Dual sparse training framework: inducing activation map sparsity via Transformed $ell1$ regularization

0

Sign in to get full access
Overview
- Introduces a "Dual Sparse Training Framework" (DSTF) to induce sparsity in neural network activation maps
- Utilizes a novel Transformed L1 regularization technique to encourage sparsity during training
- Aims to achieve efficient inference through sparse activations without compromising model performance
Plain English Explanation
The paper presents a new approach, called the "Dual Sparse Training Framework" (DSTF), to make neural networks more efficient during inference. The key idea is to induce sparsity, or a large number of zeros, in the neural network's activation maps. This means that only a small subset of the neurons in the network are active at any given time, which can lead to faster and more memory-efficient inference.
To achieve this sparsity, the researchers propose a novel regularization technique called "Transformed L1 regularization." This method encourages the network to learn sparse activations during the training process, without compromising the model's overall performance. By introducing this sparsity, the network can run more efficiently on hardware like mobile devices or embedded systems, where computational resources are limited.
The paper builds on previous work in the field of neural network compression and efficient inference, which has explored techniques like structured gradient-based interpretability, entropic sparsification, and contextually-aware thresholding. The DSTF framework aims to provide a new tool in this toolbox for developing more efficient and deployable AI models.
Technical Explanation
The paper introduces the "Dual Sparse Training Framework" (DSTF), which consists of two main components:
-
Transformed L1 Regularization: This is a novel regularization technique that encourages the neural network to learn sparse activation maps during training. The Transformed L1 regularization function is designed to be more effective than traditional L1 regularization in inducing sparsity, while still maintaining model performance.
-
Dual Training Procedure: The DSTF uses a two-stage training process. In the first stage, the model is trained with the Transformed L1 regularization to induce sparsity in the activations. In the second stage, the model is fine-tuned without the regularization, allowing the network to recover any potential loss in performance due to the sparsity constraint.
The researchers evaluate the DSTF framework on several image classification benchmarks, including CIFAR-10, CIFAR-100, and ImageNet. They compare the performance of models trained with DSTF to those trained with standard techniques, as well as other state-of-the-art sparse training methods like multi-objective continuation.
The results show that the DSTF framework is effective in inducing high levels of activation sparsity (up to 90%) without significantly compromising model accuracy. The sparse models also demonstrate improved inference efficiency, with reduced memory footprint and computational requirements.
Critical Analysis
The paper presents a well-designed and thorough study of the DSTF framework. The authors have carefully considered the existing research in neural network compression and efficiency, and have built upon these ideas to develop a novel regularization technique.
One potential limitation of the DSTF approach is that the dual training procedure may be more computationally expensive than single-stage training methods. Additionally, the paper does not provide a detailed analysis of the trade-offs between the level of sparsity and model performance, which could be valuable for practitioners looking to balance these factors.
Further research could explore the applicability of the DSTF framework to different types of neural network architectures, such as transformers or recurrent models, and investigate the robustness of the induced sparsity patterns to various input distributions or fine-tuning tasks.
Conclusion
The "Dual Sparse Training Framework" presented in this paper offers a promising approach for developing efficient and deployable neural network models. By inducing high levels of activation sparsity through the novel Transformed L1 regularization technique, the DSTF can significantly improve inference efficiency without compromising model performance.
This work contributes to the ongoing efforts in the field of neural network compression and efficient inference, providing researchers and practitioners with a new tool to create more resource-constrained AI systems that can be deployed on a wide range of devices, from mobile phones to edge computing platforms.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Dual sparse training framework: inducing activation map sparsity via Transformed $ell1$ regularization
Xiaolong Yu, Cong Tian
Although deep convolutional neural networks have achieved rapid development, it is challenging to widely promote and apply these models on low-power devices, due to computational and storage limitations. To address this issue, researchers have proposed techniques such as model compression, activation sparsity induction, and hardware accelerators. This paper presents a method to induce the sparsity of activation maps based on Transformed $ell1$ regularization, so as to improve the research in the field of activation sparsity induction. Further, the method is innovatively combined with traditional pruning, constituting a dual sparse training framework. Compared to previous methods, Transformed $ell1$ can achieve higher sparsity and better adapt to different network structures. Experimental results show that the method achieves improvements by more than 20% in activation map sparsity on most models and corresponding datasets without compromising the accuracy. Specifically, it achieves a 27.52% improvement for ResNet18 on the ImageNet dataset, and a 44.04% improvement for LeNet5 on the MNIST dataset. In addition, the dual sparse training framework can greatly reduce the computational load and provide potential for reducing the required storage during runtime. Specifically, the ResNet18 and ResNet50 models obtained by the dual sparse training framework respectively reduce 81.7% and 84.13% of multiplicative floating-point operations, while maintaining accuracy and a low pruning rate.
Read more5/31/2024

0
Training-Free Activation Sparsity in Large Language Models
James Liu, Pragaash Ponnusamy, Tianle Cai, Han Guo, Yoon Kim, Ben Athiwaratkun
Activation sparsity can enable practical inference speedups in large language models (LLMs) by reducing the compute and memory-movement required for matrix multiplications during the forward pass. However, existing methods face limitations that inhibit widespread adoption. Some approaches are tailored towards older models with ReLU-based sparsity, while others require extensive continued pre-training on up to hundreds of billions of tokens. This paper describes TEAL, a simple training-free method that applies magnitude-based activation sparsity to hidden states throughout the entire model. TEAL achieves 40-50% model-wide sparsity with minimal performance degradation across Llama-2, Llama-3, and Mistral families, with sizes varying from 7B to 70B. We improve existing sparse kernels and demonstrate wall-clock decoding speed-ups of up to 1.53$times$ and 1.8$times$ at 40% and 50% model-wide sparsity. TEAL is compatible with weight quantization, enabling further efficiency gains.
Read more8/28/2024
🤿
0
Sparse Deep Learning Models with the $ell_1$ Regularization
Lixin Shen, Rui Wang, Yuesheng Xu, Mingsong Yan
Sparse neural networks are highly desirable in deep learning in reducing its complexity. The goal of this paper is to study how choices of regularization parameters influence the sparsity level of learned neural networks. We first derive the $ell_1$-norm sparsity-promoting deep learning models including single and multiple regularization parameters models, from a statistical viewpoint. We then characterize the sparsity level of a regularized neural network in terms of the choice of the regularization parameters. Based on the characterizations, we develop iterative algorithms for selecting regularization parameters so that the weight parameters of the resulting deep neural network enjoy prescribed sparsity levels. Numerical experiments are presented to demonstrate the effectiveness of the proposed algorithms in choosing desirable regularization parameters and obtaining corresponding neural networks having both of predetermined sparsity levels and satisfactory approximation accuracy.
Read more8/7/2024
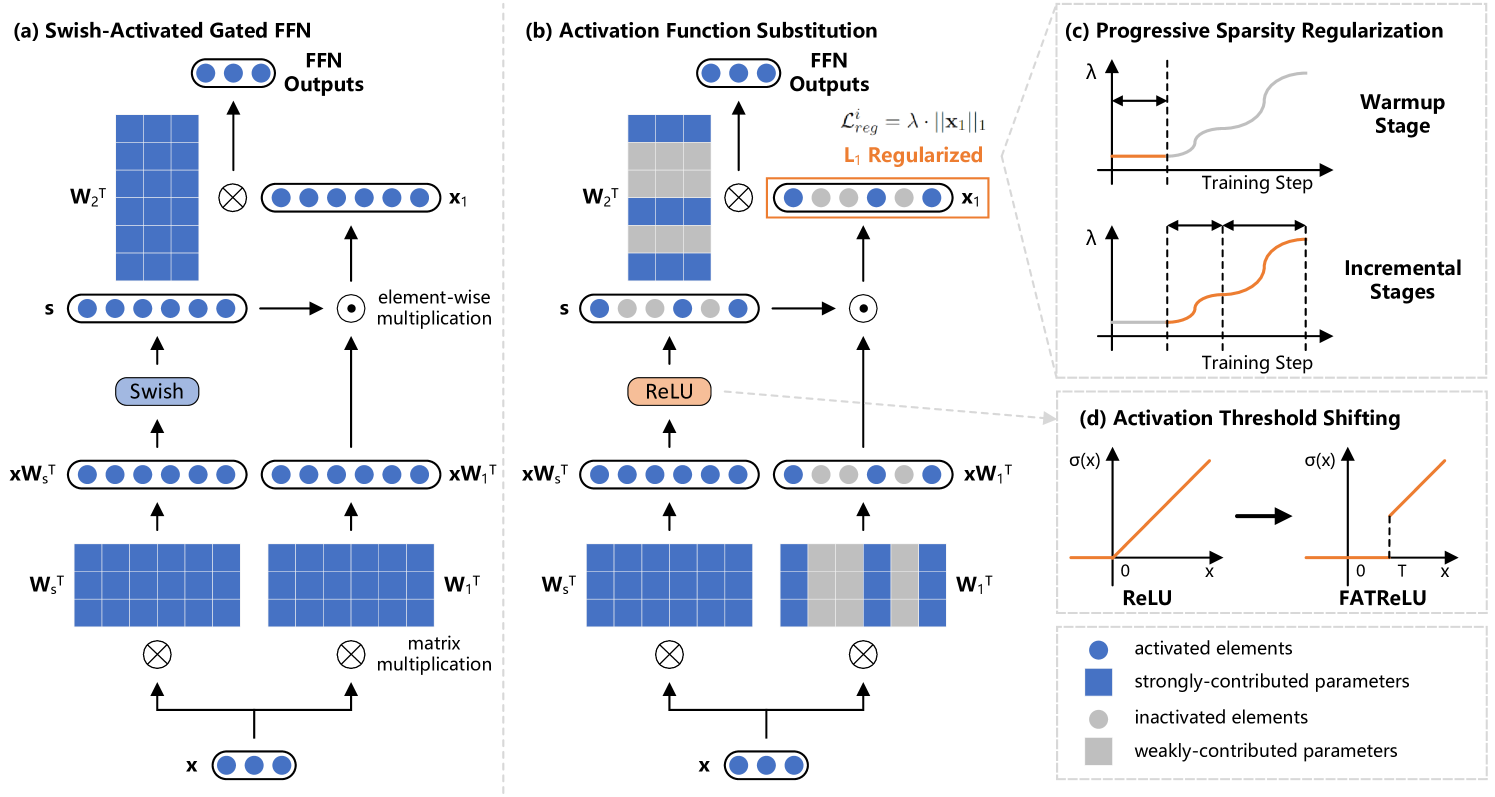
0
ProSparse: Introducing and Enhancing Intrinsic Activation Sparsity within Large Language Models
Chenyang Song, Xu Han, Zhengyan Zhang, Shengding Hu, Xiyu Shi, Kuai Li, Chen Chen, Zhiyuan Liu, Guangli Li, Tao Yang, Maosong Sun
Activation sparsity refers to the existence of considerable weakly-contributed elements among activation outputs. As a prevalent property of the models using the ReLU activation function, activation sparsity has been proven a promising paradigm to boost model inference efficiency. Nevertheless, most large language models (LLMs) adopt activation functions without intrinsic activation sparsity (e.g., GELU and Swish). Some recent efforts have explored introducing ReLU or its variants as the substitutive activation function to help LLMs achieve activation sparsity and inference acceleration, but few can simultaneously obtain high sparsity and comparable model performance. This paper introduces a simple and effective sparsification method named ProSparse to push LLMs for higher activation sparsity while maintaining comparable performance. Specifically, after substituting the activation function of LLMs with ReLU, ProSparse adopts progressive sparsity regularization with a factor smoothly increasing along the multi-stage sine curves. This can enhance activation sparsity and mitigate performance degradation by avoiding radical shifts in activation distributions. With ProSparse, we obtain high sparsity of 89.32% for LLaMA2-7B, 88.80% for LLaMA2-13B, and 87.89% for end-size MiniCPM-1B, respectively, achieving comparable performance to their original Swish-activated versions. These present the most sparsely activated models among open-source LLaMA versions and competitive end-size models, considerably surpassing ReluLLaMA-7B (66.98%) and ReluLLaMA-13B (71.56%). Our inference acceleration experiments further demonstrate the significant practical acceleration potential of LLMs with higher activation sparsity, obtaining up to 4.52$times$ inference speedup.
Read more7/4/2024