SPAR: Personalized Content-Based Recommendation via Long Engagement Attention

0
📶
Sign in to get full access
Overview
- Personalized content recommendations are essential for engaging users, but existing methods struggle with processing long user histories and insufficient user-item interactions.
- The paper introduces a content-based recommendation framework called SPAR that effectively extracts holistic user interests from long engagement histories by leveraging pretrained language models, poly-attention, and attention sparsity mechanisms.
- SPAR fuses user and item features for engagement prediction while maintaining standalone representations, enabling efficient model deployment.
- The framework also enhances user profiling by exploiting large language models to extract global interests from user histories.
- Experiments show SPAR outperforms state-of-the-art methods on benchmark datasets.
Plain English Explanation
Personalized content recommendations are crucial for keeping users engaged on digital platforms like streaming services or e-commerce sites. Reformulating Sequential Recommendation: Learning Dynamic User Interest and Knowledge Adaptation from Large Language Model to have shown the power of using pretrained language models to understand user preferences and match them with relevant content.
However, existing recommendation systems still struggle with two key challenges: processing very long histories of a user's past interactions, and not having enough data on the interactions between users and content items. The paper introduces a new framework called SPAR that tackles these issues effectively.
SPAR uses advanced techniques like The Elephant in the Room: Rethinking Usage of Pre-Trained Language Models and EmbSum: Leveraging Summarization Capabilities of Large Language Models to extract rich, holistic user interests from their long engagement histories. It fuses these user features with the characteristics of content items in a way that maintains standalone representations, enabling efficient model deployment.
SPAR also enhances user profiling by tapping into the global knowledge captured by large language models, allowing it to uncover users' broader interests beyond just their recent activities. This helps the system make more personalized and relevant recommendations.
Technical Explanation
The key innovation of SPAR is its approach to encoding user engagement histories and content items in a way that effectively captures user interests and enables robust content recommendations.
First, SPAR leverages pretrained language models to encode the text of a user's long engagement history in a session-based manner. This allows the framework to better model the dynamic nature of user interests over time, rather than just treating the history as a static document.
SPAR then applies poly-attention layers and attention sparsity mechanisms to selectively focus on the most relevant parts of the user's history when extracting their interests. This helps address the challenge of processing very long histories effectively.
To fuse the user and item features, SPAR uses a method that maintains standalone representations for both sides. This ensures the model can efficiently make predictions while still preserving the distinct characteristics of users and content items.
Finally, SPAR enhances user profiling by tapping into large language models to extract global interests from the user's engagement history. This complements the session-based encoding to provide a more comprehensive understanding of the user's preferences.
Experiments on benchmark datasets show that SPAR outperforms existing state-of-the-art content recommendation methods, demonstrating the effectiveness of its approach.
Critical Analysis
The paper presents a well-designed framework that makes significant advancements in personalized content recommendations. However, there are a few potential areas for further research and improvement:
-
Scalability: While the standalone user and item representations enable efficient model deployment, the paper does not discuss how SPAR would scale to real-world recommendation systems with millions of users and items. Diversifying by Intent: Recommendation System highlights the importance of scalability in recommender systems.
-
Interpretability: The use of complex techniques like poly-attention and large language models could make the model's decision-making less interpretable. Providing more transparency around how SPAR arrives at its recommendations could be valuable for users and system administrators.
-
Cold-Start Problem: The paper does not address how SPAR would handle new users or items with limited historical data. Extending the framework to better accommodate cold-start scenarios could further improve its practical applicability.
Despite these potential areas for improvement, SPAR represents a significant step forward in leveraging users' long engagement histories and pretrained language models for personalized content recommendations. The framework's strong performance on benchmark datasets suggests it could have a meaningful impact on real-world recommendation systems.
Conclusion
The SPAR framework introduced in this paper addresses critical challenges in personalized content recommendations by effectively extracting holistic user interests from long engagement histories. By combining session-based encoding, poly-attention, and large language model integration, SPAR outperforms state-of-the-art methods on benchmark datasets.
While there are opportunities for further research around scalability, interpretability, and cold-start scenarios, SPAR demonstrates the power of leveraging advanced natural language processing techniques to build more personalized and engaging recommendation systems. As digital platforms continue to compete for user attention, innovations like SPAR will play a crucial role in delivering content that truly resonates with individual users.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📶
0
SPAR: Personalized Content-Based Recommendation via Long Engagement Attention
Chiyu Zhang, Yifei Sun, Jun Chen, Jie Lei, Muhammad Abdul-Mageed, Sinong Wang, Rong Jin, Sem Park, Ning Yao, Bo Long
Leveraging users' long engagement histories is essential for personalized content recommendations. The success of pretrained language models (PLMs) in NLP has led to their use in encoding user histories and candidate items, framing content recommendations as textual semantic matching tasks. However, existing works still struggle with processing very long user historical text and insufficient user-item interaction. In this paper, we introduce a content-based recommendation framework, SPAR, which effectively tackles the challenges of holistic user interest extraction from the long user engagement history. It achieves so by leveraging PLM, poly-attention layers and attention sparsity mechanisms to encode user's history in a session-based manner. The user and item side features are sufficiently fused for engagement prediction while maintaining standalone representations for both sides, which is efficient for practical model deployment. Moreover, we enhance user profiling by exploiting large language model (LLM) to extract global interests from user engagement history. Extensive experiments on two benchmark datasets demonstrate that our framework outperforms existing state-of-the-art (SoTA) methods.
Read more5/24/2024

0
Enhancing Content-based Recommendation via Large Language Model
Wentao Xu, Qianqian Xie, Shuo Yang, Jiangxia Cao, Shuchao Pang
In real-world applications, users express different behaviors when they interact with different items, including implicit click/like interactions, and explicit comments/reviews interactions. Nevertheless, almost all recommender works are focused on how to describe user preferences by the implicit click/like interactions, to find the synergy of people. For the content-based explicit comments/reviews interactions, some works attempt to utilize them to mine the semantic knowledge to enhance recommender models. However, they still neglect the following two points: (1) The content semantic is a universal world knowledge; how do we extract the multi-aspect semantic information to empower different domains? (2) The user/item ID feature is a fundamental element for recommender models; how do we align the ID and content semantic feature space? In this paper, we propose a `plugin' semantic knowledge transferring method textbf{LoID}, which includes two major components: (1) LoRA-based large language model pretraining to extract multi-aspect semantic information; (2) ID-based contrastive objective to align their feature spaces. We conduct extensive experiments with SOTA baselines on real-world datasets, the detailed results demonstrating significant improvements of our method LoID.
Read more7/30/2024
💬
0
Large Language Models Enhanced Sequential Recommendation for Long-tail User and Item
Qidong Liu, Xian Wu, Xiangyu Zhao, Yejing Wang, Zijian Zhang, Feng Tian, Yefeng Zheng
Sequential recommendation systems (SRS) serve the purpose of predicting users' subsequent preferences based on their past interactions and have been applied across various domains such as e-commerce and social networking platforms. However, practical SRS encounters challenges due to the fact that most users engage with only a limited number of items, while the majority of items are seldom consumed. These challenges, termed as the long-tail user and long-tail item dilemmas, often create obstacles for traditional SRS methods. Mitigating these challenges is crucial as they can significantly impact user satisfaction and business profitability. While some research endeavors have alleviated these issues, they still grapple with issues such as seesaw or noise stemming from the scarcity of interactions. The emergence of large language models (LLMs) presents a promising avenue to address these challenges from a semantic standpoint. In this study, we introduce the Large Language Models Enhancement framework for Sequential Recommendation (LLM-ESR), which leverages semantic embeddings from LLMs to enhance SRS performance without increasing computational overhead. To combat the long-tail item challenge, we propose a dual-view modeling approach that fuses semantic information from LLMs with collaborative signals from traditional SRS. To address the long-tail user challenge, we introduce a retrieval augmented self-distillation technique to refine user preference representations by incorporating richer interaction data from similar users. Through comprehensive experiments conducted on three authentic datasets using three widely used SRS models, our proposed enhancement framework demonstrates superior performance compared to existing methodologies.
Read more6/3/2024
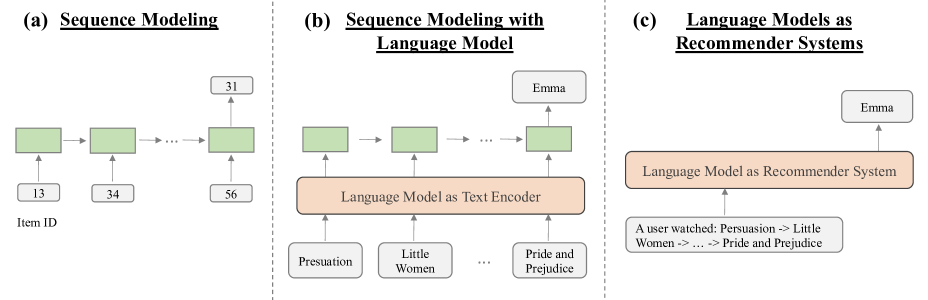
0
Reformulating Sequential Recommendation: Learning Dynamic User Interest with Content-enriched Language Modeling
Junzhe Jiang, Shang Qu, Mingyue Cheng, Qi Liu, Zhiding Liu, Hao Zhang, Rujiao Zhang, Kai Zhang, Rui Li, Jiatong Li, Min Gao
Recommender systems are indispensable in the realm of online applications, and sequential recommendation has enjoyed considerable prevalence due to its capacity to encapsulate the dynamic shifts in user interests. However, previous sequential modeling methods still have limitations in capturing contextual information. The primary reason is the lack of understanding of domain-specific knowledge and item-related textual content. Fortunately, the emergence of powerful language models has unlocked the potential to incorporate extensive world knowledge into recommendation algorithms, enabling them to go beyond simple item attributes and truly understand the world surrounding user preferences. To achieve this, we propose LANCER, which leverages the semantic understanding capabilities of pre-trained language models to generate personalized recommendations. Our approach bridges the gap between language models and recommender systems, resulting in more human-like recommendations. We demonstrate the effectiveness of our approach through a series of experiments conducted on multiple benchmark datasets, showing promising results and providing valuable insights into the influence of our model on sequential recommendation tasks. Furthermore, our experimental codes are publicly available at https://github.com/Gnimixy/lancer.
Read more4/16/2024