SpeechEE: A Novel Benchmark for Speech Event Extraction

0
Sign in to get full access
Overview
- A new benchmark called SpeechEE is introduced for evaluating speech event extraction models.
- SpeechEE provides a diverse dataset of spoken language transcripts with annotated event mentions.
- The benchmark aims to spur progress in spoken language understanding and event extraction from audio.
Plain English Explanation
The paper introduces a new benchmark called SpeechEE for evaluating how well machine learning models can extract meaningful events from spoken language. The researchers created a dataset of speech transcripts, where each transcript has been manually annotated to identify key events that are mentioned.
This benchmark is significant because it focuses on understanding speech, rather than just written text. Being able to automatically extract events and other information from audio recordings has many real-world applications, such as in customer service, meeting transcripts, or conversational AI assistants. However, this task is more challenging than working with written text alone, since speech introduces additional complexities like disfluencies, spontaneous phrasing, and background noise.
By providing a standardized dataset and evaluation framework, the SpeechEE benchmark aims to accelerate progress in this area of spoken language understanding. Researchers and companies working on speech-based applications can use SpeechEE to test and compare the performance of their event extraction models.
Technical Explanation
The SpeechEE dataset consists of over 8,000 spoken language transcripts, covering a diverse range of topics and speaker demographics. Each transcript has been manually annotated to identify mentions of specific events, such as meetings, travel, or business transactions. The annotations include the start and end times of each event mention, as well as descriptive labels.
The researchers propose several novel evaluation metrics for assessing how well models perform on this task, going beyond just measuring precision and recall. These metrics consider factors like the temporal alignment of predicted events, as well as the hierarchical structure of events (e.g. a "meeting" event containing multiple sub-events).
The paper also presents baseline results using state-of-the-art speech and language models fine-tuned on the SpeechEE dataset. These experiments demonstrate that while current models can achieve reasonable performance, there is significant room for improvement, especially when it comes to accurately localizing event mentions in the audio stream.
Critical Analysis
The SpeechEE benchmark represents an important step forward in advancing speech-based understanding and information extraction. By providing a standardized dataset and evaluation framework, it can help drive progress in this challenging domain.
However, the authors acknowledge several limitations of the current version of SpeechEE. The dataset is focused on English language transcripts, and may not capture the full diversity of spoken language phenomena. Additionally, the annotated events are relatively coarse-grained - finer-grained event types or attributes could provide additional insights.
Future work could explore ways to expand the benchmark, such as incorporating non-English languages, multi-lingual models, or even end-to-end speech recognition and event extraction. Integrating additional modalities like audio, video, or multiparty interactions could also enhance the realism and complexity of the task.
Conclusion
The SpeechEE benchmark represents a significant contribution to the field of spoken language understanding. By providing a standardized dataset and evaluation framework for speech event extraction, it has the potential to spur rapid advancements in this important area of research and application.
As models become more capable of accurately extracting events and other meaningful information from audio, it will enable a wide range of speech-based applications to become more intelligent, efficient, and user-friendly. This could have far-reaching impacts in domains like customer service, meeting summarization, voice assistants, and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SpeechEE: A Novel Benchmark for Speech Event Extraction
Bin Wang, Meishan Zhang, Hao Fei, Yu Zhao, Bobo Li, Shengqiong Wu, Wei Ji, Min Zhang
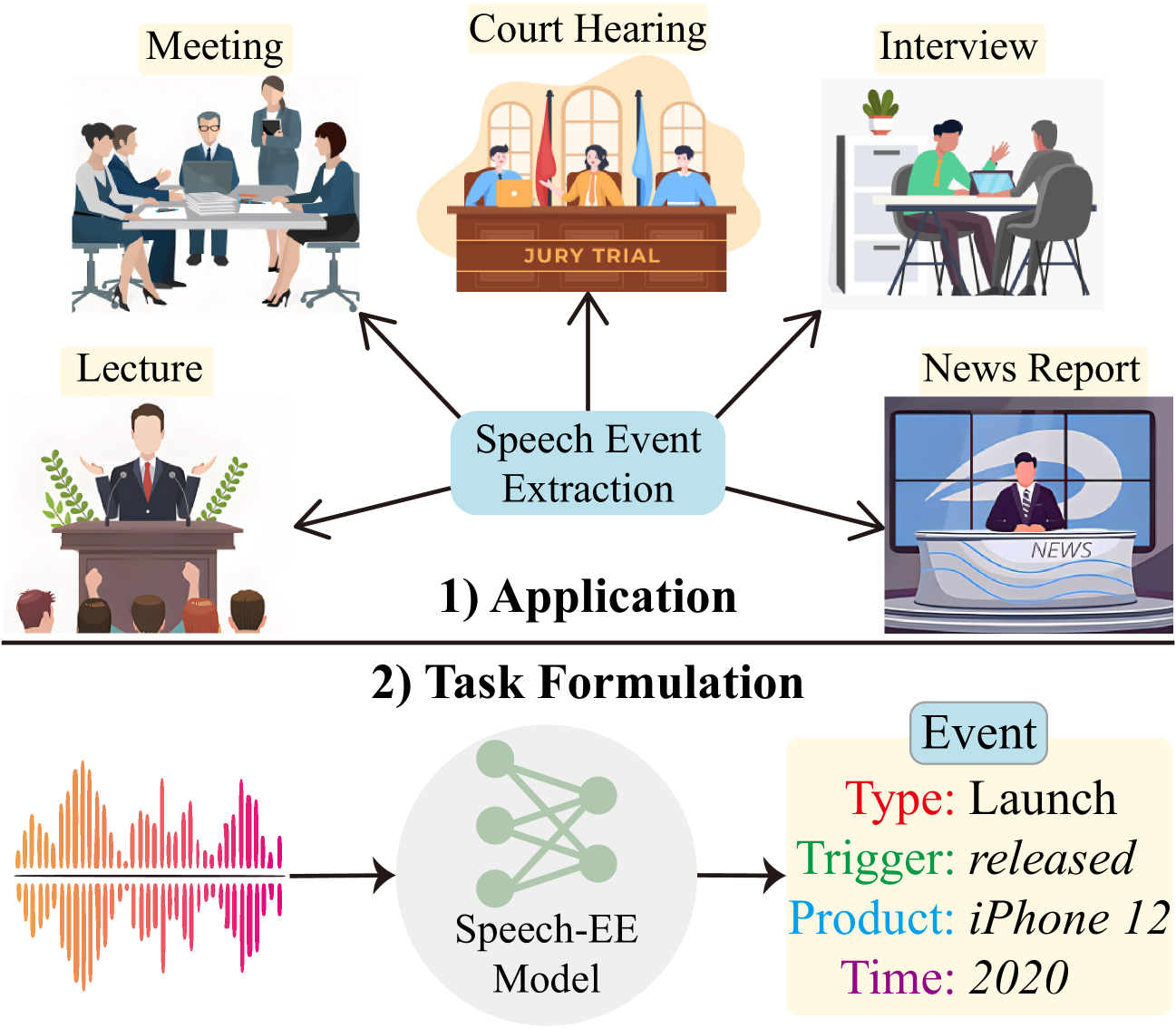
Event extraction (EE) is a critical direction in the field of information extraction, laying an important foundation for the construction of structured knowledge bases. EE from text has received ample research and attention for years, yet there can be numerous real-world applications that require direct information acquisition from speech signals, online meeting minutes, interview summaries, press releases, etc. While EE from speech has remained under-explored, this paper fills the gap by pioneering a SpeechEE, defined as detecting the event predicates and arguments from a given audio speech. To benchmark the SpeechEE task, we first construct a large-scale high-quality dataset. Based on textual EE datasets under the sentence, document, and dialogue scenarios, we convert texts into speeches through both manual real-person narration and automatic synthesis, empowering the data with diverse scenarios, languages, domains, ambiences, and speaker styles. Further, to effectively address the key challenges in the task, we tailor an E2E SpeechEE system based on the encoder-decoder architecture, where a novel Shrinking Unit module and a retrieval-aided decoding mechanism are devised. Extensive experimental results on all SpeechEE subsets demonstrate the efficacy of the proposed model, offering a strong baseline for the task. At last, being the first work on this topic, we shed light on key directions for future research.
Read more8/26/2024
⛏️
0
TextEE: Benchmark, Reevaluation, Reflections, and Future Challenges in Event Extraction
Kuan-Hao Huang, I-Hung Hsu, Tanmay Parekh, Zhiyu Xie, Zixuan Zhang, Premkumar Natarajan, Kai-Wei Chang, Nanyun Peng, Heng Ji
Event extraction has gained considerable interest due to its wide-ranging applications. However, recent studies draw attention to evaluation issues, suggesting that reported scores may not accurately reflect the true performance. In this work, we identify and address evaluation challenges, including inconsistency due to varying data assumptions or preprocessing steps, the insufficiency of current evaluation frameworks that may introduce dataset or data split bias, and the low reproducibility of some previous approaches. To address these challenges, we present TextEE, a standardized, fair, and reproducible benchmark for event extraction. TextEE comprises standardized data preprocessing scripts and splits for 16 datasets spanning eight diverse domains and includes 14 recent methodologies, conducting a comprehensive benchmark reevaluation. We also evaluate five varied large language models on our TextEE benchmark and demonstrate how they struggle to achieve satisfactory performance. Inspired by our reevaluation results and findings, we discuss the role of event extraction in the current NLP era, as well as future challenges and insights derived from TextEE. We believe TextEE, the first standardized comprehensive benchmarking tool, will significantly facilitate future event extraction research.
Read more6/7/2024

0
Towards Better Question Generation in QA-Based Event Extraction
Zijin Hong, Jian Liu
Event Extraction (EE) is an essential information extraction task that aims to extract event-related information from unstructured texts. The paradigm of this task has shifted from conventional classification-based methods to more contemporary question-answering-based (QA-based) approaches. However, in QA-based EE, the quality of the questions dramatically affects the extraction accuracy, and how to generate high-quality questions for QA-based EE remains a challenge. In this work, to tackle this challenge, we suggest four criteria to evaluate the quality of a question and propose a reinforcement learning method, RLQG, for QA-based EE that can generate generalizable, high-quality, and context-dependent questions and provides clear guidance to QA models. The extensive experiments conducted on ACE and RAMS datasets have strongly validated our approach's effectiveness, which also demonstrates its robustness in scenarios with limited training data. The corresponding code of RLQG is released for further research.
Read more7/23/2024
💬
0
A Monte Carlo Language Model Pipeline for Zero-Shot Sociopolitical Event Extraction
Erica Cai, Brendan O'Connor
Current social science efforts automatically populate event databases of who did what to whom? tuples, by applying event extraction (EE) to text such as news. The event databases are used to analyze sociopolitical dynamics between actor pairs (dyads) in, e.g., international relations. While most EE methods heavily rely on rules or supervised learning, emph{zero-shot} event extraction could potentially allow researchers to flexibly specify arbitrary event classes for new research questions. Unfortunately, we find that current zero-shot EE methods, as well as a naive zero-shot approach of simple generative language model (LM) prompting, perform poorly for dyadic event extraction; most suffer from word sense ambiguity, modality sensitivity, and computational inefficiency. We address these challenges with a new fine-grained, multi-stage instruction-following generative LM pipeline, proposing a Monte Carlo approach to deal with, and even take advantage of, nondeterminism of generative outputs. Our pipeline includes explicit stages of linguistic analysis (synonym generation, contextual disambiguation, argument realization, event modality), textit{improving control and interpretability} compared to purely neural methods. This method outperforms other zero-shot EE approaches, and outperforms naive applications of generative LMs by at least 17 F1 percent points. The pipeline's filtering mechanism greatly improves computational efficiency, allowing it to perform as few as 12% of queries that a previous zero-shot method uses. Finally, we demonstrate our pipeline's application to dyadic international relations analysis.
Read more6/4/2024