Speech Emotion Recognition under Resource Constraints with Data Distillation
2406.15119
0
0
🗣️
Abstract
Speech emotion recognition (SER) plays a crucial role in human-computer interaction. The emergence of edge devices in the Internet of Things (IoT) presents challenges in constructing intricate deep learning models due to constraints in memory and computational resources. Moreover, emotional speech data often contains private information, raising concerns about privacy leakage during the deployment of SER models. To address these challenges, we propose a data distillation framework to facilitate efficient development of SER models in IoT applications using a synthesised, smaller, and distilled dataset. Our experiments demonstrate that the distilled dataset can be effectively utilised to train SER models with fixed initialisation, achieving performances comparable to those developed using the original full emotional speech dataset.
Create account to get full access
Overview
- The paper proposes a dataset distillation approach for speech emotion recognition (SER) models, aiming to reduce the size of training datasets while maintaining model performance.
- The researchers investigate the effectiveness of using a generative model to create a smaller, "distilled" dataset that can be used to train SER models with comparable accuracy to models trained on the full dataset.
- The paper compares the performance of several SER model architectures (CNN-6, ResNet-9, and VGG-15) trained on the full dataset and the distilled dataset.
Plain English Explanation
The researchers in this paper wanted to find a way to make speech emotion recognition (SER) models more efficient. SER models are used to detect the emotional state of a person based on their speech, and they typically require large datasets of speech samples to train effectively. The researchers proposed a new method called "dataset distillation" that could create a smaller, more compact dataset that could be used to train SER models with similar accuracy to models trained on the full, larger dataset.
The key idea is to use a generative model to create a smaller, synthetic dataset that captures the essential characteristics of the original, full dataset. This "distilled" dataset can then be used to train SER models, potentially reducing the amount of training data needed and making the models more efficient to deploy. The researchers tested this approach by training several different SER model architectures (CNN-6, ResNet-9, and VGG-15) on both the full dataset and the distilled dataset, and comparing the performance of the models.
Technical Explanation
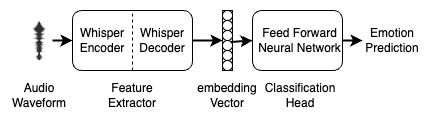
The paper presents a dataset distillation approach for training speech emotion recognition (SER) models. The researchers hypothesized that a smaller, "distilled" dataset created using a generative model could be used to train SER models with comparable performance to models trained on the full dataset.
To test this, the researchers trained several SER model architectures (CNN-6, ResNet-9, and VGG-15) on both the full dataset and the distilled dataset. They compared the unweighted average recall (UAR) performance of the models to assess the effectiveness of the dataset distillation approach.
The results showed a significant gap in UAR performance between the models trained on the full dataset and the models trained on the distilled dataset. The researchers acknowledged that the dataset distillation approach did not provide the expected efficiency benefits or performance improvements, and suggested that simply deploying the CNN-6 model trained on the full dataset may be a more effective strategy.
Critical Analysis
While the researchers' goal of improving the efficiency of SER models is admirable, the results presented in the paper raise some concerns about the validity and effectiveness of the proposed dataset distillation approach.
The large performance gap between the models trained on the full dataset and the distilled dataset (as seen in Tables 2 and 3) suggests that the generative model used to create the distilled dataset was not able to capture the essential characteristics of the original data. This calls into question the underlying assumptions and implementation of the dataset distillation method.
Furthermore, the researchers' acknowledgment that simply deploying the CNN-6 model trained on the full dataset may be a more effective strategy raises doubts about the practical benefits of the proposed approach. If the dataset distillation method does not offer significant efficiency gains or performance improvements, it may not be a worthwhile alternative to using the full dataset.
Additional research is needed to address the limitations and shortcomings of the current dataset distillation approach, such as exploring alternative generative models or dataset distillation techniques that can more effectively capture the nuances of the original data. The researchers may also need to consider the potential challenges of generalizing SER models and the implications of using synthetic data for training.
Conclusion
The paper presents a dataset distillation approach for training speech emotion recognition (SER) models, with the goal of reducing the size of training datasets while maintaining model performance. However, the results show a significant gap in performance between models trained on the full dataset and the distilled dataset, suggesting that the proposed method may not be as effective as the researchers had hoped.
While the motivation behind the research is sound, the practical benefits of the dataset distillation approach are not clearly demonstrated in the current study. Additional research is needed to address the limitations of the method and explore alternative approaches to improving the efficiency and generalization of SER models, such as investigating self-supervised learning techniques or benchmarking on established datasets.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Dataset-Distillation Generative Model for Speech Emotion Recognition
Fabian Ritter-Gutierrez, Kuan-Po Huang, Jeremy H. M Wong, Dianwen Ng, Hung-yi Lee, Nancy F. Chen, Eng Siong Chng
0
0
Deep learning models for speech rely on large datasets, presenting computational challenges. Yet, performance hinges on training data size. Dataset Distillation (DD) aims to learn a smaller dataset without much performance degradation when training with it. DD has been investigated in computer vision but not yet in speech. This paper presents the first approach for DD to speech targeting Speech Emotion Recognition on IEMOCAP. We employ Generative Adversarial Networks (GANs) not to mimic real data but to distil key discriminative information of IEMOCAP that is useful for downstream training. The GAN then replaces the original dataset and can sample custom synthetic dataset sizes. It performs comparably when following the original class imbalance but improves performance by 0.3% absolute UAR with balanced classes. It also reduces dataset storage and accelerates downstream training by 95% in both cases and reduces speaker information which could help for a privacy application.
6/6/2024
What Does it Take to Generalize SER Model Across Datasets? A Comprehensive Benchmark
Adham Ibrahim, Shady Shehata, Ajinkya Kulkarni, Mukhtar Mohamed, Muhammad Abdul-Mageed
0
0
Speech emotion recognition (SER) is essential for enhancing human-computer interaction in speech-based applications. Despite improvements in specific emotional datasets, there is still a research gap in SER's capability to generalize across real-world situations. In this paper, we investigate approaches to generalize the SER system across different emotion datasets. In particular, we incorporate 11 emotional speech datasets and illustrate a comprehensive benchmark on the SER task. We also address the challenge of imbalanced data distribution using over-sampling methods when combining SER datasets for training. Furthermore, we explore various evaluation protocols for adeptness in the generalization of SER. Building on this, we explore the potential of Whisper for SER, emphasizing the importance of thorough evaluation. Our approach is designed to advance SER technology by integrating speaker-independent methods.
6/17/2024
🗣️
Speech Emotion Recognition Using CNN and Its Use Case in Digital Healthcare
Nishargo Nigar
0
0
The process of identifying human emotion and affective states from speech is known as speech emotion recognition (SER). This is based on the observation that tone and pitch in the voice frequently convey underlying emotion. Speech recognition includes the ability to recognize emotions, which is becoming increasingly popular and in high demand. With the help of appropriate factors (such modalities, emotions, intensities, repetitions, etc.) found in the data, my research seeks to use the Convolutional Neural Network (CNN) to distinguish emotions from audio recordings and label them in accordance with the range of different emotions. I have developed a machine learning model to identify emotions from supplied audio files with the aid of machine learning methods. The evaluation is mostly focused on precision, recall, and F1 score, which are common machine learning metrics. To properly set up and train the machine learning framework, the main objective is to investigate the influence and cross-relation of all input and output parameters. To improve the ability to recognize intentions, a key condition for communication, I have evaluated emotions using my specialized machine learning algorithm via voice that would address the emotional state from voice with the help of digital healthcare, bridging the gap between human and artificial intelligence (AI).
6/18/2024

INTERSPEECH 2009 Emotion Challenge Revisited: Benchmarking 15 Years of Progress in Speech Emotion Recognition
Andreas Triantafyllopoulos, Anton Batliner, Simon Rampp, Manuel Milling, Bjorn Schuller
0
0
We revisit the INTERSPEECH 2009 Emotion Challenge -- the first ever speech emotion recognition (SER) challenge -- and evaluate a series of deep learning models that are representative of the major advances in SER research in the time since then. We start by training each model using a fixed set of hyperparameters, and further fine-tune the best-performing models of that initial setup with a grid search. Results are always reported on the official test set with a separate validation set only used for early stopping. Most models score below or close to the official baseline, while they marginally outperform the original challenge winners after hyperparameter tuning. Our work illustrates that, despite recent progress, FAU-AIBO remains a very challenging benchmark. An interesting corollary is that newer methods do not consistently outperform older ones, showing that progress towards `solving' SER is not necessarily monotonic.
6/11/2024