Towards Better Question Generation in QA-Based Event Extraction

0

Sign in to get full access
Overview
- This paper explores ways to improve the generation of questions in question-answering (QA) based event extraction systems.
- The authors propose several techniques to generate better questions that can help extract more accurate information about events from text.
- The paper evaluates these methods on various event extraction datasets and shows they can outperform existing approaches.
Plain English Explanation
Event extraction is the task of identifying and extracting information about specific events (e.g., a company acquisition, a natural disaster) from text. One approach to this is question-answering (QA)-based event extraction, where the system asks questions about the text to find relevant information.
The quality of the questions generated by the system is crucial to its performance. This paper explores ways to generate better, more contextualized questions that can help extract more complete and accurate details about events.
The authors propose novel techniques that leverage event-related information and cross-document relationships to improve question generation.
By evaluating these methods on standard event extraction datasets, the paper shows they can outperform existing question generation approaches, leading to more reliable and time-aware event extraction.
Technical Explanation
The paper proposes several techniques to generate better questions for QA-based event extraction:
-
Event-Aware Question Generation: The authors incorporate event-related information, such as event types and arguments, into the question generation process to make the questions more relevant and contextualized.
-
Cross-Document Question Generation: The system leverages relationships between events across multiple documents to generate questions that can collect information beyond a single document.
-
Question Ranking and Selection: The authors develop methods to rank and select the most informative questions from the generated set, ensuring the final questions are high-quality and diverse.
The authors evaluate these approaches on standard event extraction datasets, including the ACE 2005 and RAMS datasets. The results show the proposed techniques outperform existing question generation methods, leading to more accurate event extraction.
Critical Analysis
The paper presents a compelling approach to improving question generation for event extraction, which is a crucial step in many real-world applications. The authors thoroughly evaluate their methods and demonstrate clear performance improvements.
However, the paper does not address some potential limitations. For example, the methods may struggle with rare or unusual event types not well-represented in the training data. Additionally, the approach relies on the availability of high-quality event extraction models, which can be challenging to obtain, especially for domain-specific applications.
Further research could explore ways to make the question generation more robust to these challenges, such as by leveraging few-shot or unsupervised learning techniques. Investigating the model's performance on more diverse datasets and real-world scenarios would also help assess its broader applicability.
Conclusion
This paper presents novel techniques to generate better questions for QA-based event extraction systems. By incorporating event-related information and cross-document relationships, the authors show they can produce questions that lead to more accurate and comprehensive event extraction.
The proposed methods represent a significant advancement in the field of event extraction, with potential applications in areas like real-time search, health care, and multi-document analysis. Further research to address the identified limitations could make these techniques even more robust and widely applicable.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Towards Better Question Generation in QA-Based Event Extraction
Zijin Hong, Jian Liu
Event Extraction (EE) is an essential information extraction task that aims to extract event-related information from unstructured texts. The paradigm of this task has shifted from conventional classification-based methods to more contemporary question-answering-based (QA-based) approaches. However, in QA-based EE, the quality of the questions dramatically affects the extraction accuracy, and how to generate high-quality questions for QA-based EE remains a challenge. In this work, to tackle this challenge, we suggest four criteria to evaluate the quality of a question and propose a reinforcement learning method, RLQG, for QA-based EE that can generate generalizable, high-quality, and context-dependent questions and provides clear guidance to QA models. The extensive experiments conducted on ACE and RAMS datasets have strongly validated our approach's effectiveness, which also demonstrates its robustness in scenarios with limited training data. The corresponding code of RLQG is released for further research.
Read more7/23/2024
🎯
0
Asking and Answering Questions to Extract Event-Argument Structures
Md Nayem Uddin, Enfa Rose George, Eduardo Blanco, Steven Corman
This paper presents a question-answering approach to extract document-level event-argument structures. We automatically ask and answer questions for each argument type an event may have. Questions are generated using manually defined templates and generative transformers. Template-based questions are generated using predefined role-specific wh-words and event triggers from the context document. Transformer-based questions are generated using large language models trained to formulate questions based on a passage and the expected answer. Additionally, we develop novel data augmentation strategies specialized in inter-sentential event-argument relations. We use a simple span-swapping technique, coreference resolution, and large language models to augment the training instances. Our approach enables transfer learning without any corpora-specific modifications and yields competitive results with the RAMS dataset. It outperforms previous work, and it is especially beneficial to extract arguments that appear in different sentences than the event trigger. We also present detailed quantitative and qualitative analyses shedding light on the most common errors made by our best model.
Read more4/26/2024
⛏️
0
Event Extraction for Portuguese: A QA-driven Approach using ACE-2005
Lu'is Filipe Cunha, Ricardo Campos, Al'ipio Jorge
Event extraction is an Information Retrieval task that commonly consists of identifying the central word for the event (trigger) and the event's arguments. This task has been extensively studied for English but lags behind for Portuguese, partly due to the lack of task-specific annotated corpora. This paper proposes a framework in which two separated BERT-based models were fine-tuned to identify and classify events in Portuguese documents. We decompose this task into two sub-tasks. Firstly, we use a token classification model to detect event triggers. To extract event arguments, we train a Question Answering model that queries the triggers about their corresponding event argument roles. Given the lack of event annotated corpora in Portuguese, we translated the original version of the ACE-2005 dataset (a reference in the field) into Portuguese, producing a new corpus for Portuguese event extraction. To accomplish this, we developed an automatic translation pipeline. Our framework obtains F1 marks of 64.4 for trigger classification and 46.7 for argument classification setting, thus a new state-of-the-art reference for these tasks in Portuguese.
Read more9/2/2024
0
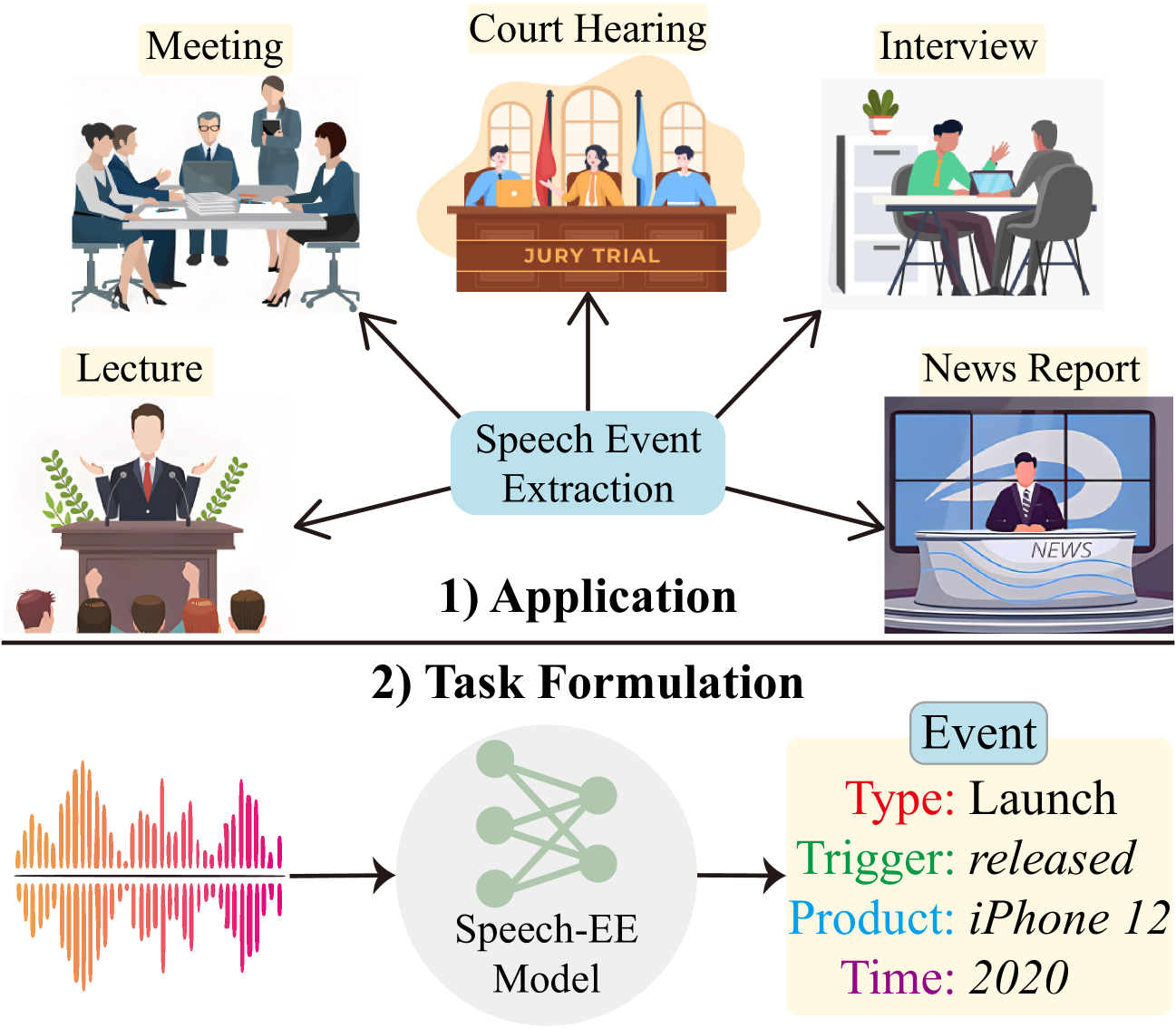
SpeechEE: A Novel Benchmark for Speech Event Extraction
Bin Wang, Meishan Zhang, Hao Fei, Yu Zhao, Bobo Li, Shengqiong Wu, Wei Ji, Min Zhang
Event extraction (EE) is a critical direction in the field of information extraction, laying an important foundation for the construction of structured knowledge bases. EE from text has received ample research and attention for years, yet there can be numerous real-world applications that require direct information acquisition from speech signals, online meeting minutes, interview summaries, press releases, etc. While EE from speech has remained under-explored, this paper fills the gap by pioneering a SpeechEE, defined as detecting the event predicates and arguments from a given audio speech. To benchmark the SpeechEE task, we first construct a large-scale high-quality dataset. Based on textual EE datasets under the sentence, document, and dialogue scenarios, we convert texts into speeches through both manual real-person narration and automatic synthesis, empowering the data with diverse scenarios, languages, domains, ambiences, and speaker styles. Further, to effectively address the key challenges in the task, we tailor an E2E SpeechEE system based on the encoder-decoder architecture, where a novel Shrinking Unit module and a retrieval-aided decoding mechanism are devised. Extensive experimental results on all SpeechEE subsets demonstrate the efficacy of the proposed model, offering a strong baseline for the task. At last, being the first work on this topic, we shed light on key directions for future research.
Read more8/26/2024