Noise-Adaptive Confidence Sets for Linear Bandits and Application to Bayesian Optimization

0
🛠️
Sign in to get full access
Overview
- Addresses the challenge of adapting to unknown noise levels in sequential decision-making problems, such as linear bandits
- Proposes two novel confidence sets that are more robust to unknown noise levels
- Demonstrates improved regret bounds and empirical performance compared to existing methods
Plain English Explanation
Adapting to a priori unknown noise level is a crucial but difficult problem in sequential decision-making tasks like linear bandits. Efficient exploration typically requires knowing the noise level, which is often not well-specified.
This paper makes significant progress in addressing this issue. First, it proposes a new "semi-adaptive" confidence set that scales with the square root of the product of the problem dimension and the unknown noise parameter, plus a specified noise parameter. This is better than the standard approach, especially when the dimension is large or the true noise is very low.
Second, for bounded rewards, the paper introduces a "variance-adaptive" confidence set that performs much better than previous methods. This enables the development of the first practical variance-adaptive linear bandit algorithm using an optimistic approach, enabled by a novel regret analysis technique.
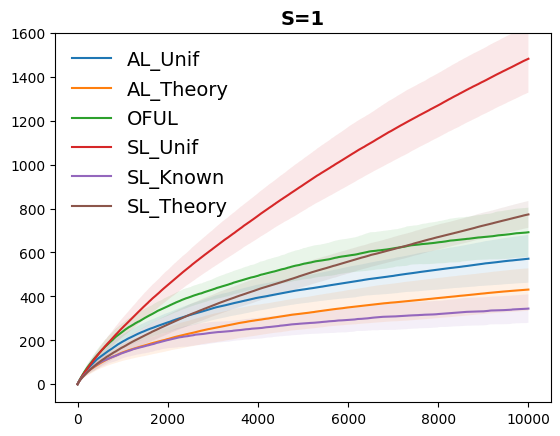
Both confidence sets rely on the "regret equality" concept from online learning. Empirical evaluation on Bayesian optimization tasks shows the proposed algorithms outperform or match existing methods.
Technical Explanation
The paper addresses the challenge of adapting to unknown noise levels in sequential decision-making problems, such as linear bandits. Efficient exploration typically requires knowing the noise level, which is often not well-specified.
First, the authors propose a "semi-adaptive" confidence set that scales with the square root of the product of the problem dimension and the unknown noise parameter, plus a specified noise parameter. This is a significant improvement over the standard approach, which scales with the square root of the product of the dimension and the specified noise parameter.
Second, for bounded rewards, the paper introduces a "variance-adaptive" confidence set that performs much better than previous methods. The authors then use this confidence set to develop the first practical variance-adaptive linear bandit algorithm via an optimistic approach, enabled by a novel regret analysis technique.
Both confidence sets rely critically on the "regret equality" concept from online learning. The empirical evaluation on diverse Bayesian optimization tasks shows the proposed algorithms demonstrate better or comparable performance compared to existing methods.
Critical Analysis
The paper addresses an important challenge in sequential decision-making and makes valuable contributions. However, the authors acknowledge that the proposed methods rely on the "regret equality" concept, which may limit their applicability to other settings.
Additionally, the paper does not provide a comprehensive comparison to all existing methods, and there may be other approaches that could outperform the proposed algorithms in certain scenarios. Further research is needed to understand the broader implications and limitations of this work.
It would be interesting to see the authors explore the application of these techniques to other decision-making problems, such as robust causal bandits with linear models, to assess their generalizability.
Conclusion
This paper presents significant progress in addressing the challenge of adapting to unknown noise levels in sequential decision-making problems, such as linear bandits. The proposed semi-adaptive and variance-adaptive confidence sets, along with the resulting variance-adaptive linear bandit algorithm, demonstrate improved regret bounds and empirical performance compared to existing methods.
These advancements could have important implications for a wide range of applications, from Bayesian optimization to causal inference, where efficient exploration in the face of unknown noise levels is a critical challenge. The work also highlights the value of leveraging concepts from online learning to address complex problems in sequential decision-making.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛠️
0
Noise-Adaptive Confidence Sets for Linear Bandits and Application to Bayesian Optimization
Kwang-Sung Jun, Jungtaek Kim
Adapting to a priori unknown noise level is a very important but challenging problem in sequential decision-making as efficient exploration typically requires knowledge of the noise level, which is often loosely specified. We report significant progress in addressing this issue for linear bandits in two respects. First, we propose a novel confidence set that is `semi-adaptive' to the unknown sub-Gaussian parameter $sigma_*^2$ in the sense that the (normalized) confidence width scales with $sqrt{dsigma_*^2 + sigma_0^2}$ where $d$ is the dimension and $sigma_0^2$ is the specified sub-Gaussian parameter (known) that can be much larger than $sigma_*^2$. This is a significant improvement over $sqrt{dsigma_0^2}$ of the standard confidence set of Abbasi-Yadkori et al. (2011), especially when $d$ is large or $sigma_*^2=0$. We show that this leads to an improved regret bound in linear bandits. Second, for bounded rewards, we propose a novel variance-adaptive confidence set that has much improved numerical performance upon prior art. We then apply this confidence set to develop, as we claim, the first practical variance-adaptive linear bandit algorithm via an optimistic approach, which is enabled by our novel regret analysis technique. Both of our confidence sets rely critically on `regret equality' from online learning. Our empirical evaluation in diverse Bayesian optimization tasks shows that our proposed algorithms demonstrate better or comparable performance compared to existing methods.
Read more6/11/2024
0
Sparsity-Agnostic Linear Bandits with Adaptive Adversaries
Tianyuan Jin, Kyoungseok Jang, Nicol`o Cesa-Bianchi
We study stochastic linear bandits where, in each round, the learner receives a set of actions (i.e., feature vectors), from which it chooses an element and obtains a stochastic reward. The expected reward is a fixed but unknown linear function of the chosen action. We study sparse regret bounds, that depend on the number $S$ of non-zero coefficients in the linear reward function. Previous works focused on the case where $S$ is known, or the action sets satisfy additional assumptions. In this work, we obtain the first sparse regret bounds that hold when $S$ is unknown and the action sets are adversarially generated. Our techniques combine online to confidence set conversions with a novel randomized model selection approach over a hierarchy of nested confidence sets. When $S$ is known, our analysis recovers state-of-the-art bounds for adversarial action sets. We also show that a variant of our approach, using Exp3 to dynamically select the confidence sets, can be used to improve the empirical performance of stochastic linear bandits while enjoying a regret bound with optimal dependence on the time horizon.
Read more6/4/2024
📉
0
Towards Efficient and Optimal Covariance-Adaptive Algorithms for Combinatorial Semi-Bandits
Julien Zhou (Thoth, STATIFY), Pierre Gaillard (Thoth), Thibaud Rahier (SODA, PREMEDICAL), Houssam Zenati (SODA, PREMEDICAL), Julyan Arbel (STATIFY)
We address the problem of stochastic combinatorial semi-bandits, where a player selects among $P$ actions from the power set of a set containing $d$ base items. Adaptivity to the problem's structure is essential in order to obtain optimal regret upper bounds. As estimating the coefficients of a covariance matrix can be manageable in practice, leveraging them should improve the regret. We design ``optimistic'' covariance-adaptive algorithms relying on online estimations of the covariance structure, called OLSUCBC and COSV (only the variances for the latter). They both yields improved gap-free regret. Although COSV can be slightly suboptimal, it improves on computational complexity by taking inspiration from Thompson Sampling approaches. It is the first sampling-based algorithm satisfying a $sqrt{T}$ gap-free regret (up to poly-logs). We also show that in some cases, our approach efficiently leverages the semi-bandit feedback and outperforms bandit feedback approaches, not only in exponential regimes where $Pgg d$ but also when $Pleq d$, which is not covered by existing analyses.
Read more7/4/2024
0
A Unified Confidence Sequence for Generalized Linear Models, with Applications to Bandits
Junghyun Lee, Se-Young Yun, Kwang-Sung Jun
We present a unified likelihood ratio-based confidence sequence (CS) for any (self-concordant) generalized linear models (GLMs) that is guaranteed to be convex and numerically tight. We show that this is on par or improves upon known CSs for various GLMs, including Gaussian, Bernoulli, and Poisson. In particular, for the first time, our CS for Bernoulli has a poly(S)-free radius where S is the norm of the unknown parameter. Our first technical novelty is its derivation, which utilizes a time-uniform PAC-Bayesian bound with a uniform prior/posterior, despite the latter being a rather unpopular choice for deriving CSs. As a direct application of our new CS, we propose a simple and natural optimistic algorithm called OFUGLB applicable to any generalized linear bandits (GLB; Filippi et al. (2010)). Our analysis shows that the celebrated optimistic approach simultaneously attains state-of-the-art regrets for various self-concordant (not necessarily bounded) GLBs, and even poly(S)-free for bounded GLBs, including logistic bandits. The regret analysis, our second technical novelty, follows from combining our new CS with a new proof technique that completely avoids the previously widely used self-concordant control lemma (Faury et al., 2020, Lemma 9). Finally, we verify numerically that OFUGLB significantly outperforms the prior state-of-the-art (Lee et al., 2024) for logistic bandits.
Read more7/22/2024