EmbSum: Leveraging the Summarization Capabilities of Large Language Models for Content-Based Recommendations

0
💬
Sign in to get full access
Overview
- Content-based recommendation systems are crucial for delivering personalized content to users in the digital world.
- This paper introduces EmbSum, a novel framework that enables offline pre-computations of users and candidate items while capturing the interactions within the user engagement history.
- EmbSum utilizes a pretrained encoder-decoder model and poly-attention layers to derive User Poly-Embedding (UPE) and Content Poly-Embedding (CPE) for calculating relevance scores between users and candidate items.
- EmbSum actively learns the long user engagement histories by generating user-interest summaries with supervision from a large language model (LLM).
- The effectiveness of EmbSum is validated on two datasets from different domains, surpassing state-of-the-art (SoTA) methods with higher accuracy and fewer parameters.
Plain English Explanation
Content-based recommendation systems help deliver personalized content to users by understanding what each user is interested in. The researchers in this paper introduced a new system called EmbSum that can learn about users' interests without requiring a lot of computation power.
EmbSum uses a pre-trained language model and special attention layers to create embeddings, or numerical representations, of both users and the content they might be interested in. These embeddings capture the complex relationships between users and content. EmbSum then uses these embeddings to calculate how relevant each piece of content is to each user, allowing it to make personalized recommendations.
Importantly, EmbSum can learn about users' long-term interests by generating summaries of what each user cares about, using a large language model as a guide. This helps the system understand users' preferences in depth.
The researchers tested EmbSum on two different datasets and found that it outperformed other state-of-the-art recommendation systems in terms of accuracy, while using fewer computational resources. The ability to generate user interest summaries is an added benefit that can further enhance the usefulness of the system.
Technical Explanation
The core innovation of EmbSum is its use of poly-attention layers and a pretrained encoder-decoder model to derive two key embeddings: User Poly-Embedding (UPE) and Content Poly-Embedding (CPE). These embeddings capture the complex interactions between users and the content they engage with.
To learn the long-term user engagement histories, EmbSum actively generates user-interest summaries under the supervision of a large language model (LLM). This allows the system to deeply understand each user's preferences.
The researchers validated the effectiveness of EmbSum on two datasets from different domains. EmbSum was able to outperform state-of-the-art recommendation systems in terms of accuracy, while using fewer parameters.
Critical Analysis
The paper provides a thorough evaluation of EmbSum's performance, but it does not extensively discuss the limitations or potential issues with the approach. For example, the researchers could have explored how EmbSum might handle cold-start scenarios, where new users or items are introduced, or how the system would scale to extremely large-scale recommendation problems.
Additionally, the paper does not compare EmbSum's user-interest summary generation capabilities to other summarization techniques, such as those explored in related work on dialogue summarization and video summarization. Comparing these capabilities more extensively could have provided additional insights into the strengths and weaknesses of EmbSum's summary generation.
Conclusion
EmbSum is a novel content-based recommendation system that leverages pretrained models and poly-attention to effectively capture user-item interactions and generate personalized content recommendations. The ability to actively learn user engagement histories through summary generation is a unique and valuable feature of the system.
While the paper demonstrates the strong performance of EmbSum, further research is needed to explore its scalability and robustness in real-world recommendation scenarios. Comparing the summary generation capabilities to other state-of-the-art techniques could also provide additional insights into the system's versatility and potential applications beyond content recommendation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
EmbSum: Leveraging the Summarization Capabilities of Large Language Models for Content-Based Recommendations
Chiyu Zhang, Yifei Sun, Minghao Wu, Jun Chen, Jie Lei, Muhammad Abdul-Mageed, Rong Jin, Angli Liu, Ji Zhu, Sem Park, Ning Yao, Bo Long
Content-based recommendation systems play a crucial role in delivering personalized content to users in the digital world. In this work, we introduce EmbSum, a novel framework that enables offline pre-computations of users and candidate items while capturing the interactions within the user engagement history. By utilizing the pretrained encoder-decoder model and poly-attention layers, EmbSum derives User Poly-Embedding (UPE) and Content Poly-Embedding (CPE) to calculate relevance scores between users and candidate items. EmbSum actively learns the long user engagement histories by generating user-interest summary with supervision from large language model (LLM). The effectiveness of EmbSum is validated on two datasets from different domains, surpassing state-of-the-art (SoTA) methods with higher accuracy and fewer parameters. Additionally, the model's ability to generate summaries of user interests serves as a valuable by-product, enhancing its usefulness for personalized content recommendations.
Read more8/20/2024
0
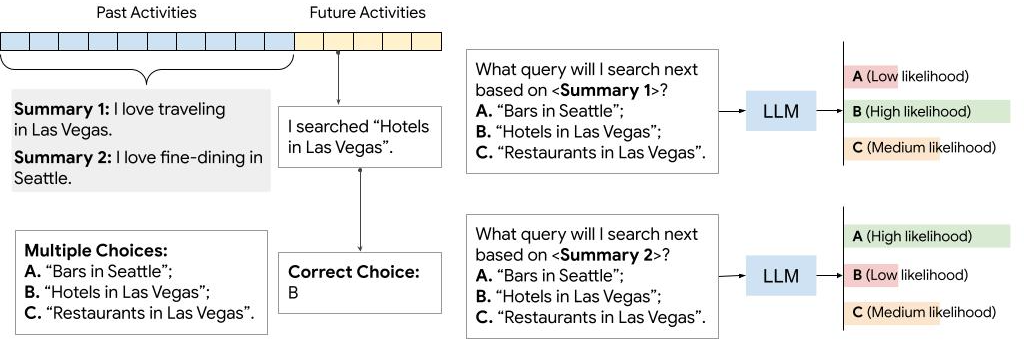
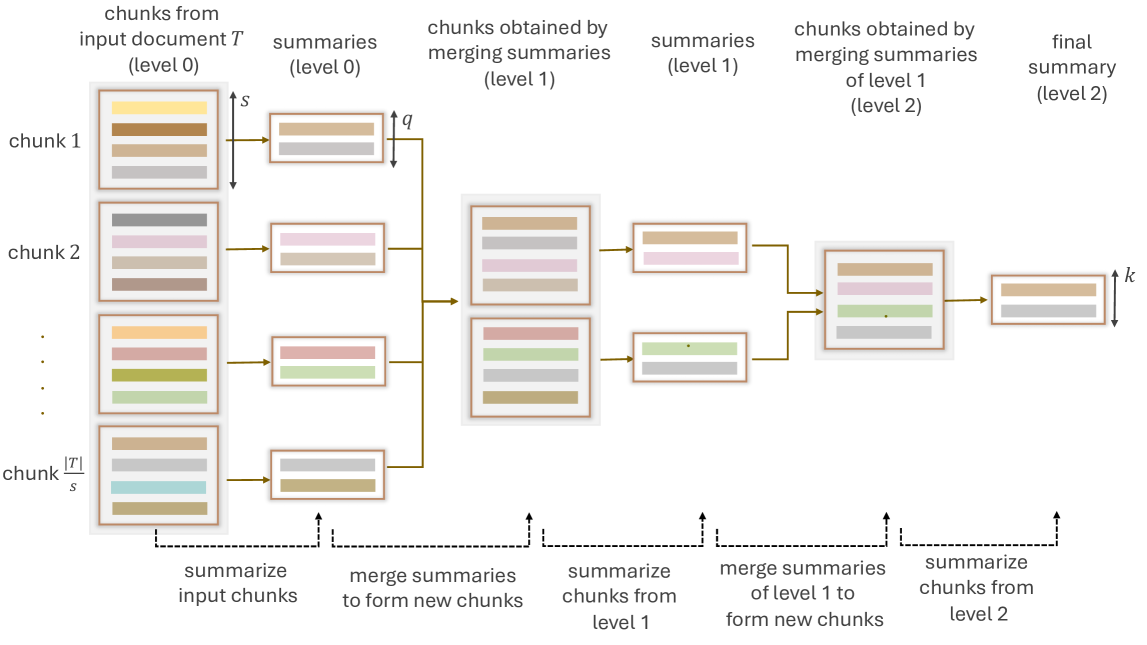
UserSumBench: A Benchmark Framework for Evaluating User Summarization Approaches
Chao Wang, Neo Wu, Lin Ning, Jiaxing Wu, Luyang Liu, Jun Xie, Shawn O'Banion, Bradley Green
Large language models (LLMs) have shown remarkable capabilities in generating user summaries from a long list of raw user activity data. These summaries capture essential user information such as preferences and interests, and therefore are invaluable for LLM-based personalization applications, such as explainable recommender systems. However, the development of new summarization techniques is hindered by the lack of ground-truth labels, the inherent subjectivity of user summaries, and human evaluation which is often costly and time-consuming. To address these challenges, we introduce UserSumBench, a benchmark framework designed to facilitate iterative development of LLM-based summarization approaches. This framework offers two key components: (1) A reference-free summary quality metric. We show that this metric is effective and aligned with human preferences across three diverse datasets (MovieLens, Yelp and Amazon Review). (2) A novel robust summarization method that leverages time-hierarchical summarizer and self-critique verifier to produce high-quality summaries while eliminating hallucination. This method serves as a strong baseline for further innovation in summarization techniques.
Read more9/9/2024
0
LaMSUM: A Novel Framework for Extractive Summarization of User Generated Content using LLMs
Garima Chhikara, Anurag Sharma, V. Gurucharan, Kripabandhu Ghosh, Abhijnan Chakraborty
Large Language Models (LLMs) have demonstrated impressive performance across a wide range of NLP tasks, including summarization. LLMs inherently produce abstractive summaries by paraphrasing the original text, while the generation of extractive summaries - selecting specific subsets from the original text - remains largely unexplored. LLMs have a limited context window size, restricting the amount of data that can be processed at once. We tackle this challenge by introducing LaMSUM, a novel multi-level framework designed to generate extractive summaries from large collections of user-generated text using LLMs. LaMSUM integrates summarization with different voting methods to achieve robust summaries. Extensive evaluation using four popular LLMs (Llama 3, Mixtral, Gemini, GPT-4o) demonstrates that LaMSUM outperforms state-of-the-art extractive summarization methods. Overall, this work represents one of the first attempts to achieve extractive summarization by leveraging the power of LLMs, and is likely to spark further interest within the research community.
Read more8/26/2024

0
SumRecom: A Personalized Summarization Approach by Learning from Users' Feedback
Samira Ghodratnama, Mehrdad Zakershahrak
Existing multi-document summarization approaches produce a uniform summary for all users without considering individuals' interests, which is highly impractical. Making a user-specific summary is a challenging task as it requires: i) acquiring relevant information about a user; ii) aggregating and integrating the information into a user-model; and iii) utilizing the provided information in making the personalized summary. Therefore, in this paper, we propose a solution to a substantial and challenging problem in summarization, i.e., recommending a summary for a specific user. The proposed approach, called SumRecom, brings the human into the loop and focuses on three aspects: personalization, interaction, and learning user's interest without the need for reference summaries. SumRecom has two steps: i) The user preference extractor to capture users' inclination in choosing essential concepts, and ii) The summarizer to discover the user's best-fitted summary based on the given feedback. Various automatic and human evaluations on the benchmark dataset demonstrate the supremacy SumRecom in generating user-specific summaries. Document summarization and Interactive summarization and Personalized summarization and Reinforcement learning.
Read more8/15/2024