A Spectral View of Adversarially Robust Features

0
👀
Sign in to get full access
Overview
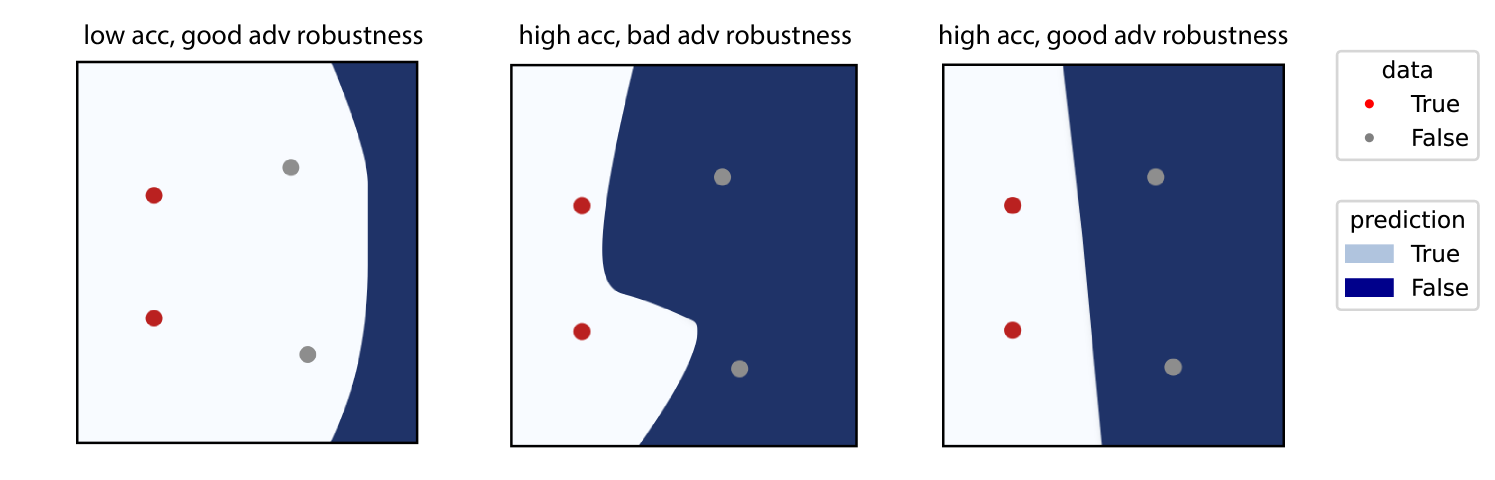
- The paper proposes a new approach to developing adversarially robust features, rather than focusing on learning robust models directly.
- The goal is to find functions that are 1) robust to adversarial perturbations and 2) have significant variation across data points.
- The paper establishes a connection between these adversarially robust features and the spectral properties of the dataset and metric of interest.
- This connection can be used to provide robust features and a lower bound on the robustness of any function with significant variance across the dataset.
- The paper provides empirical evidence that the adversarially robust features can be used to learn a robust and accurate model.
Plain English Explanation
Adversarial perturbations are small, intentional changes to data that can cause machine learning models to make incorrect predictions. Developing models that are robust to these perturbations is challenging. Instead, the researchers propose tackling a simpler problem: finding adversarially robust features.
The idea is to find functions (mathematical operations) that have two key properties:
- They are resistant to adversarial attacks - small changes to the input don't affect the output much.
- They vary a lot across different data points - the output is quite different for different inputs.
The researchers show that there is a close connection between these adversarially robust features and the spectral properties of the dataset and the metric being used. This means they can use the dataset's geometry to find robust features.
These robust features can then be used to learn an accurate and reliable machine learning model. The paper provides experimental evidence demonstrating the effectiveness of this approach.
Technical Explanation
The key idea of the paper is to develop adversarially robust features, rather than focus on learning adversarially robust models directly. Given a dataset and a metric of interest, the goal is to find one or more functions that:
- Are resistant to adversarial perturbations - small changes to the input don't significantly affect the output.
- Exhibit significant variation across the datapoints - the output is quite different for different inputs.
The paper establishes a strong connection between these adversarially robust features and the spectral properties of the dataset and the metric of interest. Specifically, the researchers show that the adversarially robust features correspond to the eigenvectors of the dataset's covariance matrix with the largest eigenvalues.
This connection can be leveraged in two ways:
- It provides a principled way to find adversarially robust features by computing the top eigenvectors of the covariance matrix.
- It gives a lower bound on the robustness of any function that has significant variance across the dataset, based on the spectrum of the covariance matrix.
Finally, the paper presents empirical evidence demonstrating that the adversarially robust features found using this spectral approach can be used to learn an accurate and robust machine learning model. This suggests the approach is a promising direction for developing reliable and secure AI systems.
Critical Analysis
The paper makes a compelling case for the importance of developing adversarially robust features, rather than focusing solely on creating robust models. By establishing a connection to the dataset's spectral properties, the researchers provide a principled approach to finding such features.
However, the paper does not address some potential limitations and areas for further research:
- Scalability: The approach relies on computing the covariance matrix and its eigenvectors, which may become computationally expensive for very large datasets.
- Generalization: The paper demonstrates the effectiveness of the approach on specific datasets and metrics. More research is needed to understand how well the findings generalize to other domains and settings.
- Interpretability: While the spectral approach provides robust features, it may not be clear what these features represent in terms of the underlying data. Improving the interpretability of the robust features could be valuable.
- Theoretical Guarantees: The paper provides empirical evidence of the approach's effectiveness, but more theoretical analysis could help quantify the robustness guarantees provided by the adversarially robust features.
Overall, the paper presents a promising direction for developing reliable and secure AI systems by focusing on the properties of the learned representations, rather than just the final model. Addressing the limitations and exploring further research avenues could help strengthen the impact of this work.
Conclusion
This paper proposes a novel approach to tackling the challenge of developing machine learning models that are robust to adversarial perturbations. Instead of directly learning robust models, the researchers focus on finding adversarially robust features - functions that are resistant to adversarial attacks and exhibit significant variation across the dataset.
The key insight is that these adversarially robust features are closely connected to the spectral properties of the dataset and the metric of interest. This connection provides a principled way to find such features and also offers a lower bound on the robustness of any function with significant variance across the dataset.
The paper's empirical results demonstrate that the adversarially robust features can be effectively leveraged to learn accurate and reliable machine learning models. This suggests the potential of this approach for developing secure and robust AI systems that can withstand adversarial attacks.
While the paper presents a promising direction, there are still opportunities for further research to address scalability, generalization, interpretability, and theoretical guarantees. Nonetheless, the study offers an important contribution to the field of adversarial machine learning and highlights the value of focusing on the properties of learned representations, not just the final model.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👀
0
A Spectral View of Adversarially Robust Features
Shivam Garg, Vatsal Sharan, Brian Hu Zhang, Gregory Valiant
Given the apparent difficulty of learning models that are robust to adversarial perturbations, we propose tackling the simpler problem of developing adversarially robust features. Specifically, given a dataset and metric of interest, the goal is to return a function (or multiple functions) that 1) is robust to adversarial perturbations, and 2) has significant variation across the datapoints. We establish strong connections between adversarially robust features and a natural spectral property of the geometry of the dataset and metric of interest. This connection can be leveraged to provide both robust features, and a lower bound on the robustness of any function that has significant variance across the dataset. Finally, we provide empirical evidence that the adversarially robust features given by this spectral approach can be fruitfully leveraged to learn a robust (and accurate) model.
Read more8/27/2024
0
Spectral regularization for adversarially-robust representation learning
Sheng Yang, Jacob A. Zavatone-Veth, Cengiz Pehlevan
The vulnerability of neural network classifiers to adversarial attacks is a major obstacle to their deployment in safety-critical applications. Regularization of network parameters during training can be used to improve adversarial robustness and generalization performance. Usually, the network is regularized end-to-end, with parameters at all layers affected by regularization. However, in settings where learning representations is key, such as self-supervised learning (SSL), layers after the feature representation will be discarded when performing inference. For these models, regularizing up to the feature space is more suitable. To this end, we propose a new spectral regularizer for representation learning that encourages black-box adversarial robustness in downstream classification tasks. In supervised classification settings, we show empirically that this method is more effective in boosting test accuracy and robustness than previously-proposed methods that regularize all layers of the network. We then show that this method improves the adversarial robustness of classifiers using representations learned with self-supervised training or transferred from another classification task. In all, our work begins to unveil how representational structure affects adversarial robustness.
Read more5/28/2024
✅
0
Adversarial Examples Are Not Real Features
Ang Li, Yifei Wang, Yiwen Guo, Yisen Wang
The existence of adversarial examples has been a mystery for years and attracted much interest. A well-known theory by citet{ilyas2019adversarial} explains adversarial vulnerability from a data perspective by showing that one can extract non-robust features from adversarial examples and these features alone are useful for classification. However, the explanation remains quite counter-intuitive since non-robust features are mostly noise features to humans. In this paper, we re-examine the theory from a larger context by incorporating multiple learning paradigms. Notably, we find that contrary to their good usefulness under supervised learning, non-robust features attain poor usefulness when transferred to other self-supervised learning paradigms, such as contrastive learning, masked image modeling, and diffusion models. It reveals that non-robust features are not really as useful as robust or natural features that enjoy good transferability between these paradigms. Meanwhile, for robustness, we also show that naturally trained encoders from robust features are largely non-robust under AutoAttack. Our cross-paradigm examination suggests that the non-robust features are not really useful but more like paradigm-wise shortcuts, and robust features alone might be insufficient to attain reliable model robustness. Code is available at url{https://github.com/PKU-ML/AdvNotRealFeatures}.
Read more5/7/2024
✨
0
Robust Feature Inference: A Test-time Defense Strategy using Spectral Projections
Anurag Singh, Mahalakshmi Sabanayagam, Krikamol Muandet, Debarghya Ghoshdastidar
Test-time defenses are used to improve the robustness of deep neural networks to adversarial examples during inference. However, existing methods either require an additional trained classifier to detect and correct the adversarial samples, or perform additional complex optimization on the model parameters or the input to adapt to the adversarial samples at test-time, resulting in a significant increase in the inference time compared to the base model. In this work, we propose a novel test-time defense strategy called Robust Feature Inference (RFI) that is easy to integrate with any existing (robust) training procedure without additional test-time computation. Based on the notion of robustness of features that we present, the key idea is to project the trained models to the most robust feature space, thereby reducing the vulnerability to adversarial attacks in non-robust directions. We theoretically characterize the subspace of the eigenspectrum of the feature covariance that is the most robust for a generalized additive model. Our extensive experiments on CIFAR-10, CIFAR-100, tiny ImageNet and ImageNet datasets for several robustness benchmarks, including the state-of-the-art methods in RobustBench show that RFI improves robustness across adaptive and transfer attacks consistently. We also compare RFI with adaptive test-time defenses to demonstrate the effectiveness of our proposed approach.
Read more8/26/2024