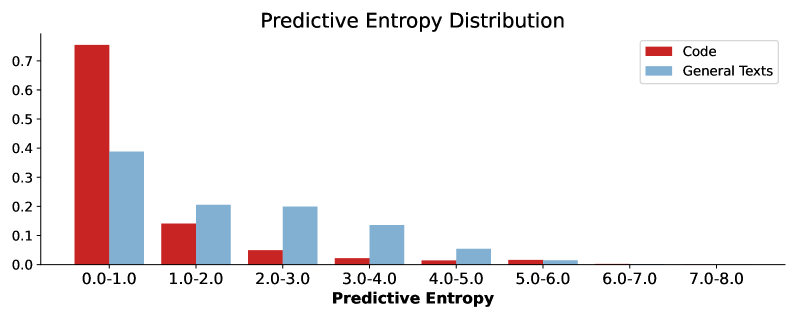
Large Language Models (LLMs) have exhibited remarkable proficiency in generating code. However, the misuse of LLM-generated (Synthetic) code has prompted concerns within both educational and industrial domains, highlighting the imperative need for the development of synthetic code detectors. Existing methods for detecting LLM-generated content are primarily tailored for general text and often struggle with code content due to the distinct grammatical structure of programming languages and massive low-entropy tokens. Building upon this, our work proposes a novel zero-shot synthetic code detector based on the similarity between the code and its rewritten variants. Our method relies on the intuition that the differences between the LLM-rewritten and original codes tend to be smaller when the original code is synthetic. We utilize self-supervised contrastive learning to train a code similarity model and assess our approach on two synthetic code detection benchmarks. Our results demonstrate a notable enhancement over existing synthetic content detectors designed for general texts, with an improvement of 20.5% in the APPS benchmark and 29.1% in the MBPP benchmark.
Read more5/31/2024