SVFT: Parameter-Efficient Fine-Tuning with Singular Vectors

0

Sign in to get full access
Overview
• This paper introduces SVFT, a parameter-efficient fine-tuning approach that leverages singular vectors to update a pre-trained model with minimal changes to the original parameters.
• SVFT aims to address the challenge of fine-tuning large language models effectively with limited computational resources and data.
• The key ideas behind SVFT include using singular vectors to capture the most important directions of change in the model's parameters and updating only a small subset of the parameters during fine-tuning.
Plain English Explanation
• Large language models like GPT-3 are powerful but can be costly and difficult to fine-tune on specific tasks. SVFT provides a more efficient way to adapt these models to new applications.
• Instead of updating all the model's parameters during fine-tuning, SVFT focuses on updating only the most important ones. It does this by identifying the "singular vectors" - the key directions of change in the model's parameters.
• By selectively updating a small subset of the parameters based on these singular vectors, SVFT can fine-tune the model with far fewer changes, making the process more parameter-efficient.
• This approach allows the model to retain its original capabilities while being adapted to new tasks, similar to how sparse matrix techniques can be used to fine-tune large language models efficiently.
• The key insight behind SVFT is that the most important changes needed to adapt a pre-trained model can be captured by a small number of parameter updates, rather than modifying the entire model.
Technical Explanation
• SVFT formulates the fine-tuning process as an optimization problem, where the goal is to find the "singular vectors" - the directions of change in the model's parameters that capture the most important information for the target task.
• The authors derive a closed-form solution for computing these singular vectors, which allows them to update only a small subset of the model's parameters during fine-tuning.
• In their experiments, the researchers show that SVFT can achieve comparable or better performance to standard fine-tuning approaches while updating only a fraction of the model's parameters.
• This spectral-based fine-tuning approach leverages the underlying structure of the model's parameters to enable more efficient adaptation.
Critical Analysis
• While SVFT demonstrates impressive performance gains in terms of parameter efficiency, the paper does not fully explore the limitations of the approach. For example, it is unclear how SVFT would scale to extremely large models or how it would perform on tasks that require more substantial changes to the model's parameters.
• Additionally, the paper does not provide a comprehensive comparison to other parameter-efficient fine-tuning techniques, such as adapter-based methods or sparse fine-tuning approaches. A more detailed analysis of the trade-offs between these different techniques would be valuable for researchers and practitioners.
• Overall, SVFT represents an interesting and promising approach to fine-tuning large language models, but further research is needed to fully understand its strengths, weaknesses, and potential applications.
Conclusion
• SVFT offers a novel way to fine-tune large language models more efficiently by focusing on the most important parameter updates, as identified by the model's singular vectors.
• This parameter-efficient fine-tuning technique can help address the challenges of adapting powerful but resource-intensive models to new tasks and domains, potentially making these models more accessible and practical for a wider range of applications.
• While SVFT shows promising results, further research is needed to explore its limitations and compare it to other state-of-the-art fine-tuning approaches. Nonetheless, this work represents an important contribution to the ongoing efforts to make large language models more flexible and cost-effective to use.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SVFT: Parameter-Efficient Fine-Tuning with Singular Vectors
Vijay Lingam, Atula Tejaswi, Aditya Vavre, Aneesh Shetty, Gautham Krishna Gudur, Joydeep Ghosh, Alex Dimakis, Eunsol Choi, Aleksandar Bojchevski, Sujay Sanghavi
Popular parameter-efficient fine-tuning (PEFT) methods, such as LoRA and its variants, freeze pre-trained model weights (W) and inject learnable matrices (Delta W). These (Delta W) matrices are structured for efficient parameterization, often using techniques like low-rank approximations or scaling vectors. However, these methods typically show a performance gap compared to full fine-tuning. Although recent PEFT methods have narrowed this gap, they do so at the cost of additional learnable parameters. We propose SVFT, a simple approach that fundamentally differs from existing methods: the structure imposed on (Delta W) depends on the specific weight matrix (W). Specifically, SVFT updates (W) as a sparse combination of outer products of its singular vectors, training only the coefficients (scales) of these sparse combinations. This approach allows fine-grained control over expressivity through the number of coefficients. Extensive experiments on language and vision benchmarks show that SVFT recovers up to 96% of full fine-tuning performance while training only 0.006 to 0.25% of parameters, outperforming existing methods that only recover up to 85% performance using 0.03 to 0.8% of the trainable parameter budget.
Read more5/31/2024

0
SVFit: Parameter-Efficient Fine-Tuning of Large Pre-Trained Models Using Singular Values
Chengwei Sun, Jiwei Wei, Yujia Wu, Yiming Shi, Shiyuan He, Zeyu Ma, Ning Xie, Yang Yang
Large pre-trained models (LPMs) have demonstrated exceptional performance in diverse natural language processing and computer vision tasks. However, fully fine-tuning these models poses substantial memory challenges, particularly in resource-constrained environments. Parameter-efficient fine-tuning (PEFT) methods, such as LoRA, mitigate this issue by adjusting only a small subset of parameters. Nevertheless, these methods typically employ random initialization for low-rank matrices, which can lead to inefficiencies in gradient descent and diminished generalizability due to suboptimal starting points. To address these limitations, we propose SVFit, a novel PEFT approach that leverages singular value decomposition (SVD) to initialize low-rank matrices using critical singular values as trainable parameters. Specifically, SVFit performs SVD on the pre-trained weight matrix to obtain the best rank-r approximation matrix, emphasizing the most critical singular values that capture over 99% of the matrix's information. These top-r singular values are then used as trainable parameters to scale the fundamental subspaces of the matrix, facilitating rapid domain adaptation. Extensive experiments across various pre-trained models in natural language understanding, text-to-image generation, and image classification tasks reveal that SVFit outperforms LoRA while requiring 16 times fewer trainable parameters.
Read more9/11/2024
🧪
0
Spectral Adapter: Fine-Tuning in Spectral Space
Fangzhao Zhang, Mert Pilanci
Recent developments in Parameter-Efficient Fine-Tuning (PEFT) methods for pretrained deep neural networks have captured widespread interest. In this work, we study the enhancement of current PEFT methods by incorporating the spectral information of pretrained weight matrices into the fine-tuning procedure. We investigate two spectral adaptation mechanisms, namely additive tuning and orthogonal rotation of the top singular vectors, both are done via first carrying out Singular Value Decomposition (SVD) of pretrained weights and then fine-tuning the top spectral space. We provide a theoretical analysis of spectral fine-tuning and show that our approach improves the rank capacity of low-rank adapters given a fixed trainable parameter budget. We show through extensive experiments that the proposed fine-tuning model enables better parameter efficiency and tuning performance as well as benefits multi-adapter fusion. The code will be open-sourced for reproducibility.
Read more5/24/2024
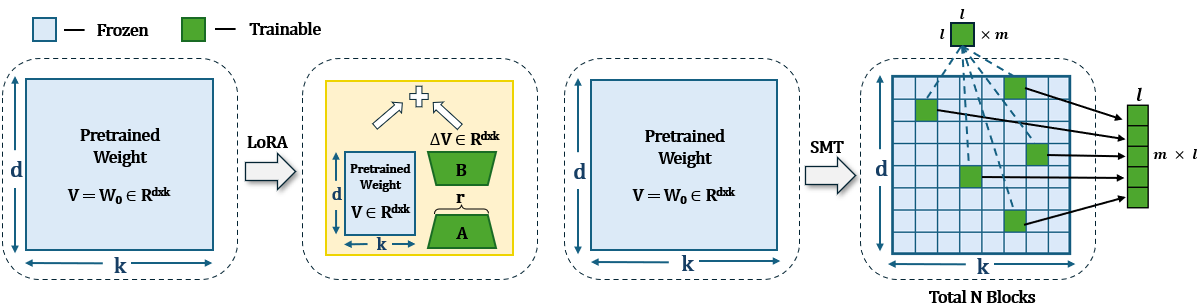
0
Sparse Matrix in Large Language Model Fine-tuning
Haoze He, Juncheng Billy Li, Xuan Jiang, Heather Miller
LoRA and its variants have become popular parameter-efficient fine-tuning (PEFT) methods due to their ability to avoid excessive computational costs. However, an accuracy gap often exists between PEFT methods and full fine-tuning (FT), and this gap has yet to be systematically studied. In this work, we introduce a method for selecting sparse sub-matrices that aim to minimize the performance gap between PEFT vs. full fine-tuning (FT) while also reducing both fine-tuning computational cost and memory cost. Our Sparse Matrix Tuning (SMT) method begins by identifying the most significant sub-matrices in the gradient update, updating only these blocks during the fine-tuning process. In our experiments, we demonstrate that SMT consistently surpasses other PEFT baseline (e.g. LoRA and DoRA) in fine-tuning popular large language models such as LLaMA across a broad spectrum of tasks, while reducing the GPU memory footprint by 67% compared to FT. We also examine how the performance of LoRA and DoRA tends to plateau and decline as the number of trainable parameters increases, in contrast, our SMT method does not suffer from such issue.
Read more5/31/2024