RoseLoRA: Row and Column-wise Sparse Low-rank Adaptation of Pre-trained Language Model for Knowledge Editing and Fine-tuning
2406.10777
0
0
Abstract
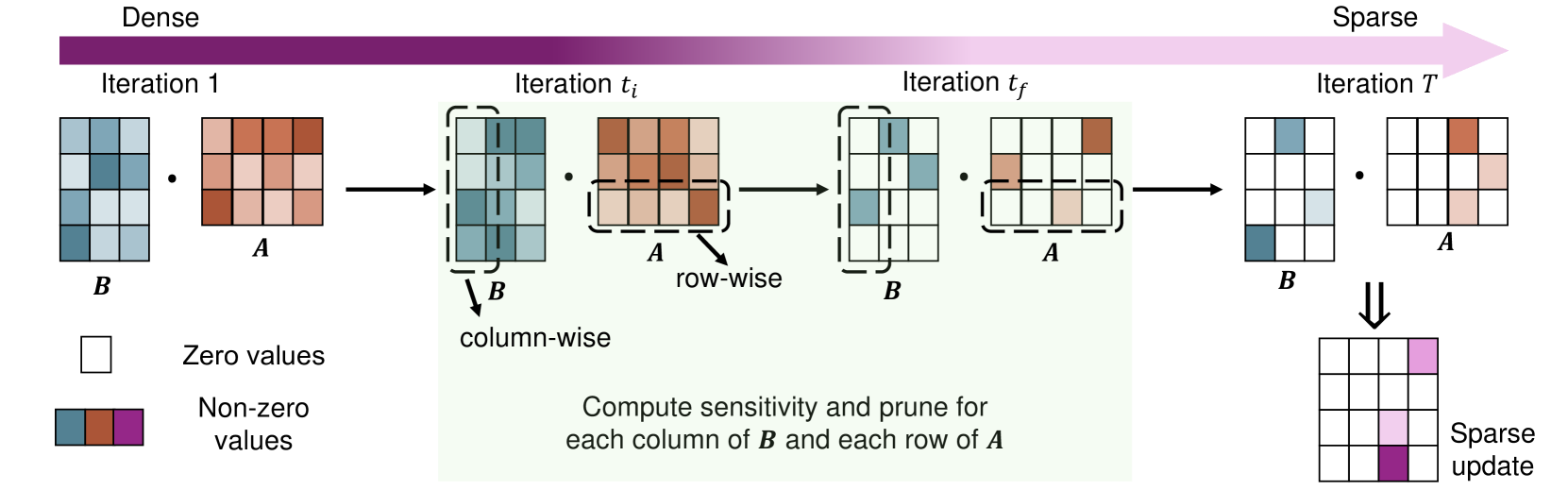
Pre-trained language models, trained on large-scale corpora, demonstrate strong generalizability across various NLP tasks. Fine-tuning these models for specific tasks typically involves updating all parameters, which is resource-intensive. Parameter-efficient fine-tuning (PEFT) methods, such as the popular LoRA family, introduce low-rank matrices to learn only a few parameters efficiently. However, during inference, the product of these matrices updates all pre-trained parameters, complicating tasks like knowledge editing that require selective updates. We propose a novel PEFT method, which conducts textbf{r}ow and ctextbf{o}lumn-wise spartextbf{se} textbf{lo}w-textbf{r}ank textbf{a}daptation (RoseLoRA), to address this challenge. RoseLoRA identifies and updates only the most important parameters for a specific task, maintaining efficiency while preserving other model knowledge. By adding a sparsity constraint on the product of low-rank matrices and converting it to row and column-wise sparsity, we ensure efficient and precise model updates. Our theoretical analysis guarantees the lower bound of the sparsity with respective to the matrix product. Extensive experiments on five benchmarks across twenty datasets demonstrate that RoseLoRA outperforms baselines in both general fine-tuning and knowledge editing tasks.
Create account to get full access
Overview
- The paper proposes a novel method called RoseLoRA for fine-tuning pre-trained language models in a parameter-efficient manner.
- RoseLoRA introduces row-wise and column-wise sparse low-rank adaptations to the model's weights, allowing for targeted updates to specific parts of the model.
- This approach enables efficient knowledge editing and fine-tuning of large language models for various downstream tasks.
Plain English Explanation
Large language models like GPT-3 are powerful but can be challenging to fine-tune for specific tasks. RoseLoRA: Row and Column-wise Sparse Low-rank Adaptation of Pre-trained Language Model for Knowledge Editing and Fine-tuning introduces a new technique called RoseLoRA that aims to make fine-tuning easier and more efficient.
The key idea behind RoseLoRA is to only update certain parts of the language model's weights during fine-tuning, instead of updating the entire model. Specifically, RoseLoRA makes row-wise and column-wise sparse low-rank adaptations to the model's weights. This means it identifies and updates the most important rows and columns in the model's weight matrices, while leaving the rest unchanged.
By focusing on only the most relevant parts of the model, RoseLoRA can fine-tune the language model for a specific task using far fewer parameters than traditional fine-tuning approaches. This makes the process more efficient and can help preserve the model's general knowledge while adapting it to a new task.
The researchers demonstrate that RoseLoRA outperforms other parameter-efficient fine-tuning methods, such as ALORA, LoRA, and MORA, on a variety of natural language processing tasks, including question answering, text generation, and knowledge editing.
Technical Explanation
The RoseLoRA method builds on previous work in parameter-efficient fine-tuning of large language models, such as ALORA, LoRA, and MORA. However, RoseLoRA introduces two key innovations:
-
Row-wise Sparse Low-rank Adaptation: Instead of updating the entire weight matrix during fine-tuning, RoseLoRA identifies and updates only the most important rows in the matrix. This allows the model to focus on updating the most relevant features for the target task.
-
Column-wise Sparse Low-rank Adaptation: Similar to the row-wise approach, RoseLoRA also identifies and updates the most important columns in the weight matrix. This allows the model to update the connections between the most relevant input features and the target task.
The researchers demonstrate that this row-wise and column-wise sparse low-rank adaptation approach outperforms other parameter-efficient fine-tuning methods on a variety of natural language processing tasks, including question answering, text generation, and knowledge editing. They also show that RoseLoRA can effectively edit the knowledge of pre-trained language models, allowing for targeted updates to the model's factual knowledge.
Critical Analysis
The RoseLoRA method represents an interesting and promising approach to parameter-efficient fine-tuning of large language models. By focusing on updating only the most relevant parts of the model, it can achieve strong performance while using far fewer parameters than traditional fine-tuning methods.
However, the paper does not address the potential limitations of this approach. For example, it's unclear how well RoseLoRA would perform on tasks that require more significant changes to the model's underlying knowledge or architecture, beyond just fine-tuning. Additionally, the paper does not explore the potential risks or biases that may be introduced by the selective updating of the model's weights.
Further research would be needed to understand the broader applicability and potential limitations of the RoseLoRA method, as well as its implications for the responsible development and deployment of large language models. ShareLORA is another interesting approach in this area that could be compared to RoseLoRA.
Conclusion
The RoseLoRA method represents an important advancement in parameter-efficient fine-tuning of large language models. By introducing row-wise and column-wise sparse low-rank adaptations, it allows for targeted updates to the model's weights, enabling efficient knowledge editing and fine-tuning for a variety of downstream tasks.
The strong performance of RoseLoRA on tasks like question answering, text generation, and knowledge editing suggests that it could be a valuable tool for researchers and practitioners working with large language models. However, further investigation is needed to fully understand the method's limitations and broader implications.
Overall, the RoseLoRA paper contributes to the growing body of research on making large language models more flexible, efficient, and adaptable to specific use cases, which has important implications for the future development and deployment of these powerful AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Sparse Matrix in Large Language Model Fine-tuning
Haoze He, Juncheng Billy Li, Xuan Jiang, Heather Miller
0
0
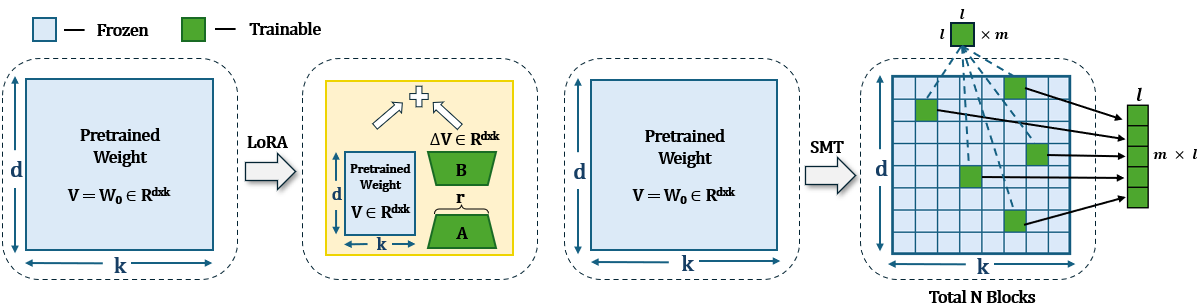
LoRA and its variants have become popular parameter-efficient fine-tuning (PEFT) methods due to their ability to avoid excessive computational costs. However, an accuracy gap often exists between PEFT methods and full fine-tuning (FT), and this gap has yet to be systematically studied. In this work, we introduce a method for selecting sparse sub-matrices that aim to minimize the performance gap between PEFT vs. full fine-tuning (FT) while also reducing both fine-tuning computational cost and memory cost. Our Sparse Matrix Tuning (SMT) method begins by identifying the most significant sub-matrices in the gradient update, updating only these blocks during the fine-tuning process. In our experiments, we demonstrate that SMT consistently surpasses other PEFT baseline (e.g. LoRA and DoRA) in fine-tuning popular large language models such as LLaMA across a broad spectrum of tasks, while reducing the GPU memory footprint by 67% compared to FT. We also examine how the performance of LoRA and DoRA tends to plateau and decline as the number of trainable parameters increases, in contrast, our SMT method does not suffer from such issue.
5/31/2024
ALoRA: Allocating Low-Rank Adaptation for Fine-tuning Large Language Models
Zequan Liu, Jiawen Lyn, Wei Zhu, Xing Tian, Yvette Graham
0
0
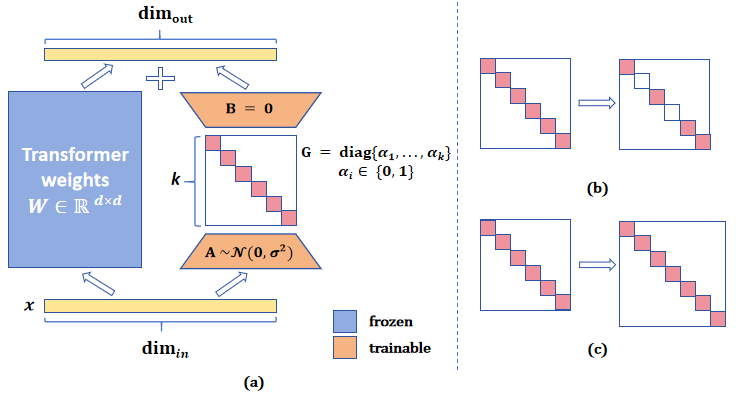
Parameter-efficient fine-tuning (PEFT) is widely studied for its effectiveness and efficiency in the era of large language models. Low-rank adaptation (LoRA) has demonstrated commendable performance as a popular and representative method. However, it is implemented with a fixed intrinsic rank that might not be the ideal setting for the downstream tasks. Recognizing the need for more flexible downstream task adaptation, we extend the methodology of LoRA to an innovative approach we call allocating low-rank adaptation (ALoRA) that enables dynamic adjustments to the intrinsic rank during the adaptation process. First, we propose a novel method, AB-LoRA, that can effectively estimate the importance score of each LoRA rank. Second, guided by AB-LoRA, we gradually prune abundant and negatively impacting LoRA ranks and allocate the pruned LoRA budgets to important Transformer modules needing higher ranks. We have conducted experiments on various tasks, and the experimental results demonstrate that our ALoRA method can outperform the recent baselines with comparable tunable parameters.
4/16/2024
Bayesian-LoRA: LoRA based Parameter Efficient Fine-Tuning using Optimal Quantization levels and Rank Values trough Differentiable Bayesian Gates
Cristian Meo, Ksenia Sycheva, Anirudh Goyal, Justin Dauwels
0
0
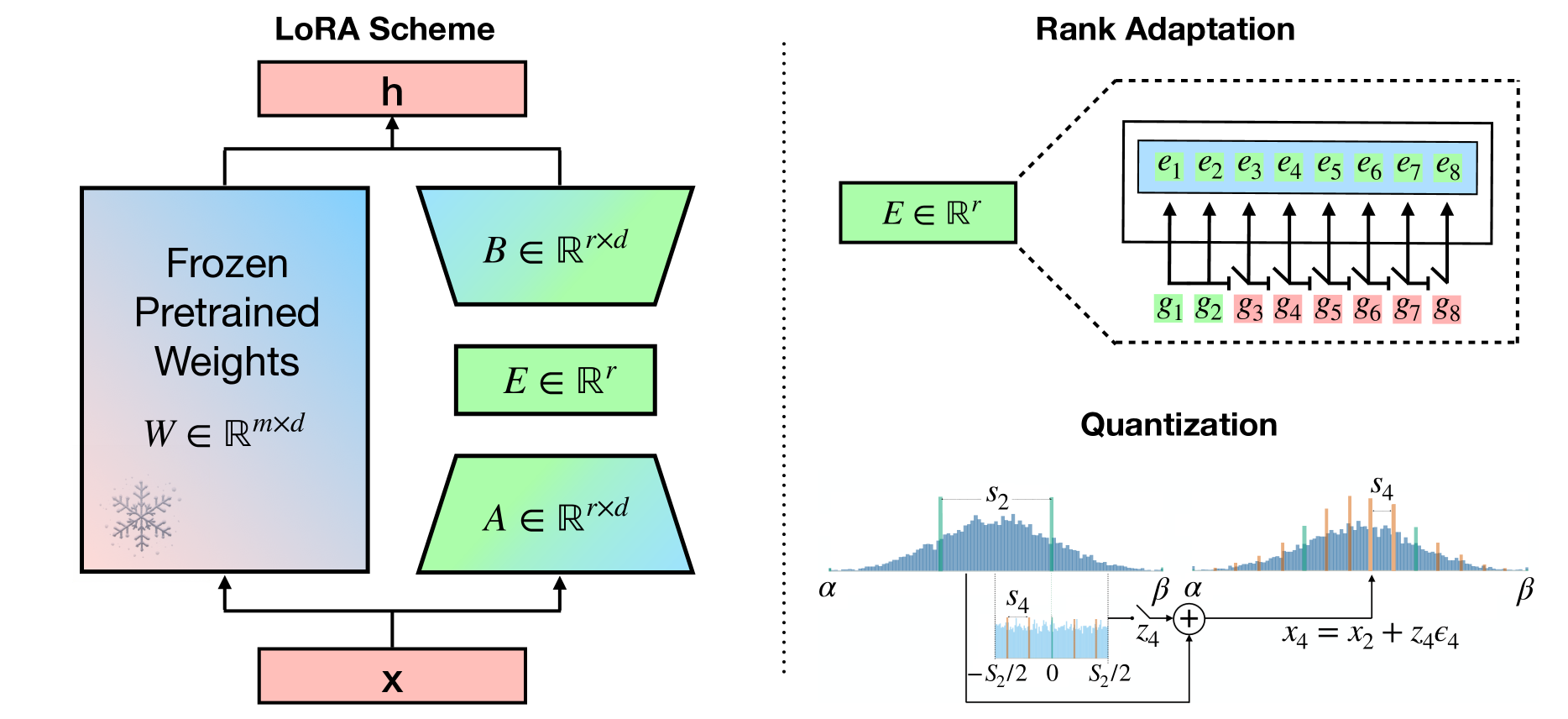
It is a common practice in natural language processing to pre-train a single model on a general domain and then fine-tune it for downstream tasks. However, when it comes to Large Language Models, fine-tuning the entire model can be computationally expensive, resulting in very intensive energy consumption. As a result, several Parameter efficient fine-tuning (PEFT) approaches were recently proposed. One of the most popular approaches is low-rank adaptation (LoRA), where the key insight is decomposing the update weights of the pre-trained model into two low-rank matrices. However, the proposed approaches either use the same rank value across all different weight matrices or do not use any quantization technique, which has been shown to be one of the most important factors when it comes to a model's energy consumption. In this work, we propose Bayesian-LoRA (B-LoRA) which approaches matrix decomposition and quantization from a Bayesian perspective by employing a prior distribution on both quantization levels and rank values of the learned low-rank matrices. As a result, B-LoRA is able to fine-tune a pre-trained model on a specific downstream task, finding the optimal rank values and quantization levels for every low-rank matrix. We validate the proposed model fine-tuning a pre-trained DeBERTaV3 on the GLUE benchmark. Moreover, we compare it to relevant baselines and present both qualitative and quantitative results, showing how the proposed approach is able to learn optimal-rank quantized matrices. B-LoRA performs on par or better than baselines while reducing the total amount of bit operations of roughly 70% with respect to the baselines ones.
6/21/2024
🐍
VB-LoRA: Extreme Parameter Efficient Fine-Tuning with Vector Banks
Yang Li, Shaobo Han, Shihao Ji
0
0
As the adoption of large language models increases and the need for per-user or per-task model customization grows, the parameter-efficient fine-tuning (PEFT) methods, such as low-rank adaptation (LoRA) and its variants, incur substantial storage and transmission costs. To further reduce stored parameters, we introduce a divide-and-share paradigm that breaks the barriers of low-rank decomposition across matrix dimensions, modules and layers by sharing parameters globally via a vector bank. As an instantiation of the paradigm to LoRA, our proposed VB-LoRA composites all the low-rank matrices of LoRA from a shared vector bank with a differentiable top-$k$ admixture module. VB-LoRA achieves extreme parameter efficiency while maintaining comparable or better performance compared to state-of-the-art PEFT methods. Extensive experiments demonstrate the effectiveness of VB-LoRA on natural language understanding, natural language generation, and instruction tuning tasks. When fine-tuning the Llama2-13B model, VB-LoRA only uses 0.4% of LoRA's stored parameters, yet achieves superior results. Our source code is available at https://github.com/leo-yangli/VB-LoRA.
5/29/2024