Sparse Deep Learning Models with the $ell_1$ Regularization

0
🤿
Sign in to get full access
Overview
- Explores the use of the ℓ₁ regularization technique in deep learning models to achieve sparsity
- Aims to understand the impact of ℓ₁ regularization on model performance and interpretability
- Conducts experiments on various deep learning tasks to analyze the effects of ℓ₁ regularization
Plain English Explanation
The paper investigates the use of the ℓ₁ regularization technique in deep learning models. ℓ₁ regularization is a way to encourage sparsity in the model's parameters, which can lead to more interpretable and efficient models.
The researchers conducted experiments on different deep learning tasks to understand the impact of ℓ₁ regularization on model performance and interpretability. ℓ₁ regularization works by adding a penalty term to the loss function, which encourages the model to use fewer parameters, resulting in a sparse model.
The key idea is that by using ℓ₁ regularization, the deep learning model can become more interpretable, as it will focus on a smaller set of relevant features. This can be particularly useful in applications where understanding the model's decision-making process is important, such as in healthcare or finance.
The paper explores the trade-offs between model performance and sparsity, and provides insights into the effectiveness of ℓ₁ regularization in different deep learning scenarios.
Technical Explanation
The paper presents a study on the use of the ℓ₁ regularization technique in deep learning models to achieve sparsity. ℓ₁ regularization is a form of regularization that encourages the model to use fewer parameters, resulting in a sparse model.
The researchers conducted experiments on various deep learning tasks, including image classification, natural language processing, and time series forecasting, to analyze the effects of ℓ₁ regularization on model performance and interpretability.
The experimental setup involved training deep learning models with and without ℓ₁ regularization, and comparing the results across different metrics, such as accuracy, model size, and interpretability. The authors also explored the trade-offs between model performance and sparsity, and provided insights into the effectiveness of ℓ₁ regularization in different deep learning scenarios.
The results suggest that ℓ₁ regularization can lead to sparser models without significantly compromising their performance, and can also improve the interpretability of the models by focusing on a smaller set of relevant features.
Critical Analysis
The paper provides a comprehensive analysis of the effects of ℓ₁ regularization in deep learning models, but there are a few potential limitations and areas for further research:
- The experiments were conducted on a limited set of tasks and datasets, and it would be valuable to test the approach on a wider range of applications to evaluate its generalizability.
- The paper does not explore the interaction between ℓ₁ regularization and other types of regularization techniques, such as ℓ₂ regularization or dropout, which could provide additional insights.
- The analysis of model interpretability is mostly qualitative, and more quantitative metrics could be used to better understand the impact of ℓ₁ regularization on model transparency.
Overall, the paper presents a valuable contribution to the understanding of sparse deep learning models and the role of ℓ₁ regularization in improving model interpretability, but further research is needed to fully explore the implications and potential limitations of this approach.
Conclusion
This paper explores the use of ℓ₁ regularization in deep learning models to achieve sparsity and improve interpretability. The experimental results suggest that ℓ₁ regularization can lead to sparser models without significantly compromising their performance, and can also enhance the interpretability of the models by focusing on a smaller set of relevant features.
The findings of this research have important implications for the development of more interpretable and efficient deep learning models, particularly in applications where understanding the model's decision-making process is crucial. The paper provides a solid foundation for further research in this area, and encourages the deep learning community to continue exploring the potential of sparse modeling techniques.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤿
0
Sparse Deep Learning Models with the $ell_1$ Regularization
Lixin Shen, Rui Wang, Yuesheng Xu, Mingsong Yan
Sparse neural networks are highly desirable in deep learning in reducing its complexity. The goal of this paper is to study how choices of regularization parameters influence the sparsity level of learned neural networks. We first derive the $ell_1$-norm sparsity-promoting deep learning models including single and multiple regularization parameters models, from a statistical viewpoint. We then characterize the sparsity level of a regularized neural network in terms of the choice of the regularization parameters. Based on the characterizations, we develop iterative algorithms for selecting regularization parameters so that the weight parameters of the resulting deep neural network enjoy prescribed sparsity levels. Numerical experiments are presented to demonstrate the effectiveness of the proposed algorithms in choosing desirable regularization parameters and obtaining corresponding neural networks having both of predetermined sparsity levels and satisfactory approximation accuracy.
Read more8/7/2024
🤿
0
A multiobjective continuation method to compute the regularization path of deep neural networks
Augustina C. Amakor, Konstantin Sonntag, Sebastian Peitz
Sparsity is a highly desired feature in deep neural networks (DNNs) since it ensures numerical efficiency, improves the interpretability of models (due to the smaller number of relevant features), and robustness. For linear models, it is well known that there exists a emph{regularization path} connecting the sparsest solution in terms of the $ell^1$ norm, i.e., zero weights and the non-regularized solution. Very recently, there was a first attempt to extend the concept of regularization paths to DNNs by means of treating the empirical loss and sparsity ($ell^1$ norm) as two conflicting criteria and solving the resulting multiobjective optimization problem for low-dimensional DNN. However, due to the non-smoothness of the $ell^1$ norm and the high number of parameters, this approach is not very efficient from a computational perspective for high-dimensional DNNs. To overcome this limitation, we present an algorithm that allows for the approximation of the entire Pareto front for the above-mentioned objectives in a very efficient manner for high-dimensional DNNs with millions of parameters. We present numerical examples using both deterministic and stochastic gradients. We furthermore demonstrate that knowledge of the regularization path allows for a well-generalizing network parametrization. To the best of our knowledge, this is the first algorithm to compute the regularization path for non-convex multiobjective optimization problems (MOPs) with millions of degrees of freedom.
Read more4/1/2024

0
Dual sparse training framework: inducing activation map sparsity via Transformed $ell1$ regularization
Xiaolong Yu, Cong Tian
Although deep convolutional neural networks have achieved rapid development, it is challenging to widely promote and apply these models on low-power devices, due to computational and storage limitations. To address this issue, researchers have proposed techniques such as model compression, activation sparsity induction, and hardware accelerators. This paper presents a method to induce the sparsity of activation maps based on Transformed $ell1$ regularization, so as to improve the research in the field of activation sparsity induction. Further, the method is innovatively combined with traditional pruning, constituting a dual sparse training framework. Compared to previous methods, Transformed $ell1$ can achieve higher sparsity and better adapt to different network structures. Experimental results show that the method achieves improvements by more than 20% in activation map sparsity on most models and corresponding datasets without compromising the accuracy. Specifically, it achieves a 27.52% improvement for ResNet18 on the ImageNet dataset, and a 44.04% improvement for LeNet5 on the MNIST dataset. In addition, the dual sparse training framework can greatly reduce the computational load and provide potential for reducing the required storage during runtime. Specifically, the ResNet18 and ResNet50 models obtained by the dual sparse training framework respectively reduce 81.7% and 84.13% of multiplicative floating-point operations, while maintaining accuracy and a low pruning rate.
Read more5/31/2024
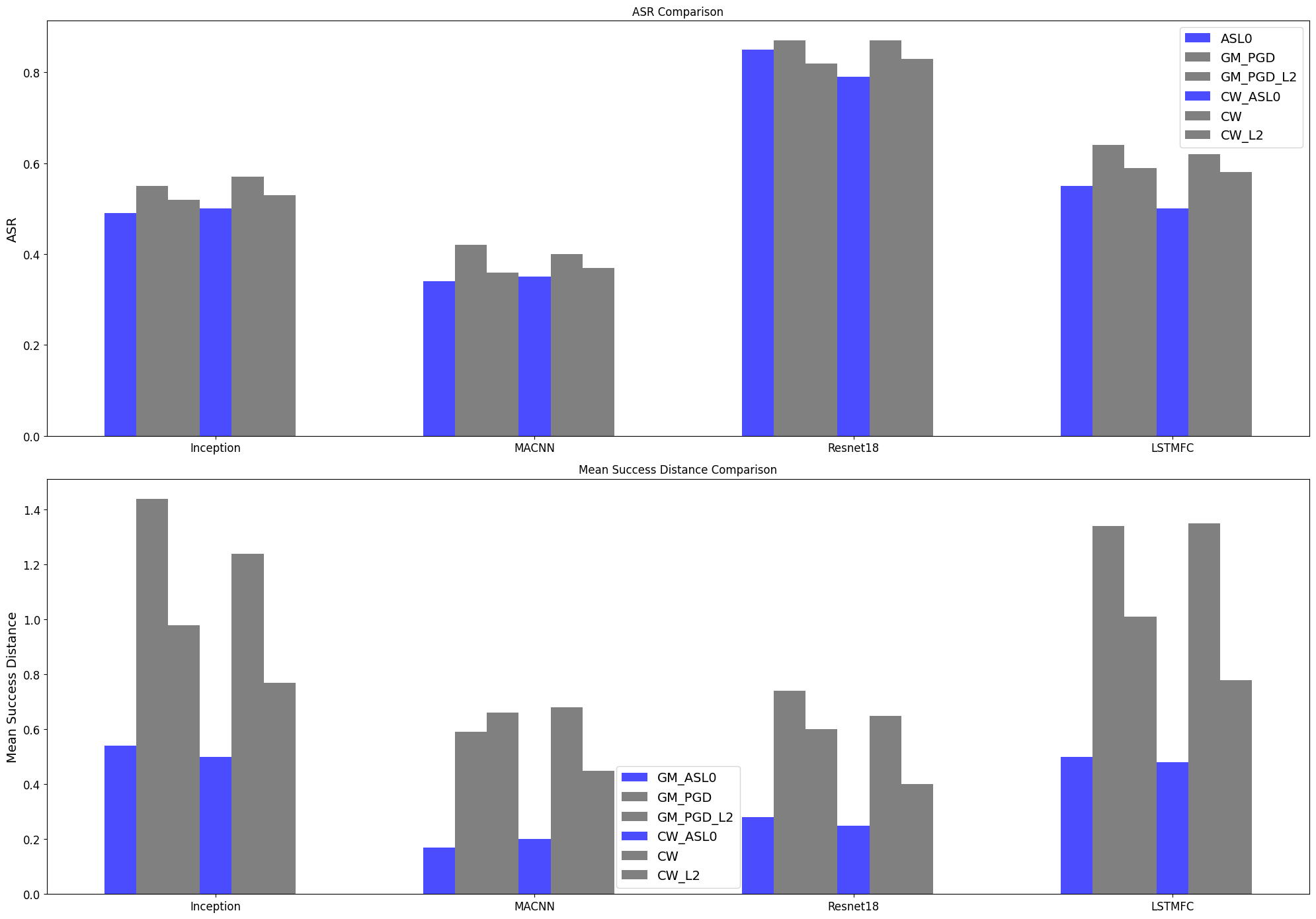
0
Evaluating Model Robustness Using Adaptive Sparse L0 Regularization
Weiyou Liu, Zhenyang Li, Weitong Chen
Deep Neural Networks have demonstrated remarkable success in various domains but remain susceptible to adversarial examples, which are slightly altered inputs designed to induce misclassification. While adversarial attacks typically optimize under Lp norm constraints, attacks based on the L0 norm, prioritising input sparsity, are less studied due to their complex and non convex nature. These sparse adversarial examples challenge existing defenses by altering a minimal subset of features, potentially uncovering more subtle DNN weaknesses. However, the current L0 norm attack methodologies face a trade off between accuracy and efficiency either precise but computationally intense or expedient but imprecise. This paper proposes a novel, scalable, and effective approach to generate adversarial examples based on the L0 norm, aimed at refining the robustness evaluation of DNNs against such perturbations.
Read more8/29/2024