SonifyAR: Context-Aware Sound Generation in Augmented Reality

0
Sign in to get full access
Overview
- This paper introduces SonifyAR, a system that generates context-aware sound effects in augmented reality (AR) experiences.
- SonifyAR uses machine learning models to analyze the visual and spatial context of an AR scene and automatically generate appropriate sound effects to enhance the user's experience.
- The system aims to create a more immersive and believable AR environment by seamlessly integrating synchronized audio with the visual and spatial cues.
Plain English Explanation
SonifyAR is a tool that can add realistic sound effects to augmented reality (AR) experiences. When you use AR, you see digital content overlaid on the real world, like a character or object. SonifyAR can analyze what's happening in the AR scene and automatically generate appropriate sound effects to match.
For example, if you have a virtual character walking in an AR scene, SonifyAR could play footstep sounds that sync up with the character's movements. Or if there's a virtual object that's supposed to be made of metal, SonifyAR could generate a metallic clanging sound when you interact with it. The goal is to make the AR experience feel more immersive and believable by having the audio match what you see.
Leveraging AI to generate audio for user-generated content is an active area of research, and SonifyAR is one approach to bringing that capability to augmented reality applications.
Technical Explanation
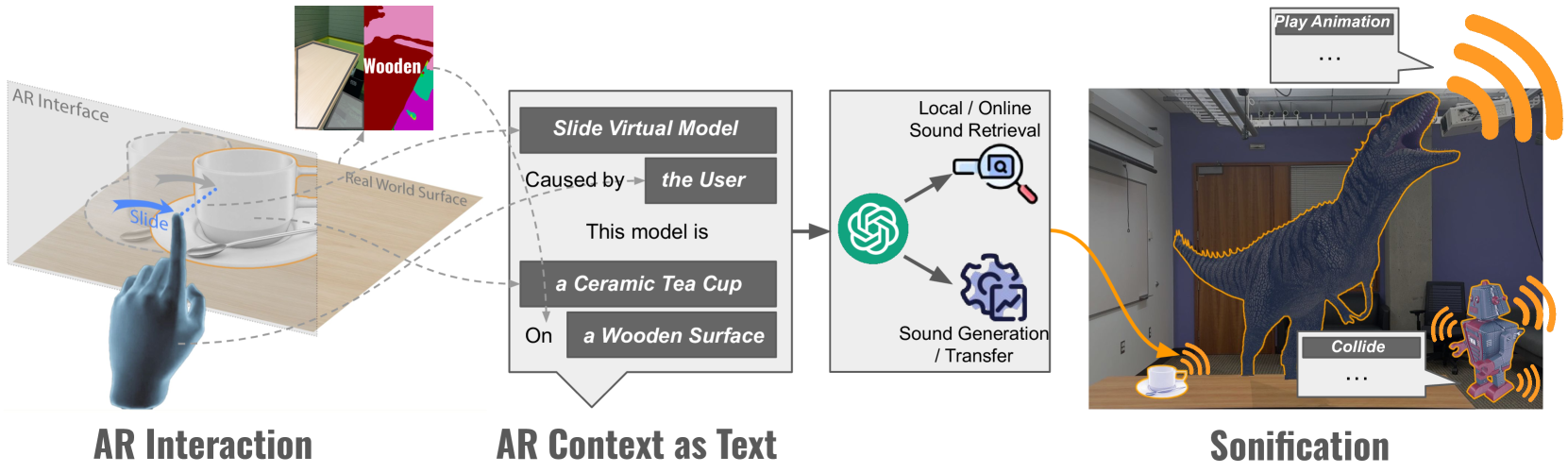
SonifyAR is designed to automatically generate context-aware sound effects for augmented reality experiences. The system uses a combination of computer vision and spatial audio techniques to analyze the visual and spatial context of an AR scene and create appropriate sound effects.
The core of SonifyAR is a deep learning model that takes in information about the AR scene, including the positions and movements of virtual objects, and outputs corresponding sound effects. This model is trained on a dataset of AR scenes and associated audio, allowing it to learn the relationships between visual/spatial cues and the appropriate sound effects.
Robotic blended sonification techniques are then used to spatially position and blend the generated sound effects with the user's perspective in the AR environment. This creates a seamless integration of audio and visual elements.
SonifyAR also includes an authoring tool that allows designers to fine-tune the generated audio, adjust audio-visual synchronization, and author new sound effects. This gives creators more control over the final AR experience.
Critical Analysis
One key limitation of SonifyAR is the reliance on a pre-trained model, which may not generalize well to all types of AR content and environments. The authors mention the need for further research to expand the model's capabilities and robustness.
Additionally, the current implementation of SonifyAR focuses on simple sound effects, rather than more complex, dynamic audio that could enhance the narrative or emotional experience of an AR scene. SonicVisionLM, for example, explores using language models to generate more expressive audio.
Integrating SonifyAR with real-time 3D audio rendering and head-related transfer functions could also improve the spatial immersion and believability of the audio. Audio simulation for sound source localization in virtual environments is an active area of research in this direction.
Conclusion
SonifyAR is a promising approach to enhancing augmented reality experiences by automatically generating context-aware sound effects. By seamlessly integrating audio with the visual and spatial cues in an AR scene, SonifyAR has the potential to create more immersive and believable mixed reality experiences.
While the current implementation has some limitations, the underlying concepts and techniques utilized by SonifyAR represent an important step towards better integrating audio and visual elements in augmented reality. Further advancements in areas like generative audio and spatial audio rendering could unlock even more opportunities for SonifyAR and similar systems to transform how we experience the blending of the physical and digital worlds.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SonifyAR: Context-Aware Sound Generation in Augmented Reality
Xia Su, Jon E. Froehlich, Eunyee Koh, Chang Xiao
Sound plays a crucial role in enhancing user experience and immersiveness in Augmented Reality (AR). However, current platforms lack support for AR sound authoring due to limited interaction types, challenges in collecting and specifying context information, and difficulty in acquiring matching sound assets. We present SonifyAR, an LLM-based AR sound authoring system that generates context-aware sound effects for AR experiences. SonifyAR expands the current design space of AR sound and implements a Programming by Demonstration (PbD) pipeline to automatically collect contextual information of AR events, including virtual content semantics and real world context. This context information is then processed by a large language model to acquire sound effects with Recommendation, Retrieval, Generation, and Transfer methods. To evaluate the usability and performance of our system, we conducted a user study with eight participants and created five example applications, including an AR-based science experiment, an improving case for AR headset safety, and an assisting example for low vision AR users.
Read more8/13/2024

0
Augmented Conversation with Embedded Speech-Driven On-the-Fly Referencing in AR
Shivesh Jadon, Mehrad Faridan, Edward Mah, Rajan Vaish, Wesley Willett, Ryo Suzuki
This paper introduces the concept of augmented conversation, which aims to support co-located in-person conversations via embedded speech-driven on-the-fly referencing in augmented reality (AR). Today computing technologies like smartphones allow quick access to a variety of references during the conversation. However, these tools often create distractions, reducing eye contact and forcing users to focus their attention on phone screens and manually enter keywords to access relevant information. In contrast, AR-based on-the-fly referencing provides relevant visual references in real-time, based on keywords extracted automatically from the spoken conversation. By embedding these visual references in AR around the conversation partner, augmented conversation reduces distraction and friction, allowing users to maintain eye contact and supporting more natural social interactions. To demonstrate this concept, we developed system, a Hololens-based interface that leverages real-time speech recognition, natural language processing and gaze-based interactions for on-the-fly embedded visual referencing. In this paper, we explore the design space of visual referencing for conversations, and describe our our implementation -- building on seven design guidelines identified through a user-centered design process. An initial user study confirms that our system decreases distraction and friction in conversations compared to smartphone searches, while providing highly useful and relevant information.
Read more5/30/2024

0
GazePointAR: A Context-Aware Multimodal Voice Assistant for Pronoun Disambiguation in Wearable Augmented Reality
Jaewook Lee, Jun Wang, Elizabeth Brown, Liam Chu, Sebastian S. Rodriguez, Jon E. Froehlich
Voice assistants (VAs) like Siri and Alexa are transforming human-computer interaction; however, they lack awareness of users' spatiotemporal context, resulting in limited performance and unnatural dialogue. We introduce GazePointAR, a fully-functional context-aware VA for wearable augmented reality that leverages eye gaze, pointing gestures, and conversation history to disambiguate speech queries. With GazePointAR, users can ask what's over there? or how do I solve this math problem? simply by looking and/or pointing. We evaluated GazePointAR in a three-part lab study (N=12): (1) comparing GazePointAR to two commercial systems; (2) examining GazePointAR's pronoun disambiguation across three tasks; (3) and an open-ended phase where participants could suggest and try their own context-sensitive queries. Participants appreciated the naturalness and human-like nature of pronoun-driven queries, although sometimes pronoun use was counter-intuitive. We then iterated on GazePointAR and conducted a first-person diary study examining how GazePointAR performs in-the-wild. We conclude by enumerating limitations and design considerations for future context-aware VAs.
Read more4/15/2024

0
Social MediARverse Investigating Users Social Media Content Sharing and Consuming Intentions with Location-Based AR
Linda Hirsch, Florian Muller, Mari Kruse, Andreas Butz, Robin Welsch
Augmented Reality (AR) is evolving to become the next frontier in social media, merging physical and virtual reality into a living metaverse, a Social MediARverse. With this transition, we must understand how different contexts (public, semi-public, and private) affect user engagement with AR content. We address this gap in current research by conducting an online survey with 110 participants, showcasing 36 AR videos, and polling them about the content's fit and appropriateness. Specifically, we manipulated these three spaces, two forms of dynamism (dynamic vs. static), and two dimensionalities (2D vs. 3D). Our findings reveal that dynamic AR content is generally more favorably received than static content. Additionally, users find sharing and engaging with AR content in private settings more comfortable than in others. By this, the study offers valuable insights for designing and implementing future Social MediARverses and guides industry and academia on content visualization and contextual considerations.
Read more9/4/2024