SpeechAct: Towards Generating Whole-body Motion from Speech

0

Sign in to get full access
Overview
- This paper introduces SpeechAct, a novel system that can generate realistic whole-body motion from speech inputs.
- The system uses deep learning techniques to capture the complex relationship between speech and body movements, allowing for the synthesis of natural-looking gestures and full-body animations.
- The research has applications in areas like virtual characters, human-robot interaction, and assistive technologies.
Plain English Explanation
The paper presents a new system called SpeechAct that can create full-body movements and animations from people's speech. This is an important capability because the way we move our bodies is closely tied to how we speak. For example, when we're having a conversation, we naturally gesture with our hands and sway our bodies to emphasize certain points.
The researchers developed a deep learning model that can learn this connection between speech and body movements. By inputting just the audio of someone speaking, the system can then generate realistic animations of that person's entire body moving in sync with their voice. This allows for the creation of virtual characters or robots that can communicate in a more natural, human-like way.
The potential applications of this technology are wide-ranging. It could be used to make video games, animated films, or virtual assistants more lifelike and engaging. It could also help people with disabilities by enabling them to control an avatar or robotic system simply by speaking. Overall, the SpeechAct system represents an important step towards building machines that can understand and respond to human speech and behavior in a more intuitive, holistic way.
Technical Explanation
The SpeechAct system is designed to generate whole-body motion from speech inputs. It uses a deep learning architecture that models the complex relationship between speech acoustics and the resulting body movements.
The key components of the SpeechAct system include:
- A speech encoder that extracts relevant acoustic features from the input audio
- A motion decoder that maps the speech features to realistic 3D body pose and animation parameters
- Attention mechanisms that allow the model to dynamically focus on the most important speech cues when generating the corresponding body motions
The researchers trained and evaluated the SpeechAct model on a large dataset of paired speech audio and full-body motion capture data. Their experiments demonstrate that the system can produce natural-looking, coherent body animations that are well-synchronized with the input speech.
This work builds on previous research in areas like co-speech gesture generation, audio-driven whole-body motion, and speech-driven emotional animation. By taking a more holistic, end-to-end approach, the SpeechAct system is able to generate more comprehensive and realistic animations compared to prior art.
Critical Analysis
The SpeechAct paper presents a compelling approach to the challenge of generating whole-body motion from speech. The researchers acknowledge several limitations in their work, including the need for higher-quality motion capture data, the challenge of modeling individual differences in body language, and the difficulty of evaluating the realism and naturalness of the generated animations.
One potential issue not discussed in the paper is the risk of the system perpetuating biases or stereotypes present in the training data. If the motion capture data used to train the model is not sufficiently diverse, the resulting animations may reflect limited or skewed representations of human body language and expression.
Additionally, while the paper demonstrates the system's ability to generate coherent full-body animations, it would be valuable to further explore the system's versatility and adaptability. For example, it's unclear how well the model would perform on more emotive or exaggerated forms of body language, or how it might be extended to support interactive, real-time applications.
Despite these concerns, the SpeechAct system represents an important step forward in the field of speech-driven animation. By bridging the gap between speech and whole-body motion, it opens up new possibilities for more natural and engaging virtual characters, assistive technologies, and human-machine interfaces.
Conclusion
The SpeechAct paper introduces a novel deep learning system that can generate realistic whole-body motion from speech inputs. This advances the state of the art in areas like co-speech gesture generation, audio-driven animation, and speech-driven emotional motion.
The system's ability to capture the complex relationship between speech and body language has a wide range of potential applications, from virtual characters and human-robot interaction to assistive technologies. While the research has some limitations, it represents an important step towards building machines that can understand and respond to human communication in a more natural, holistic way.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SpeechAct: Towards Generating Whole-body Motion from Speech
Jinsong Zhang, Minjie Zhu, Yuxiang Zhang, Yebin Liu, Kun Li
This paper addresses the problem of generating whole-body motion from speech. Despite great successes, prior methods still struggle to produce reasonable and diverse whole-body motions from speech. This is due to their reliance on suboptimal representations and a lack of strategies for generating diverse results. To address these challenges, we present a novel hybrid point representation to achieve accurate and continuous motion generation, e.g., avoiding foot skating, and this representation can be transformed into an easy-to-use representation, i.e., SMPL-X body mesh, for many applications. To generate whole-body motion from speech, for facial motion, closely tied to the audio signal, we introduce an encoder-decoder architecture to achieve deterministic outcomes. However, for the body and hands, which have weaker connections to the audio signal, we aim to generate diverse yet reasonable motions. To boost diversity in motion generation, we propose a contrastive motion learning method to encourage the model to produce more distinctive representations. Specifically, we design a robust VQ-VAE to learn a quantized motion codebook using our hybrid representation. Then, we regress the motion representation from the audio signal by a translation model employing our contrastive motion learning method. Experimental results validate the superior performance and the correctness of our model. The project page is available for research purposes at http://cic.tju.edu.cn/faculty/likun/projects/SpeechAct.
Read more6/17/2024
0
Towards Variable and Coordinated Holistic Co-Speech Motion Generation
Yifei Liu, Qiong Cao, Yandong Wen, Huaiguang Jiang, Changxing Ding
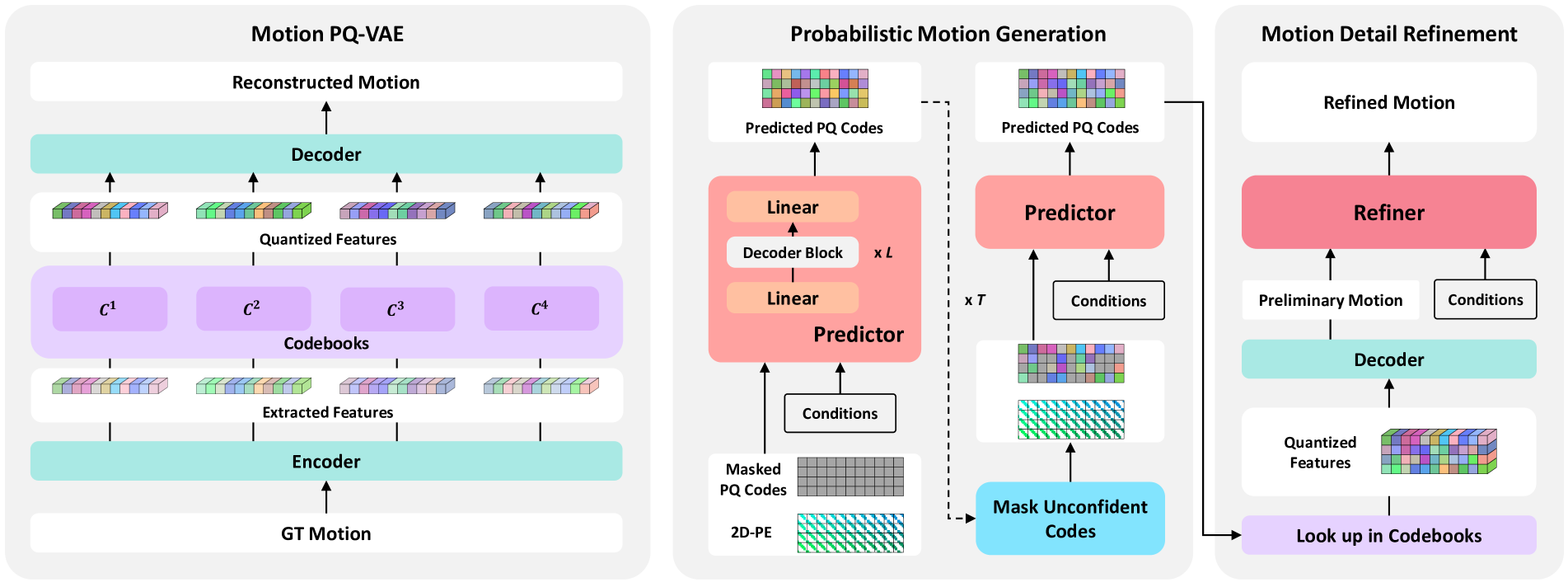
This paper addresses the problem of generating lifelike holistic co-speech motions for 3D avatars, focusing on two key aspects: variability and coordination. Variability allows the avatar to exhibit a wide range of motions even with similar speech content, while coordination ensures a harmonious alignment among facial expressions, hand gestures, and body poses. We aim to achieve both with ProbTalk, a unified probabilistic framework designed to jointly model facial, hand, and body movements in speech. ProbTalk builds on the variational autoencoder (VAE) architecture and incorporates three core designs. First, we introduce product quantization (PQ) to the VAE, which enriches the representation of complex holistic motion. Second, we devise a novel non-autoregressive model that embeds 2D positional encoding into the product-quantized representation, thereby preserving essential structure information of the PQ codes. Last, we employ a secondary stage to refine the preliminary prediction, further sharpening the high-frequency details. Coupling these three designs enables ProbTalk to generate natural and diverse holistic co-speech motions, outperforming several state-of-the-art methods in qualitative and quantitative evaluations, particularly in terms of realism. Our code and model will be released for research purposes at https://feifeifeiliu.github.io/probtalk/.
Read more4/16/2024

0
KMTalk: Speech-Driven 3D Facial Animation with Key Motion Embedding
Zhihao Xu, Shengjie Gong, Jiapeng Tang, Lingyu Liang, Yining Huang, Haojie Li, Shuangping Huang
We present a novel approach for synthesizing 3D facial motions from audio sequences using key motion embeddings. Despite recent advancements in data-driven techniques, accurately mapping between audio signals and 3D facial meshes remains challenging. Direct regression of the entire sequence often leads to over-smoothed results due to the ill-posed nature of the problem. To this end, we propose a progressive learning mechanism that generates 3D facial animations by introducing key motion capture to decrease cross-modal mapping uncertainty and learning complexity. Concretely, our method integrates linguistic and data-driven priors through two modules: the linguistic-based key motion acquisition and the cross-modal motion completion. The former identifies key motions and learns the associated 3D facial expressions, ensuring accurate lip-speech synchronization. The latter extends key motions into a full sequence of 3D talking faces guided by audio features, improving temporal coherence and audio-visual consistency. Extensive experimental comparisons against existing state-of-the-art methods demonstrate the superiority of our approach in generating more vivid and consistent talking face animations. Consistent enhancements in results through the integration of our proposed learning scheme with existing methods underscore the efficacy of our approach. Our code and weights will be at the project website: url{https://github.com/ffxzh/KMTalk}.
Read more9/4/2024

0
Dynamic Motion Synthesis: Masked Audio-Text Conditioned Spatio-Temporal Transformers
Sohan Anisetty, James Hays
Our research presents a novel motion generation framework designed to produce whole-body motion sequences conditioned on multiple modalities simultaneously, specifically text and audio inputs. Leveraging Vector Quantized Variational Autoencoders (VQVAEs) for motion discretization and a bidirectional Masked Language Modeling (MLM) strategy for efficient token prediction, our approach achieves improved processing efficiency and coherence in the generated motions. By integrating spatial attention mechanisms and a token critic we ensure consistency and naturalness in the generated motions. This framework expands the possibilities of motion generation, addressing the limitations of existing approaches and opening avenues for multimodal motion synthesis.
Read more9/4/2024