SPAM: Stochastic Proximal Point Method with Momentum Variance Reduction for Non-convex Cross-Device Federated Learning

0
Sign in to get full access
Overview
- This paper presents a new stochastic optimization algorithm called SPAM (Stochastic Proximal Point Method with Momentum Variance Reduction) for non-convex cross-device federated learning.
- The key challenges in federated learning include the communication bottleneck and the non-convex nature of the optimization problem.
- SPAM addresses these challenges by using a stochastic proximal point method with momentum and variance reduction techniques.
Plain English Explanation
Federated learning is a technique where multiple devices, like phones or computers, collaboratively train a machine learning model without sharing their raw data. This is useful for preserving privacy and reducing the amount of data that needs to be transmitted. However, federated learning poses some challenges.
One major challenge is the communication bottleneck. In federated learning, the devices need to regularly send updates to a central server, which can use a lot of bandwidth and be slow. Another challenge is that the optimization problem in federated learning is often non-convex, meaning it has multiple local minima and is harder to solve.
The SPAM algorithm introduced in this paper aims to address these challenges. It uses a stochastic proximal point method to efficiently optimize the non-convex objective function. SPAM also incorporates momentum and variance reduction techniques to accelerate the optimization process and reduce the amount of communication required.
By using these advanced optimization techniques, SPAM is able to achieve better performance than previous federated learning algorithms, while also requiring less communication between the devices and the central server. This makes federated learning more practical and efficient, especially for applications on resource-constrained devices like smartphones.
Technical Explanation
The paper introduces a new stochastic optimization algorithm called SPAM (Stochastic Proximal Point Method with Momentum Variance Reduction) for non-convex cross-device federated learning. The key challenges addressed by SPAM are the communication bottleneck and the non-convex nature of the optimization problem in federated learning.
SPAM uses a stochastic proximal point method to efficiently optimize the non-convex objective function. This method combines the proximal point algorithm, which can handle non-convex problems, with stochastic gradients to reduce the computational cost. SPAM also incorporates momentum and variance reduction techniques to further accelerate the optimization process and reduce the amount of communication required.
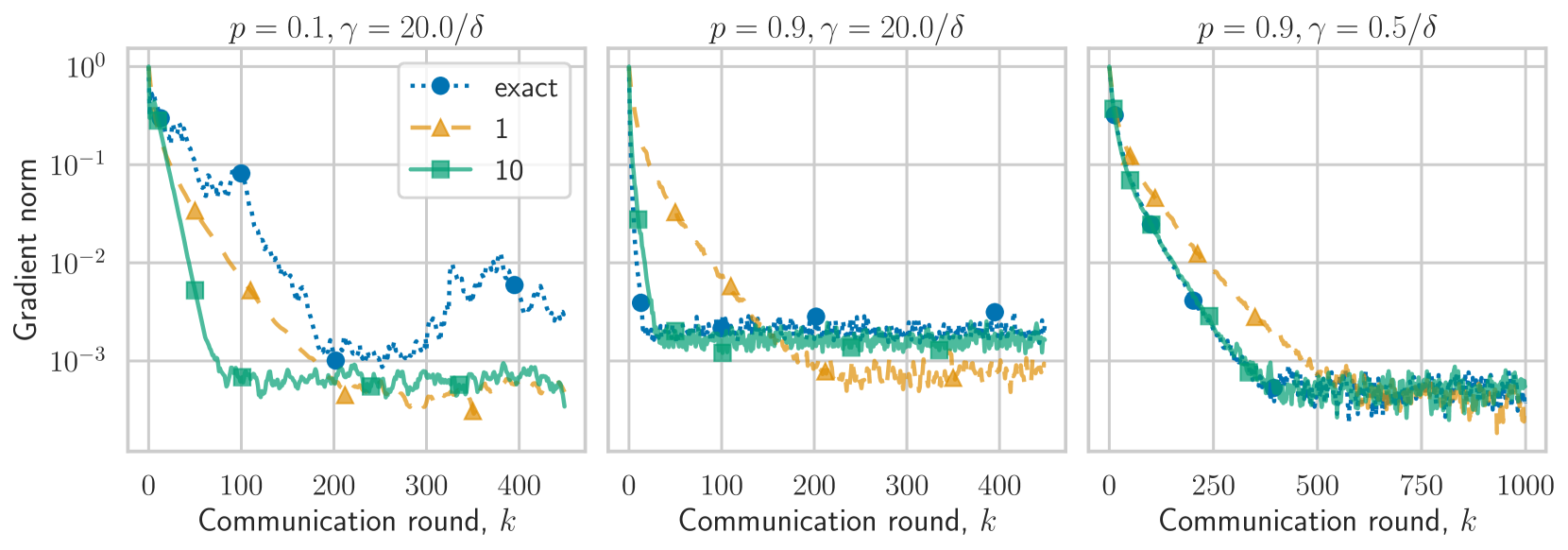
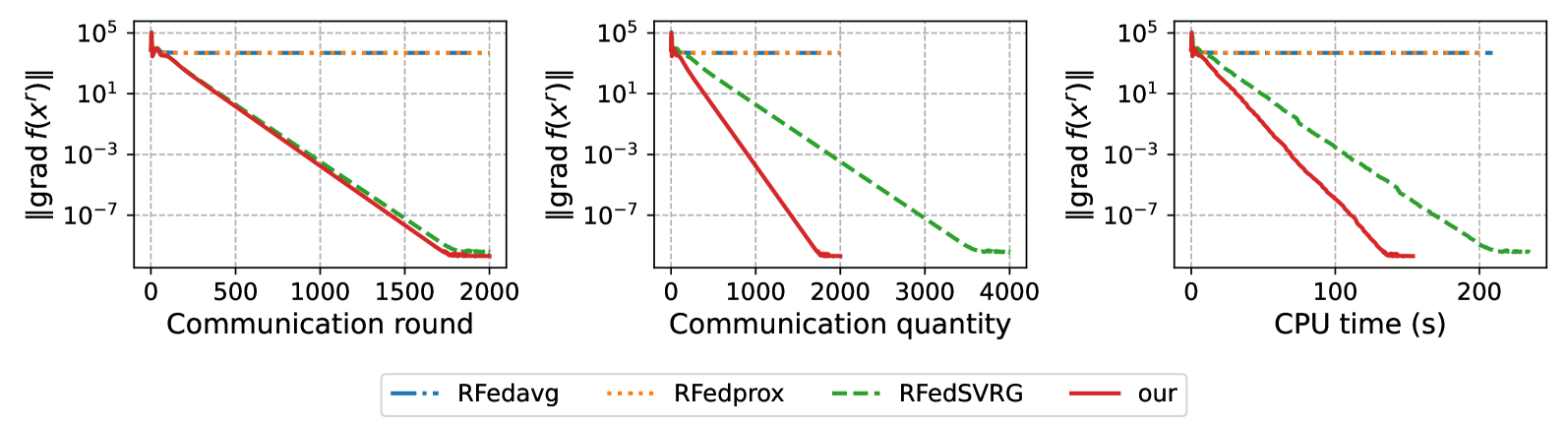
The paper presents a detailed theoretical analysis of SPAM, proving its convergence and establishing bounds on the communication complexity. The authors also conduct extensive experiments on both synthetic and real-world datasets, demonstrating that SPAM outperforms state-of-the-art federated learning algorithms in terms of both optimization performance and communication efficiency.
Critical Analysis
The paper provides a thorough theoretical and empirical analysis of the SPAM algorithm, and the results are promising. However, there are a few potential limitations and areas for further research:
-
Assumption of i.i.d. data: The analysis and experiments in the paper assume that the data is independently and identically distributed (i.i.d.) across the devices. In practice, this assumption may not hold, and the algorithm's performance may degrade in the presence of non-i.i.d. data.
-
Communication efficiency: While SPAM reduces the communication complexity compared to previous algorithms, there may still be room for improvement, especially for applications with very limited bandwidth or on-device computational resources. Exploring more advanced compression techniques could further enhance the communication efficiency.
-
Robustness to client drift: In federated learning, the local models on the devices can drift over time, which can negatively impact the global model's performance. Techniques like locally estimated global perturbations may help improve the algorithm's robustness to this issue.
-
Heterogeneous devices: The current analysis assumes homogeneous devices with similar computational capabilities. Extending the algorithm to handle heterogeneous devices with varying resources could increase its real-world applicability.
Despite these potential limitations, the SPAM algorithm represents a significant advancement in the field of non-convex federated learning, and the ideas presented in this paper could inspire further research in this direction, such as locally adaptive federated learning or decentralized optimization with compression and momentum tracking.
Conclusion
This paper introduces the SPAM algorithm, a new stochastic optimization method for non-convex cross-device federated learning. SPAM addresses the key challenges of the communication bottleneck and the non-convex nature of the optimization problem by employing a stochastic proximal point method with momentum and variance reduction techniques.
The thorough theoretical analysis and extensive experiments demonstrate that SPAM outperforms state-of-the-art federated learning algorithms in terms of both optimization performance and communication efficiency. This represents an important step forward in making federated learning more practical and scalable, particularly for applications on resource-constrained devices like smartphones.
While the paper identifies some potential limitations and areas for future research, the SPAM algorithm is a significant contribution to the field of federated learning and could inspire further advancements in privacy-preserving federated learning and efficient distributed optimization techniques.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SPAM: Stochastic Proximal Point Method with Momentum Variance Reduction for Non-convex Cross-Device Federated Learning
Avetik Karagulyan, Egor Shulgin, Abdurakhmon Sadiev, Peter Richt'arik
Cross-device training is a crucial subfield of federated learning, where the number of clients can reach into the billions. Standard approaches and local methods are prone to issues such as client drift and insensitivity to data similarities. We propose a novel algorithm (SPAM) for cross-device federated learning with non-convex losses, which solves both issues. We provide sharp analysis under second-order (Hessian) similarity, a condition satisfied by a variety of machine learning problems in practice. Additionally, we extend our results to the partial participation setting, where a cohort of selected clients communicate with the server at each communication round. Our method is the first in its kind, that does not require the smoothness of the objective and provably benefits from clients having similar data.
Read more5/31/2024

0
Cohort Squeeze: Beyond a Single Communication Round per Cohort in Cross-Device Federated Learning
Kai Yi, Timur Kharisov, Igor Sokolov, Peter Richt'arik
Virtually all federated learning (FL) methods, including FedAvg, operate in the following manner: i) an orchestrating server sends the current model parameters to a cohort of clients selected via certain rule, ii) these clients then independently perform a local training procedure (e.g., via SGD or Adam) using their own training data, and iii) the resulting models are shipped to the server for aggregation. This process is repeated until a model of suitable quality is found. A notable feature of these methods is that each cohort is involved in a single communication round with the server only. In this work we challenge this algorithmic design primitive and investigate whether it is possible to ``squeeze more juice out of each cohort than what is possible in a single communication round. Surprisingly, we find that this is indeed the case, and our approach leads to up to 74% reduction in the total communication cost needed to train a FL model in the cross-device setting. Our method is based on a novel variant of the stochastic proximal point method (SPPM-AS) which supports a large collection of client sampling procedures some of which lead to further gains when compared to classical client selection approaches.
Read more6/4/2024
0
Nonconvex Federated Learning on Compact Smooth Submanifolds With Heterogeneous Data
Jiaojiao Zhang, Jiang Hu, Anthony Man-Cho So, Mikael Johansson
Many machine learning tasks, such as principal component analysis and low-rank matrix completion, give rise to manifold optimization problems. Although there is a large body of work studying the design and analysis of algorithms for manifold optimization in the centralized setting, there are currently very few works addressing the federated setting. In this paper, we consider nonconvex federated learning over a compact smooth submanifold in the setting of heterogeneous client data. We propose an algorithm that leverages stochastic Riemannian gradients and a manifold projection operator to improve computational efficiency, uses local updates to improve communication efficiency, and avoids client drift. Theoretically, we show that our proposed algorithm converges sub-linearly to a neighborhood of a first-order optimal solution by using a novel analysis that jointly exploits the manifold structure and properties of the loss functions. Numerical experiments demonstrate that our algorithm has significantly smaller computational and communication overhead than existing methods.
Read more6/13/2024

0
Federated Smoothing Proximal Gradient for Quantile Regression with Non-Convex Penalties
Reza Mirzaeifard, Diyako Ghaderyan, Stefan Werner
Distributed sensors in the internet-of-things (IoT) generate vast amounts of sparse data. Analyzing this high-dimensional data and identifying relevant predictors pose substantial challenges, especially when data is preferred to remain on the device where it was collected for reasons such as data integrity, communication bandwidth, and privacy. This paper introduces a federated quantile regression algorithm to address these challenges. Quantile regression provides a more comprehensive view of the relationship between variables than mean regression models. However, traditional approaches face difficulties when dealing with nonconvex sparse penalties and the inherent non-smoothness of the loss function. For this purpose, we propose a federated smoothing proximal gradient (FSPG) algorithm that integrates a smoothing mechanism with the proximal gradient framework, thereby enhancing both precision and computational speed. This integration adeptly handles optimization over a network of devices, each holding local data samples, making it particularly effective in federated learning scenarios. The FSPG algorithm ensures steady progress and reliable convergence in each iteration by maintaining or reducing the value of the objective function. By leveraging nonconvex penalties, such as the minimax concave penalty (MCP) and smoothly clipped absolute deviation (SCAD), the proposed method can identify and preserve key predictors within sparse models. Comprehensive simulations validate the robust theoretical foundations of the proposed algorithm and demonstrate improved estimation precision and reliable convergence.
Read more8/14/2024