Sparse Matrix in Large Language Model Fine-tuning
2405.15525
0
0
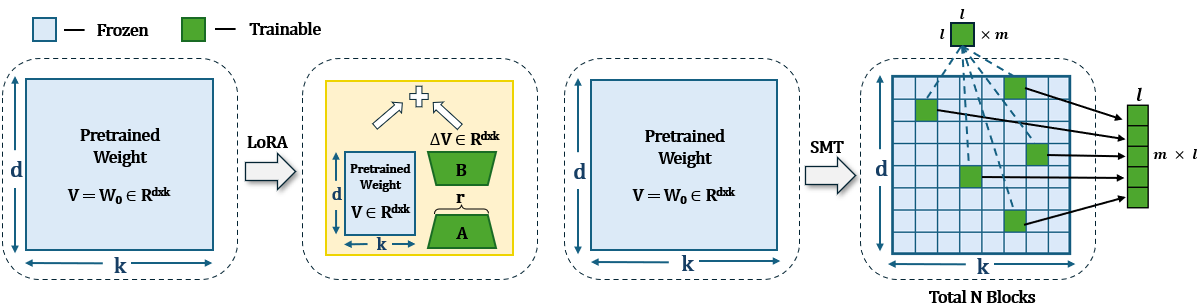
Abstract
LoRA and its variants have become popular parameter-efficient fine-tuning (PEFT) methods due to their ability to avoid excessive computational costs. However, an accuracy gap often exists between PEFT methods and full fine-tuning (FT), and this gap has yet to be systematically studied. In this work, we introduce a method for selecting sparse sub-matrices that aim to minimize the performance gap between PEFT vs. full fine-tuning (FT) while also reducing both fine-tuning computational cost and memory cost. Our Sparse Matrix Tuning (SMT) method begins by identifying the most significant sub-matrices in the gradient update, updating only these blocks during the fine-tuning process. In our experiments, we demonstrate that SMT consistently surpasses other PEFT baseline (e.g. LoRA and DoRA) in fine-tuning popular large language models such as LLaMA across a broad spectrum of tasks, while reducing the GPU memory footprint by 67% compared to FT. We also examine how the performance of LoRA and DoRA tends to plateau and decline as the number of trainable parameters increases, in contrast, our SMT method does not suffer from such issue.
Create account to get full access
Overview
- The paper explores the use of sparse matrices in the fine-tuning of large language models (LLMs) to improve efficiency and performance.
- It compares the sparse matrix approach to other parameter-efficient fine-tuning methods, such as LORA, MORA, and Spafit.
- The authors propose a novel sparse matrix technique and provide experimental results demonstrating its advantages over existing methods.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can understand and generate human-like text. However, fine-tuning these models for specific tasks can be computationally expensive and time-consuming. The researchers in this paper explore using sparse matrices as a way to make the fine-tuning process more efficient.
Sparse matrices are a type of data structure that store only the non-zero elements of a matrix, rather than the full matrix. This can significantly reduce the amount of memory and computational power required, especially for large and complex models like LLMs.
The researchers compare their sparse matrix approach to other parameter-efficient fine-tuning methods, such as LORA, MORA, and Spafit. They find that their sparse matrix technique outperforms these other methods in terms of efficiency and performance on various benchmarks.
Technical Explanation
The paper introduces a novel sparse matrix technique for fine-tuning large language models (LLMs). The key idea is to represent the fine-tuning updates as sparse matrices, which can significantly reduce the number of parameters that need to be learned.
The researchers compare their sparse matrix approach to other parameter-efficient fine-tuning methods, such as LORA, MORA, and Spafit. They conduct extensive experiments on a variety of tasks and datasets, including language modeling, question answering, and text classification.
The results show that the sparse matrix technique outperforms these other methods in terms of both efficiency (e.g., fewer parameters to learn) and performance (e.g., higher accuracy on benchmarks). The authors attribute this advantage to the ability of sparse matrices to capture the important structural information in the fine-tuning updates, while reducing the overall model complexity.
Critical Analysis
The paper presents a promising approach to making the fine-tuning of large language models more efficient and practical. The authors have conducted a thorough empirical evaluation and provided strong evidence for the advantages of their sparse matrix technique.
However, there are a few potential limitations and areas for further research:
- The paper focuses on a limited set of tasks and datasets, and it would be valuable to see how the sparse matrix approach performs on a wider range of applications and benchmarks.
- The authors do not provide a detailed analysis of the characteristics of the tasks and datasets that are best suited for the sparse matrix approach. Understanding these factors could help guide the selection and application of this technique.
- The paper does not address the potential trade-offs or challenges in implementing the sparse matrix approach in real-world systems, such as the integration with existing fine-tuning workflows or the impact on model interpretability.
Overall, the research presented in this paper is a valuable contribution to the field of efficient fine-tuning for large language models. However, as with any research, it is important to consider the limitations and continue to explore additional aspects to fully understand the capabilities and implications of this approach.
Conclusion
The paper demonstrates the effectiveness of using sparse matrices for fine-tuning large language models (LLMs). The researchers have developed a novel sparse matrix technique that outperforms other parameter-efficient fine-tuning methods, such as LORA, MORA, and Spafit, in terms of efficiency and performance.
This research has important implications for the practical deployment of LLMs in real-world applications. By reducing the computational and memory requirements of the fine-tuning process, the sparse matrix approach can make it more accessible and feasible to fine-tune these powerful models for a wider range of tasks and scenarios. This could lead to the development of more efficient and capable AI systems that can be more easily integrated into various industries and domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
RoseLoRA: Row and Column-wise Sparse Low-rank Adaptation of Pre-trained Language Model for Knowledge Editing and Fine-tuning
Haoyu Wang, Tianci Liu, Tuo Zhao, Jing Gao
0
0
Pre-trained language models, trained on large-scale corpora, demonstrate strong generalizability across various NLP tasks. Fine-tuning these models for specific tasks typically involves updating all parameters, which is resource-intensive. Parameter-efficient fine-tuning (PEFT) methods, such as the popular LoRA family, introduce low-rank matrices to learn only a few parameters efficiently. However, during inference, the product of these matrices updates all pre-trained parameters, complicating tasks like knowledge editing that require selective updates. We propose a novel PEFT method, which conducts textbf{r}ow and ctextbf{o}lumn-wise spartextbf{se} textbf{lo}w-textbf{r}ank textbf{a}daptation (RoseLoRA), to address this challenge. RoseLoRA identifies and updates only the most important parameters for a specific task, maintaining efficiency while preserving other model knowledge. By adding a sparsity constraint on the product of low-rank matrices and converting it to row and column-wise sparsity, we ensure efficient and precise model updates. Our theoretical analysis guarantees the lower bound of the sparsity with respective to the matrix product. Extensive experiments on five benchmarks across twenty datasets demonstrate that RoseLoRA outperforms baselines in both general fine-tuning and knowledge editing tasks.
6/18/2024

MLAE: Masked LoRA Experts for Parameter-Efficient Fine-Tuning
Junjie Wang, Guangjing Yang, Wentao Chen, Huahui Yi, Xiaohu Wu, Qicheng Lao
0
0
In response to the challenges posed by the extensive parameter updates required for full fine-tuning of large-scale pre-trained models, parameter-efficient fine-tuning (PEFT) methods, exemplified by Low-Rank Adaptation (LoRA), have emerged. LoRA simplifies the fine-tuning process but may still struggle with a certain level of redundancy in low-rank matrices and limited effectiveness from merely increasing their rank. To address these issues, a natural idea is to enhance the independence and diversity of the learning process for the low-rank matrices. Therefore, we propose Masked LoRA Experts (MLAE), an innovative approach that applies the concept of masking to PEFT. Our method incorporates a cellular decomposition strategy that transforms a low-rank matrix into independent rank-1 submatrices, or ``experts'', thus enhancing independence. Additionally, we introduce a binary mask matrix that selectively activates these experts during training to promote more diverse and anisotropic learning, based on expert-level dropout strategies. Our investigations reveal that this selective activation not only enhances performance but also fosters a more diverse acquisition of knowledge with a marked decrease in parameter similarity among MLAE, significantly boosting the quality of the model while barely increasing the parameter count. Remarkably, MLAE achieves new SOTA performance with an average accuracy score of 78.8% on the VTAB-1k benchmark and 90.9% on the FGVC benchmark, demonstrating superior performance. Our code is available at https://github.com/jie040109/MLAE.
5/30/2024

SVFT: Parameter-Efficient Fine-Tuning with Singular Vectors
Vijay Lingam, Atula Tejaswi, Aditya Vavre, Aneesh Shetty, Gautham Krishna Gudur, Joydeep Ghosh, Alex Dimakis, Eunsol Choi, Aleksandar Bojchevski, Sujay Sanghavi
0
0
Popular parameter-efficient fine-tuning (PEFT) methods, such as LoRA and its variants, freeze pre-trained model weights (W) and inject learnable matrices (Delta W). These (Delta W) matrices are structured for efficient parameterization, often using techniques like low-rank approximations or scaling vectors. However, these methods typically show a performance gap compared to full fine-tuning. Although recent PEFT methods have narrowed this gap, they do so at the cost of additional learnable parameters. We propose SVFT, a simple approach that fundamentally differs from existing methods: the structure imposed on (Delta W) depends on the specific weight matrix (W). Specifically, SVFT updates (W) as a sparse combination of outer products of its singular vectors, training only the coefficients (scales) of these sparse combinations. This approach allows fine-grained control over expressivity through the number of coefficients. Extensive experiments on language and vision benchmarks show that SVFT recovers up to 96% of full fine-tuning performance while training only 0.006 to 0.25% of parameters, outperforming existing methods that only recover up to 85% performance using 0.03 to 0.8% of the trainable parameter budget.
5/31/2024

Sparse is Enough in Fine-tuning Pre-trained Large Language Models
Weixi Song, Zuchao Li, Lefei Zhang, Hai Zhao, Bo Du
0
0
With the prevalence of pre-training-fine-tuning paradigm, how to efficiently adapt the pre-trained model to the downstream tasks has been an intriguing issue. Parameter-Efficient Fine-Tuning (PEFT) methods have been proposed for low-cost adaptation. Although PEFT has demonstrated effectiveness and been widely applied, the underlying principles are still unclear. In this paper, we adopt the PAC-Bayesian generalization error bound, viewing pre-training as a shift of prior distribution which leads to a tighter bound for generalization error. We validate this shift from the perspectives of oscillations in the loss landscape and the quasi-sparsity in gradient distribution. Based on this, we propose a gradient-based sparse fine-tuning algorithm, named Sparse Increment Fine-Tuning (SIFT), and validate its effectiveness on a range of tasks including the GLUE Benchmark and Instruction-tuning. The code is accessible at https://github.com/song-wx/SIFT/.
6/11/2024