Speech-Copilot: Leveraging Large Language Models for Speech Processing via Task Decomposition, Modularization, and Program Generation

0

Sign in to get full access
Overview
- The paper "Speech-Copilot: Leveraging Large Language Models for Speech Processing via Task Decomposition, Modularization, and Program Generation" explores a novel approach to speech processing that leverages large language models (LLMs) through task decomposition, modularization, and program generation.
- The authors propose a system called "Speech-Copilot" that aims to harness the capabilities of LLMs to tackle various speech-related tasks, such as speech recognition, synthesis, and language understanding.
- The key ideas behind Speech-Copilot include breaking down complex speech processing tasks into smaller, modular components, and then generating specialized programs to handle each subtask using LLMs.
Plain English Explanation
The paper is about a new way to work with speech technology using large language models (LLMs). LLMs are powerful AI systems that can understand and generate human-like text. The researchers developed a system called "Speech-Copilot" that uses LLMs to handle different parts of speech processing tasks, like recognizing speech, understanding language, and generating speech.
The main idea is to break down complex speech processing into smaller, more manageable pieces. For each piece, the system generates a specialized program using the LLM. This allows the LLM to focus on what it's best at, rather than trying to do the whole speech processing task at once. By breaking it down and using the LLM in this modular way, the researchers hope to get better performance and more flexibility in speech technology.
Technical Explanation
The paper introduces the "Speech-Copilot" system, which leverages large language models (LLMs) to tackle various speech processing tasks through task decomposition, modularization, and program generation.
The key elements of the Speech-Copilot approach include:
- Task Decomposition: The authors break down complex speech processing tasks, such as speech recognition, synthesis, and language understanding, into smaller, more manageable subtasks.
- Modularization: Each subtask is handled by a specialized module, which is generated using the capabilities of the LLM.
- Program Generation: The LLM is used to generate custom programs for each subtask, allowing the system to flexibly adapt to different speech processing requirements.
The researchers evaluate the Speech-Copilot system on a variety of speech-related benchmarks and demonstrate its effectiveness in leveraging LLMs to achieve state-of-the-art performance. The modular and generative nature of the approach also allows for increased flexibility and adaptability compared to traditional speech processing systems.
Critical Analysis
The paper presents a promising approach to leveraging the capabilities of large language models for speech processing tasks. The authors' focus on task decomposition, modularization, and program generation is a thoughtful way to harness the strengths of LLMs while addressing some of their potential limitations.
One potential caveat is the reliance on the LLM's ability to accurately generate specialized programs for each subtask. While the results suggest this approach is effective, there may be cases where the program generation falters or produces suboptimal solutions, which could impact the overall performance of the system.
Additionally, the paper does not extensively explore the limitations or failure modes of the Speech-Copilot system. Further research into the system's robustness, generalizability, and ability to handle diverse speech processing scenarios would be valuable.
It would also be interesting to see how the Speech-Copilot approach compares to other recent developments in the field, such as Speechverse, Prompting Large Language Models for Audio, VoicePilot, and PolySpeech, which explore different approaches to leveraging LLMs for speech-related tasks.
Conclusion
The "Speech-Copilot" system presented in this paper represents an innovative approach to leveraging large language models for speech processing. By decomposing complex tasks, modularizing the solution, and generating specialized programs, the authors demonstrate a flexible and adaptable system that can achieve state-of-the-art performance.
The modular and generative nature of the Speech-Copilot system has the potential to drive further advancements in speech technology, allowing for more customizable and efficient solutions. As the field continues to evolve, further research on the robustness, generalizability, and comparative performance of this approach will be valuable in assessing its long-term impact.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Speech-Copilot: Leveraging Large Language Models for Speech Processing via Task Decomposition, Modularization, and Program Generation
Chun-Yi Kuan, Chih-Kai Yang, Wei-Ping Huang, Ke-Han Lu, Hung-yi Lee
In this work, we introduce Speech-Copilot, a modular framework for instruction-oriented speech-processing tasks that minimizes human effort in toolset construction. Unlike end-to-end methods using large audio-language models, Speech-Copilot builds speech processing-specific toolsets by analyzing pre-collected task instructions and breaking tasks into manageable sub-tasks. It features a flexible agent based on large language models that performs tasks through program generation. Our approach achieves state-of-the-art performance on the Dynamic-SUPERB benchmark, demonstrating its effectiveness across diverse speech-processing tasks. Key contributions include: 1) developing an innovative framework for speech processing-specific toolset construction, 2) establishing a high-performing agent based on large language models, and 3) offering a new perspective on addressing challenging instruction-oriented speech-processing tasks. Without additional training processes required by end-to-end approaches, our method provides a flexible and extendable solution for a wide range of speech-processing applications.
Read more9/24/2024
0
SpeechCaps: Advancing Instruction-Based Universal Speech Models with Multi-Talker Speaking Style Captioning
Chien-yu Huang, Min-Han Shih, Ke-Han Lu, Chi-Yuan Hsiao, Hung-yi Lee
Instruction-based speech processing is becoming popular. Studies show that training with multiple tasks boosts performance, but collecting diverse, large-scale tasks and datasets is expensive. Thus, it is highly desirable to design a fundamental task that benefits other downstream tasks. This paper introduces a multi-talker speaking style captioning task to enhance the understanding of speaker and prosodic information. We used large language models to generate descriptions for multi-talker speech. Then, we trained our model with pre-training on this captioning task followed by instruction tuning. Evaluation on Dynamic-SUPERB shows our model outperforming the baseline pre-trained only on single-talker tasks, particularly in speaker and emotion recognition. Additionally, tests on a multi-talker QA task reveal that current models struggle with attributes such as gender, pitch, and speaking rate. The code and dataset are available at https://github.com/cyhuang-tw/speechcaps.
Read more8/27/2024
💬
0
SpeechVerse: A Large-scale Generalizable Audio Language Model
Nilaksh Das, Saket Dingliwal, Srikanth Ronanki, Rohit Paturi, Zhaocheng Huang, Prashant Mathur, Jie Yuan, Dhanush Bekal, Xing Niu, Sai Muralidhar Jayanthi, Xilai Li, Karel Mundnich, Monica Sunkara, Sundararajan Srinivasan, Kyu J Han, Katrin Kirchhoff
Large language models (LLMs) have shown incredible proficiency in performing tasks that require semantic understanding of natural language instructions. Recently, many works have further expanded this capability to perceive multimodal audio and text inputs, but their capabilities are often limited to specific fine-tuned tasks such as automatic speech recognition and translation. We therefore develop SpeechVerse, a robust multi-task training and curriculum learning framework that combines pre-trained speech and text foundation models via a small set of learnable parameters, while keeping the pre-trained models frozen during training. The models are instruction finetuned using continuous latent representations extracted from the speech foundation model to achieve optimal zero-shot performance on a diverse range of speech processing tasks using natural language instructions. We perform extensive benchmarking that includes comparing our model performance against traditional baselines across several datasets and tasks. Furthermore, we evaluate the model's capability for generalized instruction following by testing on out-of-domain datasets, novel prompts, and unseen tasks. Our empirical experiments reveal that our multi-task SpeechVerse model is even superior to conventional task-specific baselines on 9 out of the 11 tasks.
Read more6/3/2024
0
VoicePilot: Harnessing LLMs as Speech Interfaces for Physically Assistive Robots
Akhil Padmanabha, Jessie Yuan, Janavi Gupta, Zulekha Karachiwalla, Carmel Majidi, Henny Admoni, Zackory Erickson
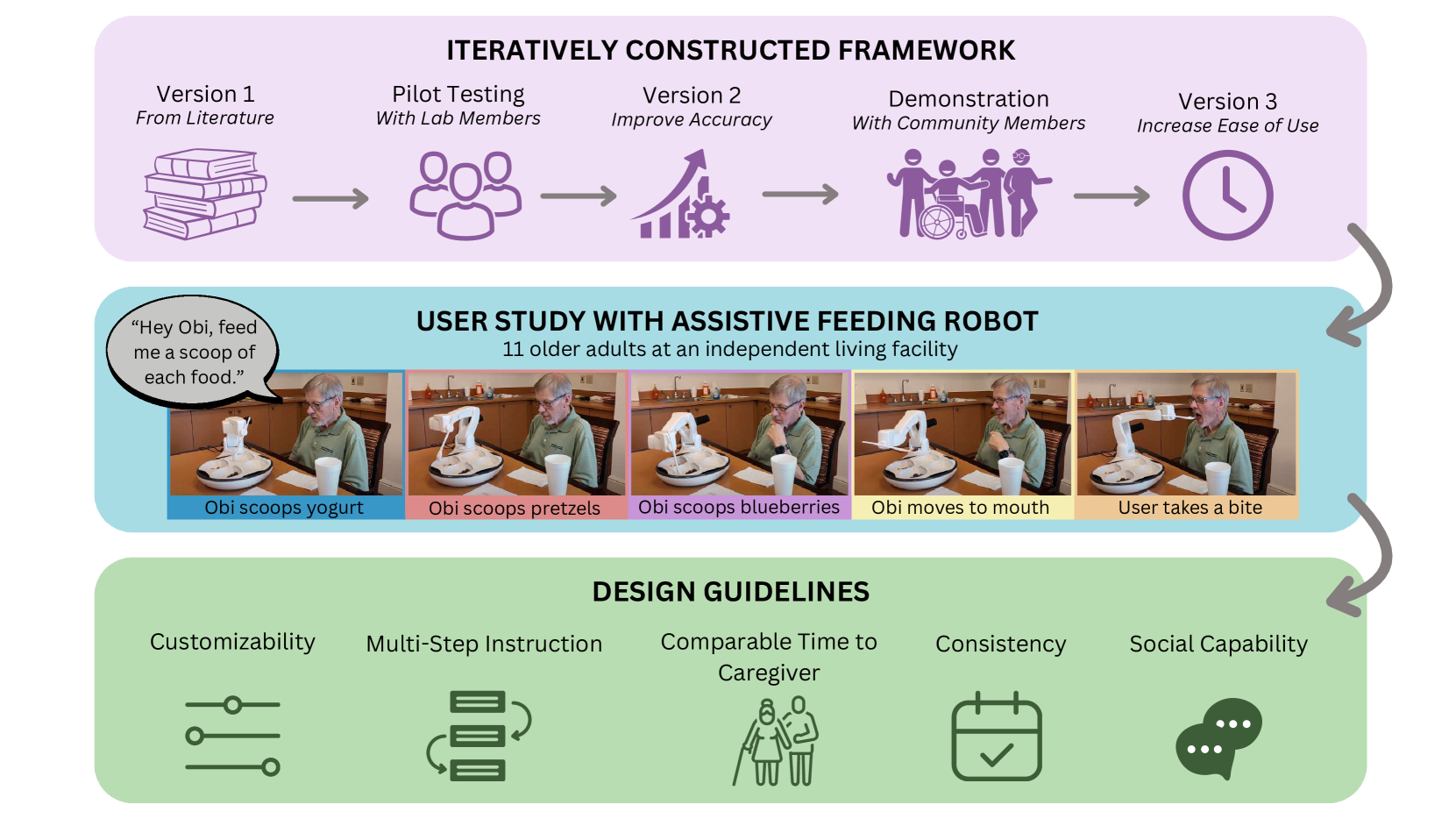
Physically assistive robots present an opportunity to significantly increase the well-being and independence of individuals with motor impairments or other forms of disability who are unable to complete activities of daily living. Speech interfaces, especially ones that utilize Large Language Models (LLMs), can enable individuals to effectively and naturally communicate high-level commands and nuanced preferences to robots. Frameworks for integrating LLMs as interfaces to robots for high level task planning and code generation have been proposed, but fail to incorporate human-centric considerations which are essential while developing assistive interfaces. In this work, we present a framework for incorporating LLMs as speech interfaces for physically assistive robots, constructed iteratively with 3 stages of testing involving a feeding robot, culminating in an evaluation with 11 older adults at an independent living facility. We use both quantitative and qualitative data from the final study to validate our framework and additionally provide design guidelines for using LLMs as speech interfaces for assistive robots. Videos and supporting files are located on our project website: https://sites.google.com/andrew.cmu.edu/voicepilot/
Read more7/18/2024