TextEE: Benchmark, Reevaluation, Reflections, and Future Challenges in Event Extraction

0
⛏️
Sign in to get full access
Overview
- Event extraction is a widely studied area in natural language processing with numerous applications.
- Recent studies have highlighted issues with how event extraction systems are evaluated, suggesting that reported performance scores may not accurately reflect real-world capabilities.
- The paper identifies and addresses several key evaluation challenges in event extraction.
- The researchers present TextEE, a standardized, fair, and reproducible benchmark for evaluating event extraction systems.
- The benchmark includes 16 datasets spanning 8 diverse domains and 14 recent event extraction methodologies.
- The authors also evaluate the performance of 5 large language models on the TextEE benchmark, highlighting their limitations in this task.
Plain English Explanation
Event extraction is the process of automatically identifying and extracting important events, such as accidents, natural disasters, or business transactions, from text data. This technology has many practical applications, such as monitoring real-time events for search, aggregating information about complex events, or extracting structured data from documents.
However, recent research has suggested that the way we evaluate the performance of event extraction systems may not be accurate. The scores reported in research papers may not reflect how well these systems would perform in the real world. This is because the evaluation process can be influenced by factors like the specific data used, the way the data is preprocessed, or the particular test conditions.
To address these evaluation challenges, the researchers created a new benchmark called TextEE. This benchmark provides standardized data preprocessing scripts and data splits for 16 different event extraction datasets, covering a wide range of domains. It also includes 14 recent event extraction methodologies, allowing for a comprehensive and fair comparison of different approaches.
The researchers also evaluated 5 large language models, which are powerful AI systems trained on massive amounts of text data, on the TextEE benchmark. They found that even these advanced models struggled to achieve satisfactory performance on the event extraction task, highlighting the continued challenges in this area of research.
Technical Explanation
The paper identifies three key challenges in event extraction evaluation:
-
Inconsistency: There is a lack of consistency in data preprocessing and evaluation, as different studies may make different assumptions or use different preprocessing steps, leading to incomparable results.
-
Insufficiency: Current evaluation frameworks may introduce dataset or data split bias, as they often rely on a limited set of datasets or use specific train-test splits that may not accurately reflect real-world performance.
-
Reproducibility: Some previous approaches have low reproducibility, making it difficult to verify and build upon their findings.
To address these challenges, the researchers present TextEE, a standardized, fair, and reproducible benchmark for event extraction. TextEE includes:
- Standardized data preprocessing scripts and splits for 16 datasets spanning 8 diverse domains.
- 14 recent event extraction methodologies, allowing for a comprehensive benchmark reevaluation.
- Evaluation of 5 large language models, including BERT, RoBERTa, and GPT-3, on the TextEE benchmark.
The benchmark reevaluation reveals that even the large language models struggle to achieve satisfactory performance on the event extraction task, suggesting that current techniques may not be sufficient for real-world applications.
Critical Analysis
The paper's identification of evaluation challenges in event extraction research is well-justified and supported by the literature. The authors have done a commendable job in creating a comprehensive and standardized benchmark to address these issues.
However, the paper does not discuss the potential limitations of the TextEE benchmark itself. For example, the selection of datasets and methodologies included in the benchmark may not be exhaustive, and there could be biases or blind spots in the chosen data and approaches.
Additionally, the paper does not explore the reasons why the large language models performed poorly on the event extraction task. It would be valuable to understand the specific limitations of these models in this domain and identify potential avenues for improving their performance, such as incorporating temporal information or developing more tailored architectures.
Overall, the TextEE benchmark represents a significant contribution to the field of event extraction research, but further analysis and ongoing refinement of the benchmark may be necessary to ensure its long-term utility and impact.
Conclusion
This paper presents a comprehensive effort to address the evaluation challenges in event extraction research. By introducing the TextEE benchmark, the researchers have provided a standardized, fair, and reproducible platform for evaluating event extraction systems.
The benchmark reevaluation results, which show the limitations of even large language models in this task, highlight the continued difficulties in developing robust and accurate event extraction capabilities. This underscores the importance of ongoing research and innovation in this area, as event extraction has wide-ranging applications in areas like real-time search, complex event aggregation, and structured data extraction.
The TextEE benchmark represents a significant step forward in facilitating and advancing event extraction research. By providing a standardized evaluation framework, the authors hope to drive the field towards more reliable and impactful developments in this important area of natural language processing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
⛏️
0
TextEE: Benchmark, Reevaluation, Reflections, and Future Challenges in Event Extraction
Kuan-Hao Huang, I-Hung Hsu, Tanmay Parekh, Zhiyu Xie, Zixuan Zhang, Premkumar Natarajan, Kai-Wei Chang, Nanyun Peng, Heng Ji
Event extraction has gained considerable interest due to its wide-ranging applications. However, recent studies draw attention to evaluation issues, suggesting that reported scores may not accurately reflect the true performance. In this work, we identify and address evaluation challenges, including inconsistency due to varying data assumptions or preprocessing steps, the insufficiency of current evaluation frameworks that may introduce dataset or data split bias, and the low reproducibility of some previous approaches. To address these challenges, we present TextEE, a standardized, fair, and reproducible benchmark for event extraction. TextEE comprises standardized data preprocessing scripts and splits for 16 datasets spanning eight diverse domains and includes 14 recent methodologies, conducting a comprehensive benchmark reevaluation. We also evaluate five varied large language models on our TextEE benchmark and demonstrate how they struggle to achieve satisfactory performance. Inspired by our reevaluation results and findings, we discuss the role of event extraction in the current NLP era, as well as future challenges and insights derived from TextEE. We believe TextEE, the first standardized comprehensive benchmarking tool, will significantly facilitate future event extraction research.
Read more6/7/2024
0
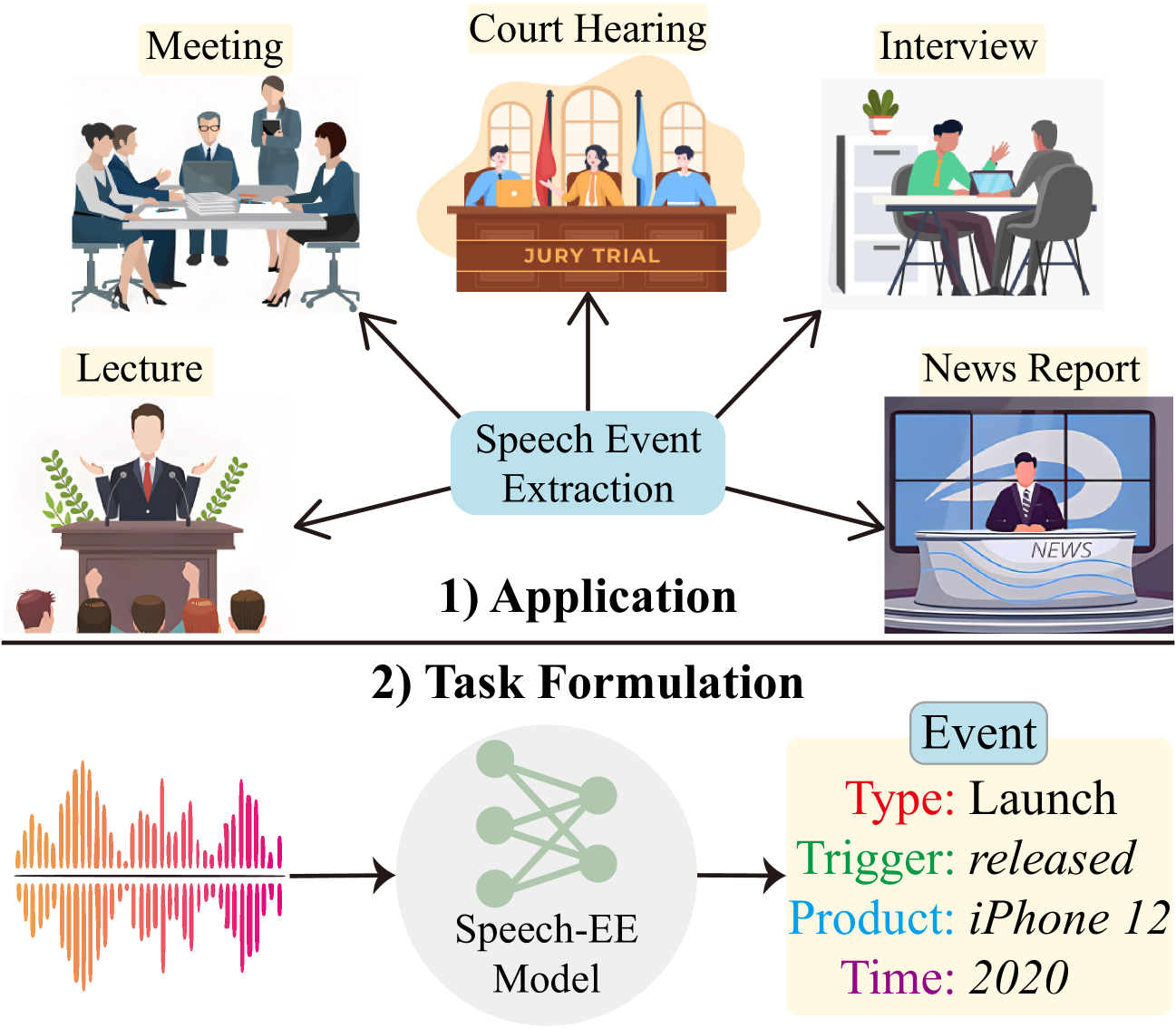
SpeechEE: A Novel Benchmark for Speech Event Extraction
Bin Wang, Meishan Zhang, Hao Fei, Yu Zhao, Bobo Li, Shengqiong Wu, Wei Ji, Min Zhang
Event extraction (EE) is a critical direction in the field of information extraction, laying an important foundation for the construction of structured knowledge bases. EE from text has received ample research and attention for years, yet there can be numerous real-world applications that require direct information acquisition from speech signals, online meeting minutes, interview summaries, press releases, etc. While EE from speech has remained under-explored, this paper fills the gap by pioneering a SpeechEE, defined as detecting the event predicates and arguments from a given audio speech. To benchmark the SpeechEE task, we first construct a large-scale high-quality dataset. Based on textual EE datasets under the sentence, document, and dialogue scenarios, we convert texts into speeches through both manual real-person narration and automatic synthesis, empowering the data with diverse scenarios, languages, domains, ambiences, and speaker styles. Further, to effectively address the key challenges in the task, we tailor an E2E SpeechEE system based on the encoder-decoder architecture, where a novel Shrinking Unit module and a retrieval-aided decoding mechanism are devised. Extensive experimental results on all SpeechEE subsets demonstrate the efficacy of the proposed model, offering a strong baseline for the task. At last, being the first work on this topic, we shed light on key directions for future research.
Read more8/26/2024

0
Towards Better Question Generation in QA-Based Event Extraction
Zijin Hong, Jian Liu
Event Extraction (EE) is an essential information extraction task that aims to extract event-related information from unstructured texts. The paradigm of this task has shifted from conventional classification-based methods to more contemporary question-answering-based (QA-based) approaches. However, in QA-based EE, the quality of the questions dramatically affects the extraction accuracy, and how to generate high-quality questions for QA-based EE remains a challenge. In this work, to tackle this challenge, we suggest four criteria to evaluate the quality of a question and propose a reinforcement learning method, RLQG, for QA-based EE that can generate generalizable, high-quality, and context-dependent questions and provides clear guidance to QA models. The extensive experiments conducted on ACE and RAMS datasets have strongly validated our approach's effectiveness, which also demonstrates its robustness in scenarios with limited training data. The corresponding code of RLQG is released for further research.
Read more7/23/2024
0
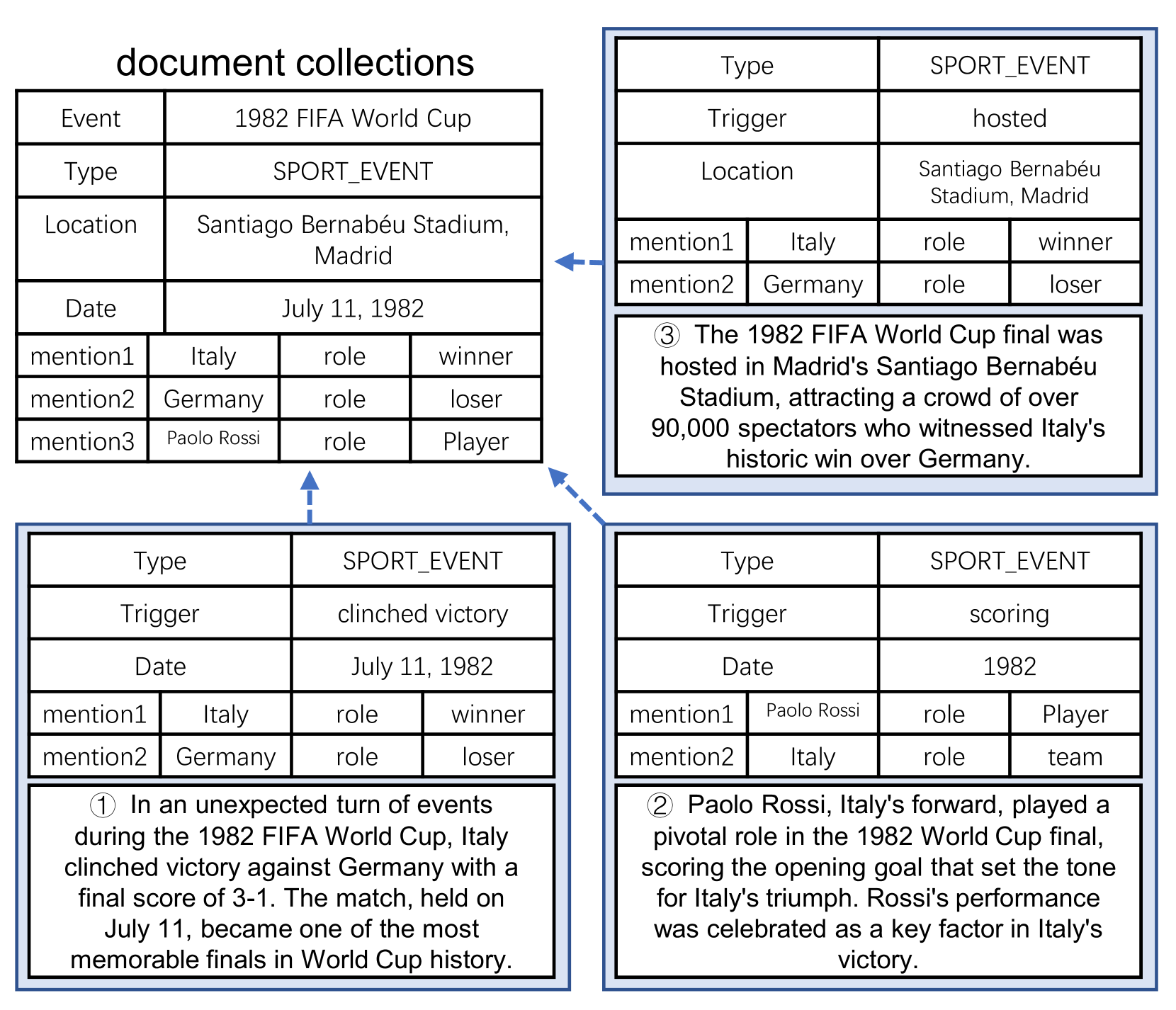
Harvesting Events from Multiple Sources: Towards a Cross-Document Event Extraction Paradigm
Qiang Gao, Zixiang Meng, Bobo Li, Jun Zhou, Fei Li, Chong Teng, Donghong Ji
Document-level event extraction aims to extract structured event information from unstructured text. However, a single document often contains limited event information and the roles of different event arguments may be biased due to the influence of the information source. This paper addresses the limitations of traditional document-level event extraction by proposing the task of cross-document event extraction (CDEE) to integrate event information from multiple documents and provide a comprehensive perspective on events. We construct a novel cross-document event extraction dataset, namely CLES, which contains 20,059 documents and 37,688 mention-level events, where over 70% of them are cross-document. To build a benchmark, we propose a CDEE pipeline that includes 5 steps, namely event extraction, coreference resolution, entity normalization, role normalization and entity-role resolution. Our CDEE pipeline achieves about 72% F1 in end-to-end cross-document event extraction, suggesting the challenge of this task. Our work builds a new line of information extraction research and will attract new research attention.
Read more6/26/2024