SemiPL: A Semi-supervised Method for Event Sound Source Localization
2404.19615
0
0
🛠️
Abstract
In recent years, Event Sound Source Localization has been widely applied in various fields. Recent works typically relying on the contrastive learning framework show impressive performance. However, all work is based on large relatively simple datasets. It's also crucial to understand and analyze human behaviors (actions and interactions of people), voices, and sounds in chaotic events in many applications, e.g., crowd management, and emergency response services. In this paper, we apply the existing model to a more complex dataset, explore the influence of parameters on the model, and propose a semi-supervised improvement method SemiPL. With the increase in data quantity and the influence of label quality, self-supervised learning will be an unstoppable trend. The experiment shows that the parameter adjustment will positively affect the existing model. In particular, SSPL achieved an improvement of 12.2% cIoU and 0.56% AUC in Chaotic World compared to the results provided. The code is available at: https://github.com/ly245422/SSPL
Create account to get full access
Overview
- Event Sound Source Localization has been widely used in various fields.
- Recent work using contrastive learning shows impressive performance, but is based on simple datasets.
- Understanding human behaviors, voices, and sounds in chaotic events is crucial for applications like crowd management and emergency response.
- This paper applies existing models to a more complex dataset, explores parameter influence, and proposes a semi-supervised improvement method called SemiPL.
Plain English Explanation
Event Sound Source Localization is a technology that can pinpoint the location of sounds, like voices or other noises, in an environment. It's been used in lots of different areas recently. The latest research using a technique called contrastive learning has made big improvements, but has mostly been tested on simple, easy datasets.
However, it's really important to be able to understand human behavior, like actions and interactions, as well as voices and other sounds in chaotic, busy situations. Things like crowd management and emergency response services need this kind of capability.
This paper takes the existing sound localization models and applies them to a more complex, realistic dataset. They also look at how changing the model's settings (parameters) affects the performance. Finally, they propose a new semi-supervised learning method called SemiPL that can improve the results.
The key point is that as datasets get bigger and more realistic, and as the quality of the labels (the information about what's in the data) improves, self-supervised learning techniques like the ones used here are going to become more and more important. The experiments show that tuning the parameters of the existing models can give a nice boost in performance too.
Technical Explanation
The paper begins by noting the widespread application of Event Sound Source Localization and the impressive recent results using contrastive learning frameworks. However, it identifies a key limitation - the existing work has been primarily tested on relatively simple, straightforward datasets.
To address this, the researchers apply the existing models to a more complex "Chaotic World" dataset, which captures human behaviors, voices, and sounds in chaotic environments. They explore the influence of model parameters on the performance, and propose a semi-supervised learning method called SemiPL as an improvement.
The experiments demonstrate that adjusting the model parameters can lead to meaningful performance gains, with SemiPL achieving a 12.2% increase in Centered Intersection over Union (cIoU) and a 0.56% improvement in Area Under the Curve (AUC) compared to the baseline results on the Chaotic World dataset.
The paper highlights that as dataset size and label quality continue to improve, self-supervised learning techniques like the ones used here will become increasingly important. The source code for the proposed SemiPL method is made available at the provided GitHub link.
Critical Analysis
The paper makes a strong case for the importance of advancing Event Sound Source Localization capabilities to handle more complex, real-world scenarios beyond the simple datasets used in previous work. The focus on understanding human behaviors, voices, and sounds in chaotic environments is a valuable direction with clear applications in areas like crowd management and emergency response.
However, the paper does not provide much detail on the specific challenges or limitations of the Chaotic World dataset, nor does it thoroughly explore the reasons why the existing models may struggle with this more complex data. A deeper analysis of the dataset characteristics and the model failures could have provided additional insight.
Additionally, while the performance improvements with SemiPL are noteworthy, the paper does not discuss potential downsides or tradeoffs of the semi-supervised approach, such as increased training complexity or sensitivity to noisy labels. Exploring these aspects could have strengthened the critical evaluation of the proposed method.
Finally, the paper would have benefited from a more extensive discussion of future research directions, such as ways to further enhance the robustness and generalization of sound source localization models, or potential applications beyond the ones mentioned.
Conclusion
This paper highlights the importance of advancing Event Sound Source Localization capabilities to handle more realistic, complex scenarios beyond simple datasets. By applying existing models to a challenging "Chaotic World" dataset and proposing a semi-supervised learning method (SemiPL), the researchers demonstrate the potential for significant performance improvements as dataset size and label quality continue to improve.
The findings underscore the growing significance of self-supervised learning techniques in this domain, and the paper's open-sourcing of the SemiPL code provides a valuable resource for further research and development. While the critical analysis identifies a few areas for potential improvement, the overall work represents an important step forward in pushing the boundaries of Event Sound Source Localization and its real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
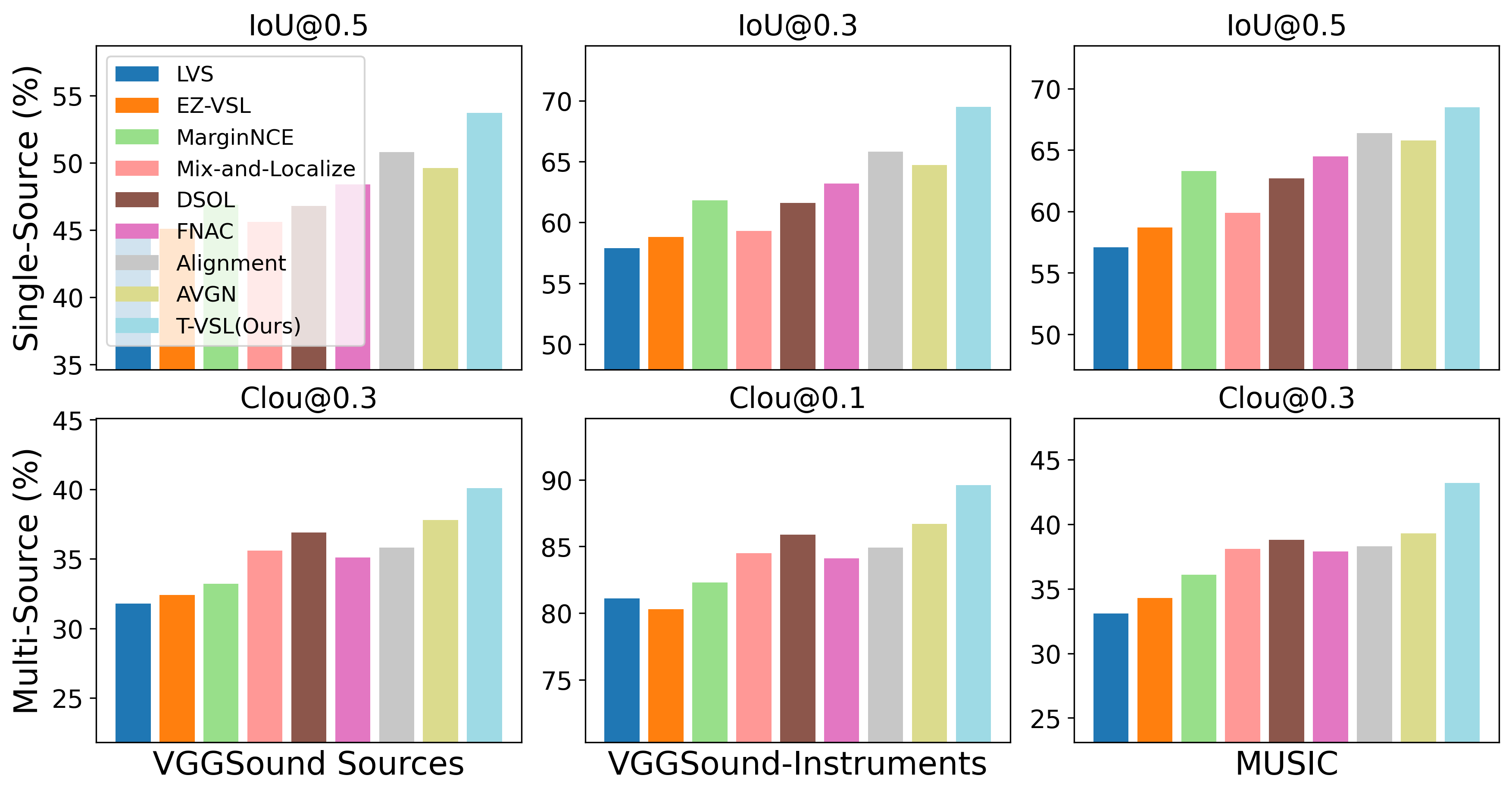
T-VSL: Text-Guided Visual Sound Source Localization in Mixtures
Tanvir Mahmud, Yapeng Tian, Diana Marculescu
0
0
Visual sound source localization poses a significant challenge in identifying the semantic region of each sounding source within a video. Existing self-supervised and weakly supervised source localization methods struggle to accurately distinguish the semantic regions of each sounding object, particularly in multi-source mixtures. These methods often rely on audio-visual correspondence as guidance, which can lead to substantial performance drops in complex multi-source localization scenarios. The lack of access to individual source sounds in multi-source mixtures during training exacerbates the difficulty of learning effective audio-visual correspondence for localization. To address this limitation, in this paper, we propose incorporating the text modality as an intermediate feature guide using tri-modal joint embedding models (e.g., AudioCLIP) to disentangle the semantic audio-visual source correspondence in multi-source mixtures. Our framework, dubbed T-VSL, begins by predicting the class of sounding entities in mixtures. Subsequently, the textual representation of each sounding source is employed as guidance to disentangle fine-grained audio-visual source correspondence from multi-source mixtures, leveraging the tri-modal AudioCLIP embedding. This approach enables our framework to handle a flexible number of sources and exhibits promising zero-shot transferability to unseen classes during test time. Extensive experiments conducted on the MUSIC, VGGSound, and VGGSound-Instruments datasets demonstrate significant performance improvements over state-of-the-art methods.
4/3/2024

Sound event localization and classification using WASN in Outdoor Environment
Dongzhe Zhang, Jianfeng Chen, Jisheng Bai, Mou Wang
0
0
Deep learning-based sound event localization and classification is an emerging research area within wireless acoustic sensor networks. However, current methods for sound event localization and classification typically rely on a single microphone array, making them susceptible to signal attenuation and environmental noise, which limits their monitoring range. Moreover, methods using multiple microphone arrays often focus solely on source localization, neglecting the aspect of sound event classification. In this paper, we propose a deep learning-based method that employs multiple features and attention mechanisms to estimate the location and class of sound source. We introduce a Soundmap feature to capture spatial information across multiple frequency bands. We also use the Gammatone filter to generate acoustic features more suitable for outdoor environments. Furthermore, we integrate attention mechanisms to learn channel-wise relationships and temporal dependencies within the acoustic features. To evaluate our proposed method, we conduct experiments using simulated datasets with different levels of noise and size of monitoring areas, as well as different arrays and source positions. The experimental results demonstrate the superiority of our proposed method over state-of-the-art methods in both sound event classification and sound source localization tasks. And we provide further analysis to explain the reasons for the observed errors.
4/1/2024
↗️
Audio Simulation for Sound Source Localization in Virtual Evironment
Yi Di Yuan, Swee Liang Wong, Jonathan Pan
0
0
Non-line-of-sight localization in signal-deprived environments is a challenging yet pertinent problem. Acoustic methods in such predominantly indoor scenarios encounter difficulty due to the reverberant nature. In this study, we aim to locate sound sources to specific locations within a virtual environment by leveraging physically grounded sound propagation simulations and machine learning methods. This process attempts to overcome the issue of data insufficiency to localize sound sources to their location of occurrence especially in post-event localization. We achieve 0.786+/- 0.0136 F1-score using an audio transformer spectrogram approach.
4/3/2024
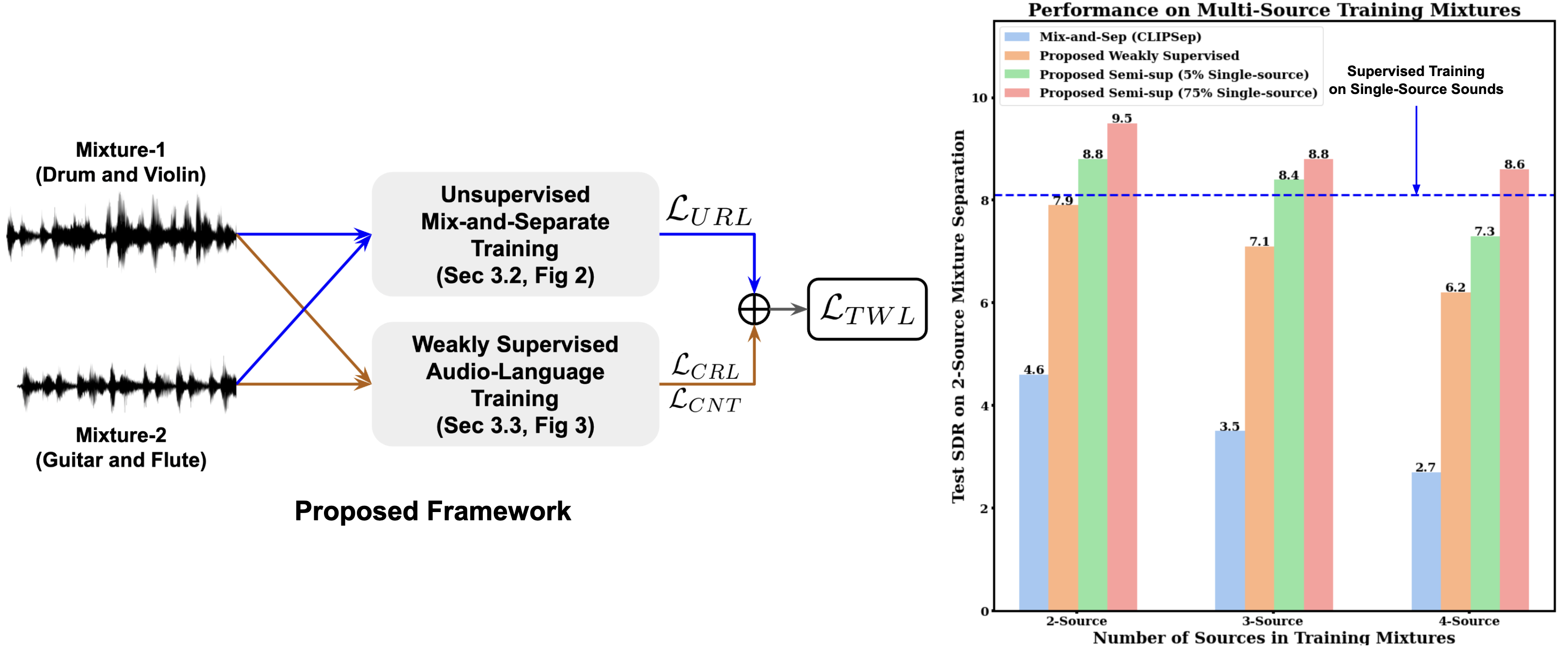
Weakly-supervised Audio Separation via Bi-modal Semantic Similarity
Tanvir Mahmud, Saeed Amizadeh, Kazuhito Koishida, Diana Marculescu
0
0
Conditional sound separation in multi-source audio mixtures without having access to single source sound data during training is a long standing challenge. Existing mix-and-separate based methods suffer from significant performance drop with multi-source training mixtures due to the lack of supervision signal for single source separation cases during training. However, in the case of language-conditional audio separation, we do have access to corresponding text descriptions for each audio mixture in our training data, which can be seen as (rough) representations of the audio samples in the language modality. To this end, in this paper, we propose a generic bi-modal separation framework which can enhance the existing unsupervised frameworks to separate single-source signals in a target modality (i.e., audio) using the easily separable corresponding signals in the conditioning modality (i.e., language), without having access to single-source samples in the target modality during training. We empirically show that this is well within reach if we have access to a pretrained joint embedding model between the two modalities (i.e., CLAP). Furthermore, we propose to incorporate our framework into two fundamental scenarios to enhance separation performance. First, we show that our proposed methodology significantly improves the performance of purely unsupervised baselines by reducing the distribution shift between training and test samples. In particular, we show that our framework can achieve 71% boost in terms of Signal-to-Distortion Ratio (SDR) over the baseline, reaching 97.5% of the supervised learning performance. Second, we show that we can further improve the performance of the supervised learning itself by 17% if we augment it by our proposed weakly-supervised framework, that enables a powerful semi-supervised framework for audio separation.
4/3/2024