Sparsity-Agnostic Linear Bandits with Adaptive Adversaries

0
Sign in to get full access
Overview
- This paper proposes a new algorithm for linear bandits in non-stochastic settings with adaptive adversaries.
- The algorithm, called Sparsity-Agnostic Linear Bandits (SALB), achieves near-optimal regret bounds without requiring prior knowledge of the sparsity of the optimal action.
- The authors also introduce a new adversarial setting where the reward function can change adaptively based on the agent's past actions, making the problem more challenging.
Plain English Explanation
In the world of machine learning, the linear bandit problem is a popular task where an agent tries to maximize their rewards by choosing actions from a set of options. The agent receives feedback in the form of a reward, and their goal is to learn the best action over time.
This paper tackles a specific variant of the linear bandit problem, where the reward function can change adaptively based on the agent's past actions. This is a more challenging scenario than the typical linear bandit problem, as the agent needs to constantly adapt to these changing conditions.
The authors propose a new algorithm called Sparsity-Agnostic Linear Bandits (SALB) that can achieve near-optimal regret bounds without requiring any prior knowledge about the sparsity of the optimal action. Sparsity refers to the number of non-zero elements in the vector defining the optimal action.
Imagine you're running an online store and want to recommend products to your customers. The linear bandit problem would be trying to learn the best set of features to recommend based on customer feedback. With adaptive adversaries, the customers' preferences could change over time, making it harder to keep up. The SALB algorithm proposed in this paper could help you adapt to these changing preferences without needing to know exactly how many features are most important.
Technical Explanation
The authors consider a linear bandit problem with an adaptive adversary, where the reward function can change based on the agent's past actions. This setting is more challenging than the standard linear bandit problem, as the agent needs to adapt to these changing conditions.
The proposed SALB algorithm uses a novel approach to handle the adaptive adversary without requiring any prior knowledge about the sparsity of the optimal action. Specifically, SALB employs a combination of optimistic and pessimistic estimates of the reward function to balance exploration and exploitation.
The authors prove that SALB achieves near-optimal regret bounds in this adaptive adversarial setting, matching the known lower bounds for linear bandits up to logarithmic factors. This is a significant improvement over previous algorithms that required prior knowledge of the sparsity.
The key technical contributions of this paper include the SALB algorithm design, the regret analysis, and the introduction of the adaptive adversarial setting for linear bandits.
Critical Analysis
The authors acknowledge that their setting with adaptive adversaries is more challenging than the standard linear bandit problem. While the SALB algorithm achieves strong theoretical guarantees, it would be interesting to see how it performs in practical applications and how it compares to other approaches that may be more robust to changing environments.
Additionally, the authors do not discuss potential limitations or caveats of their approach. For example, it's unclear how the SALB algorithm would scale to very high-dimensional settings or how sensitive it is to the underlying assumptions of the problem.
Further research could explore the performance of SALB in more varied and realistic scenarios, as well as investigate potential extensions or modifications to improve its practical applicability.
Conclusion
This paper presents a novel algorithm called Sparsity-Agnostic Linear Bandits (SALB) that can effectively handle linear bandit problems with adaptive adversaries. By not requiring prior knowledge of the sparsity of the optimal action, SALB achieves near-optimal regret bounds and represents a significant advancement in the field of non-stochastic linear bandits.
The introduction of the adaptive adversarial setting also opens up new avenues for research in this domain, as agents must continuously adapt to changing environments. While the theoretical guarantees of SALB are impressive, further investigation is needed to assess its practical performance and potential limitations.
Overall, this work contributes to the ongoing efforts to develop more robust and efficient algorithms for decision-making under uncertainty, with potential applications in areas like recommendation systems, online advertising, and resource allocation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Sparsity-Agnostic Linear Bandits with Adaptive Adversaries
Tianyuan Jin, Kyoungseok Jang, Nicol`o Cesa-Bianchi
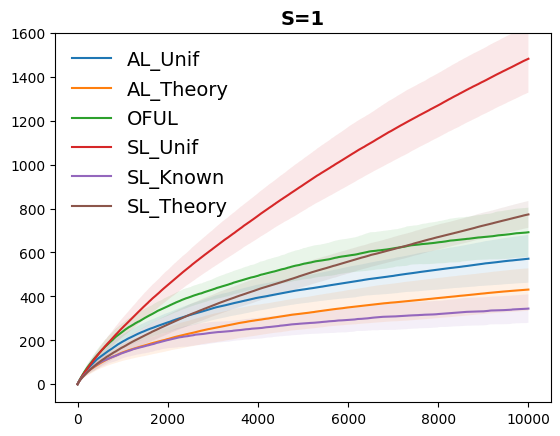
We study stochastic linear bandits where, in each round, the learner receives a set of actions (i.e., feature vectors), from which it chooses an element and obtains a stochastic reward. The expected reward is a fixed but unknown linear function of the chosen action. We study sparse regret bounds, that depend on the number $S$ of non-zero coefficients in the linear reward function. Previous works focused on the case where $S$ is known, or the action sets satisfy additional assumptions. In this work, we obtain the first sparse regret bounds that hold when $S$ is unknown and the action sets are adversarially generated. Our techniques combine online to confidence set conversions with a novel randomized model selection approach over a hierarchy of nested confidence sets. When $S$ is known, our analysis recovers state-of-the-art bounds for adversarial action sets. We also show that a variant of our approach, using Exp3 to dynamically select the confidence sets, can be used to improve the empirical performance of stochastic linear bandits while enjoying a regret bound with optimal dependence on the time horizon.
Read more6/4/2024
🧠
0
Non-stochastic Bandits With Evolving Observations
Yogev Bar-On, Yishay Mansour
We introduce a novel online learning framework that unifies and generalizes pre-established models, such as delayed and corrupted feedback, to encompass adversarial environments where action feedback evolves over time. In this setting, the observed loss is arbitrary and may not correlate with the true loss incurred, with each round updating previous observations adversarially. We propose regret minimization algorithms for both the full-information and bandit settings, with regret bounds quantified by the average feedback accuracy relative to the true loss. Our algorithms match the known regret bounds across many special cases, while also introducing previously unknown bounds.
Read more5/28/2024
⛏️
0
Linear bandits with polylogarithmic minimax regret
Josep Lumbreras, Marco Tomamichel
We study a noise model for linear stochastic bandits for which the subgaussian noise parameter vanishes linearly as we select actions on the unit sphere closer and closer to the unknown vector. We introduce an algorithm for this problem that exhibits a minimax regret scaling as $log^3(T)$ in the time horizon $T$, in stark contrast the square root scaling of this regret for typical bandit algorithms. Our strategy, based on weighted least-squares estimation, achieves the eigenvalue relation $lambda_{min} ( V_t ) = Omega (sqrt{lambda_{max}(V_t ) })$ for the design matrix $V_t$ at each time step $t$ through geometrical arguments that are independent of the noise model and might be of independent interest. This allows us to tightly control the expected regret in each time step to be of the order $O(frac1{t})$, leading to the logarithmic scaling of the cumulative regret.
Read more5/30/2024
🛠️
0
Noise-Adaptive Confidence Sets for Linear Bandits and Application to Bayesian Optimization
Kwang-Sung Jun, Jungtaek Kim
Adapting to a priori unknown noise level is a very important but challenging problem in sequential decision-making as efficient exploration typically requires knowledge of the noise level, which is often loosely specified. We report significant progress in addressing this issue for linear bandits in two respects. First, we propose a novel confidence set that is `semi-adaptive' to the unknown sub-Gaussian parameter $sigma_*^2$ in the sense that the (normalized) confidence width scales with $sqrt{dsigma_*^2 + sigma_0^2}$ where $d$ is the dimension and $sigma_0^2$ is the specified sub-Gaussian parameter (known) that can be much larger than $sigma_*^2$. This is a significant improvement over $sqrt{dsigma_0^2}$ of the standard confidence set of Abbasi-Yadkori et al. (2011), especially when $d$ is large or $sigma_*^2=0$. We show that this leads to an improved regret bound in linear bandits. Second, for bounded rewards, we propose a novel variance-adaptive confidence set that has much improved numerical performance upon prior art. We then apply this confidence set to develop, as we claim, the first practical variance-adaptive linear bandit algorithm via an optimistic approach, which is enabled by our novel regret analysis technique. Both of our confidence sets rely critically on `regret equality' from online learning. Our empirical evaluation in diverse Bayesian optimization tasks shows that our proposed algorithms demonstrate better or comparable performance compared to existing methods.
Read more6/11/2024