Sound Event Detection and Localization with Distance Estimation
2403.11827
0
0
Abstract
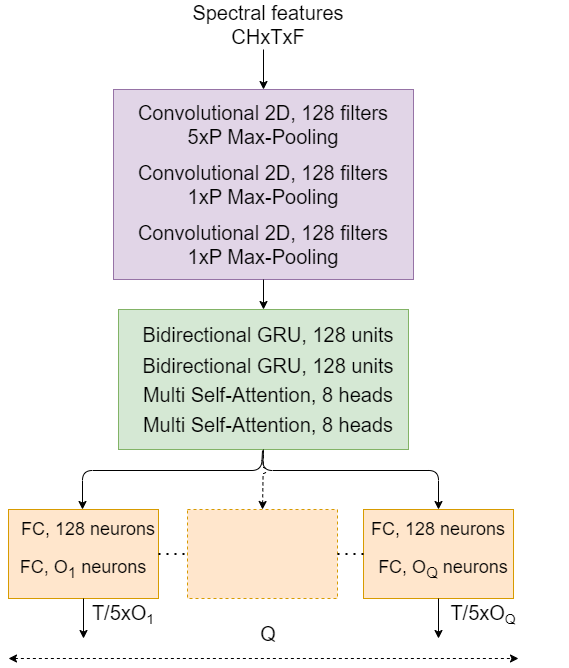
Sound Event Detection and Localization (SELD) is a combined task of identifying sound events and their corresponding direction-of-arrival (DOA). While this task has numerous applications and has been extensively researched in recent years, it fails to provide full information about the sound source position. In this paper, we overcome this problem by extending the task to Sound Event Detection, Localization with Distance Estimation (3D SELD). We study two ways of integrating distance estimation within the SELD core - a multi-task approach, in which the problem is tackled by a separate model output, and a single-task approach obtained by extending the multi-ACCDOA method to include distance information. We investigate both methods for the Ambisonic and binaural versions of STARSS23: Sony-TAU Realistic Spatial Soundscapes 2023. Moreover, our study involves experiments on the loss function related to the distance estimation part. Our results show that it is possible to perform 3D SELD without any degradation of performance in sound event detection and DOA estimation.
Create account to get full access
Overview
- This paper presents a system for detecting and localizing sound events, as well as estimating the distance to the sound source.
- The system uses Ambisonics and binaural recordings to capture spatial audio information, which is then processed by deep learning models.
- The authors evaluated their approach on several datasets and found it to be effective for sound event detection, sound source localization, and distance estimation.
Plain English Explanation
This research focuses on improving our ability to detect and locate the source of various sounds, as well as estimate how far away the sound is coming from. The researchers used a technique called Ambisonics, which captures spatial audio information, along with binaural recordings (recordings that mimic human hearing). They then fed this data into deep learning models to teach the system how to identify different types of sounds, figure out where they're coming from, and gauge their distance.
The key idea is that by using these advanced audio recording and processing techniques, the system can more accurately perceive the acoustic environment and the properties of the sounds within it. This could be useful for a variety of applications, such as audio simulation for sound source localization, semi-supervised sound event detection, and sound event bounding boxes.
Technical Explanation
The authors' approach involves first capturing spatial audio data using Ambisonics and binaural recordings. Ambisonics is a technique that records the full 3D soundfield, while binaural recordings use two microphones to simulate human hearing. This information is then processed by deep learning models to perform three key tasks:
- Sound event detection: The system identifies the presence and timing of various sound events in the audio.
- Sound source localization: The system determines the direction and position of the sound sources.
- Distance estimation: The system estimates the distance to the sound sources.
The authors evaluated their system on several datasets and found that it performed well on all three tasks, demonstrating the potential of this approach for applications that require understanding the acoustic environment in detail.
Critical Analysis
The authors provide a comprehensive evaluation of their system and acknowledge some of its limitations. For example, they note that their distance estimation approach relies on assumptions about sound propagation that may not always hold true in real-world environments. Additionally, the authors mention that their system may struggle with complex acoustic scenes with multiple overlapping sound sources.
That said, the overall approach seems promising and the authors have made their code publicly available, which should enable further research and development in this area. One potential area for improvement could be exploring more advanced deep learning architectures or incorporating additional sensory modalities, such as visual information, to further enhance the system's capabilities.
Conclusion
This paper presents an interesting approach for sound event detection, sound source localization, and distance estimation using spatial audio recordings and deep learning. The authors demonstrate the effectiveness of their system on several datasets and provide valuable insights into the challenges and opportunities in this field. While the approach has some limitations, it represents an important step forward in our ability to understand and analyze complex acoustic environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Text-Queried Target Sound Event Localization
Jinzheng Zhao, Xinyuan Qian, Yong Xu, Haohe Liu, Yin Cao, Davide Berghi, Wenwu Wang
0
0
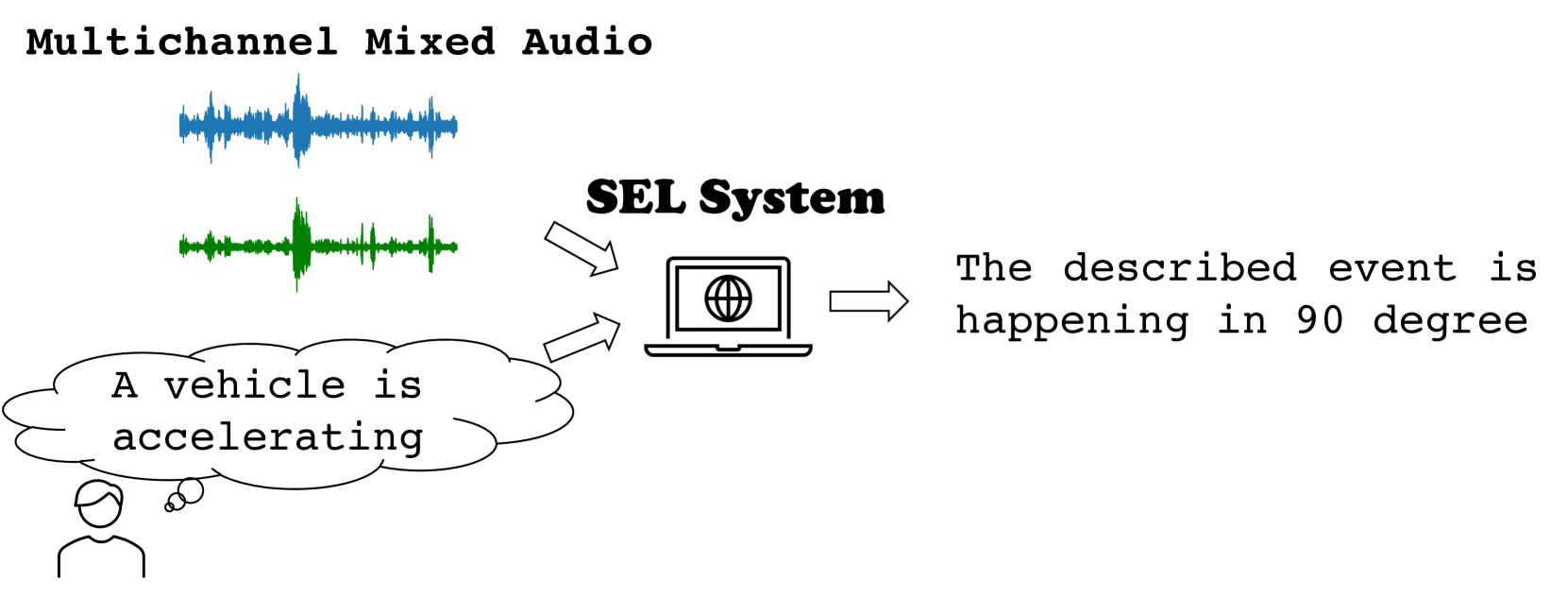
Sound event localization and detection (SELD) aims to determine the appearance of sound classes, together with their Direction of Arrival (DOA). However, current SELD systems can only predict the activities of specific classes, for example, 13 classes in DCASE challenges. In this paper, we propose text-queried target sound event localization (SEL), a new paradigm that allows the user to input the text to describe the sound event, and the SEL model can predict the location of the related sound event. The proposed task presents a more user-friendly way for human-computer interaction. We provide a benchmark study for the proposed task and perform experiments on datasets created by simulated room impulse response (RIR) and real RIR to validate the effectiveness of the proposed methods. We hope that our benchmark will inspire the interest and additional research for text-queried sound source localization.
6/25/2024
Exploring Audio-Visual Information Fusion for Sound Event Localization and Detection In Low-Resource Realistic Scenarios
Ya Jiang, Qing Wang, Jun Du, Maocheng Hu, Pengfei Hu, Zeyan Liu, Shi Cheng, Zhaoxu Nian, Yuxuan Dong, Mingqi Cai, Xin Fang, Chin-Hui Lee
0
0
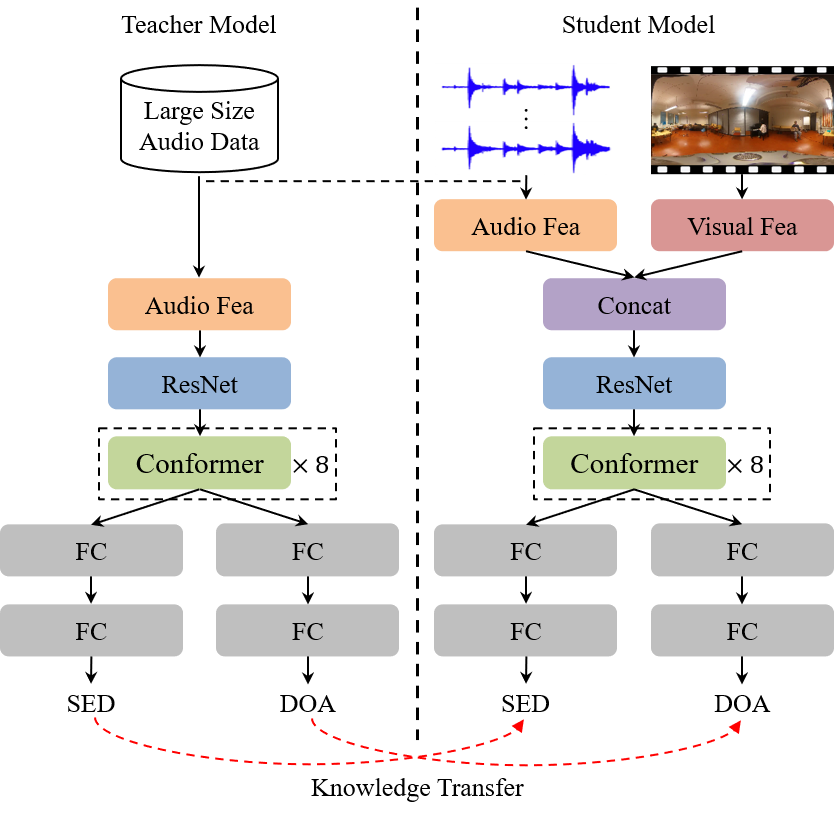
This study presents an audio-visual information fusion approach to sound event localization and detection (SELD) in low-resource scenarios. We aim at utilizing audio and video modality information through cross-modal learning and multi-modal fusion. First, we propose a cross-modal teacher-student learning (TSL) framework to transfer information from an audio-only teacher model, trained on a rich collection of audio data with multiple data augmentation techniques, to an audio-visual student model trained with only a limited set of multi-modal data. Next, we propose a two-stage audio-visual fusion strategy, consisting of an early feature fusion and a late video-guided decision fusion to exploit synergies between audio and video modalities. Finally, we introduce an innovative video pixel swapping (VPS) technique to extend an audio channel swapping (ACS) method to an audio-visual joint augmentation. Evaluation results on the Detection and Classification of Acoustic Scenes and Events (DCASE) 2023 Challenge data set demonstrate significant improvements in SELD performances. Furthermore, our submission to the SELD task of the DCASE 2023 Challenge ranks first place by effectively integrating the proposed techniques into a model ensemble.
6/24/2024
⚙️
Sound Event Bounding Boxes
Janek Ebbers, Francois G. Germain, Gordon Wichern, Jonathan Le Roux
0
0
Sound event detection is the task of recognizing sounds and determining their extent (onset/offset times) within an audio clip. Existing systems commonly predict sound presence confidence in short time frames. Then, thresholding produces binary frame-level presence decisions, with the extent of individual events determined by merging consecutive positive frames. In this paper, we show that frame-level thresholding degrades the prediction of the event extent by coupling it with the system's sound presence confidence. We propose to decouple the prediction of event extent and confidence by introducing SEBBs, which format each sound event prediction as a tuple of a class type, extent, and overall confidence. We also propose a change-detection-based algorithm to convert legacy frame-level outputs into SEBBs. We find the algorithm significantly improves the performance of DCASE 2023 Challenge systems, boosting the state of the art from .644 to .686 PSDS1.
6/7/2024
🔎
DCASE 2024 Task 4: Sound Event Detection with Heterogeneous Data and Missing Labels
Samuele Cornell, Janek Ebbers, Constance Douwes, Irene Mart'in-Morat'o, Manu Harju, Annamaria Mesaros, Romain Serizel
0
0
The Detection and Classification of Acoustic Scenes and Events Challenge Task 4 aims to advance sound event detection (SED) systems in domestic environments by leveraging training data with different supervision uncertainty. Participants are challenged in exploring how to best use training data from different domains and with varying annotation granularity (strong/weak temporal resolution, soft/hard labels), to obtain a robust SED system that can generalize across different scenarios. Crucially, annotation across available training datasets can be inconsistent and hence sound labels of one dataset may be present but not annotated in the other one and vice-versa. As such, systems will have to cope with potentially missing target labels during training. Moreover, as an additional novelty, systems will also be evaluated on labels with different granularity in order to assess their robustness for different applications. To lower the entry barrier for participants, we developed an updated baseline system with several caveats to address these aforementioned problems. Results with our baseline system indicate that this research direction is promising and is possible to obtain a stronger SED system by using diverse domain training data with missing labels compared to training a SED system for each domain separately.
6/13/2024