SpeechX: Neural Codec Language Model as a Versatile Speech Transformer
2308.06873
0
0
🧠
Abstract
Recent advancements in generative speech models based on audio-text prompts have enabled remarkable innovations like high-quality zero-shot text-to-speech. However, existing models still face limitations in handling diverse audio-text speech generation tasks involving transforming input speech and processing audio captured in adverse acoustic conditions. This paper introduces SpeechX, a versatile speech generation model capable of zero-shot TTS and various speech transformation tasks, dealing with both clean and noisy signals. SpeechX combines neural codec language modeling with multi-task learning using task-dependent prompting, enabling unified and extensible modeling and providing a consistent way for leveraging textual input in speech enhancement and transformation tasks. Experimental results show SpeechX's efficacy in various tasks, including zero-shot TTS, noise suppression, target speaker extraction, speech removal, and speech editing with or without background noise, achieving comparable or superior performance to specialized models across tasks. See https://aka.ms/speechx for demo samples.
Create account to get full access
Overview
- The paper introduces SpeechX, a versatile speech generation model capable of zero-shot text-to-speech (TTS) and various speech transformation tasks.
- SpeechX can handle both clean and noisy audio signals, addressing limitations of existing models in handling diverse audio-text speech generation tasks.
- The model combines neural codec language modeling with multi-task learning using task-dependent prompting, enabling unified and extensible modeling.
Plain English Explanation
The paper presents a new speech generation model called SpeechX that can perform a wide range of tasks, including zero-shot text-to-speech, noise suppression, target speaker extraction, and speech editing. Existing speech models often struggle with diverse audio-text generation tasks, especially when dealing with noisy or challenging audio conditions.
SpeechX addresses these limitations by using a novel approach that combines neural codec language modeling with multi-task learning. This allows the model to handle both clean and noisy audio signals and provide a consistent way to leverage textual input for speech enhancement and transformation tasks, such as speech editing and multilingual zero-shot text-to-speech.
The key idea is to use task-dependent prompting, which enables the model to learn a unified and extensible approach to a variety of speech generation and transformation tasks. This helps the model achieve comparable or even superior performance to specialized models across a range of tasks, as demonstrated in the experimental results.
Technical Explanation
The paper introduces SpeechX, a versatile speech generation model that combines neural codec language modeling with multi-task learning using task-dependent prompting. This allows the model to handle a diverse range of audio-text speech generation tasks, including zero-shot text-to-speech, noise suppression, target speaker extraction, and speech editing, while dealing with both clean and noisy audio signals.
The core of SpeechX is a unified modeling approach that uses task-dependent prompting to leverage textual input for various speech enhancement and transformation tasks. This enables the model to learn a consistent way of processing audio-text data, leading to improved performance compared to specialized models across a range of tasks.
The experimental results demonstrate SpeechX's efficacy in handling diverse speech generation and transformation tasks. The model achieves comparable or superior performance to specialized models in zero-shot text-to-speech, noise suppression, target speaker extraction, speech removal, and speech editing with or without background noise.
Critical Analysis
The paper presents a promising approach to building a versatile speech generation model that can handle a wide range of tasks. However, the authors acknowledge some limitations and areas for further research.
One potential concern is the model's ability to generalize to truly diverse and challenging audio conditions, as the experiments mostly focused on relatively controlled noise scenarios. Exploring the model's performance in more complex, real-world acoustic environments would be valuable.
Additionally, while the multi-task learning approach with task-dependent prompting enables a unified modeling strategy, the authors do not provide a detailed analysis of the model's internal workings and the specific contributions of the different components. Further research into the model's interpretability and the relative importance of its various design choices would help better understand its strengths and weaknesses.
Finally, the paper does not address potential ethical considerations, such as the model's use in sensitive applications like audio deepfakes or the potential for bias and fairness issues. As these models become more advanced, it will be crucial to consider their societal impact and develop appropriate safeguards.
Conclusion
The SpeechX model presented in this paper represents an important step forward in developing versatile speech generation capabilities. By combining neural codec language modeling with multi-task learning and task-dependent prompting, the model can handle a wide range of audio-text speech generation and transformation tasks, outperforming specialized models across various benchmarks.
This research has the potential to enable more natural and flexible speech interfaces, which could significantly impact fields like assistive technology, voice-based user interactions, and audio production. As the model and its underlying techniques continue to evolve, it will be important to address the remaining limitations and consider the broader societal implications of such powerful speech generation capabilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Improving Audio Codec-based Zero-Shot Text-to-Speech Synthesis with Multi-Modal Context and Large Language Model
Jinlong Xue, Yayue Deng, Yicheng Han, Yingming Gao, Ya Li
0
0
Recent advances in large language models (LLMs) and development of audio codecs greatly propel the zero-shot TTS. They can synthesize personalized speech with only a 3-second speech of an unseen speaker as acoustic prompt. However, they only support short speech prompts and cannot leverage longer context information, as required in audiobook and conversational TTS scenarios. In this paper, we introduce a novel audio codec-based TTS model to adapt context features with multiple enhancements. Inspired by the success of Qformer, we propose a multi-modal context-enhanced Qformer (MMCE-Qformer) to utilize additional multi-modal context information. Besides, we adapt a pretrained LLM to leverage its understanding ability to predict semantic tokens, and use a SoundStorm to generate acoustic tokens thereby enhancing audio quality and speaker similarity. The extensive objective and subjective evaluations show that our proposed method outperforms baselines across various context TTS scenarios.
6/7/2024

Improving Language Model-Based Zero-Shot Text-to-Speech Synthesis with Multi-Scale Acoustic Prompts
Shun Lei, Yixuan Zhou, Liyang Chen, Dan Luo, Zhiyong Wu, Xixin Wu, Shiyin Kang, Tao Jiang, Yahui Zhou, Yuxing Han, Helen Meng
0
0
Zero-shot text-to-speech (TTS) synthesis aims to clone any unseen speaker's voice without adaptation parameters. By quantizing speech waveform into discrete acoustic tokens and modeling these tokens with the language model, recent language model-based TTS models show zero-shot speaker adaptation capabilities with only a 3-second acoustic prompt of an unseen speaker. However, they are limited by the length of the acoustic prompt, which makes it difficult to clone personal speaking style. In this paper, we propose a novel zero-shot TTS model with the multi-scale acoustic prompts based on a neural codec language model VALL-E. A speaker-aware text encoder is proposed to learn the personal speaking style at the phoneme-level from the style prompt consisting of multiple sentences. Following that, a VALL-E based acoustic decoder is utilized to model the timbre from the timbre prompt at the frame-level and generate speech. The experimental results show that our proposed method outperforms baselines in terms of naturalness and speaker similarity, and can achieve better performance by scaling out to a longer style prompt.
4/10/2024
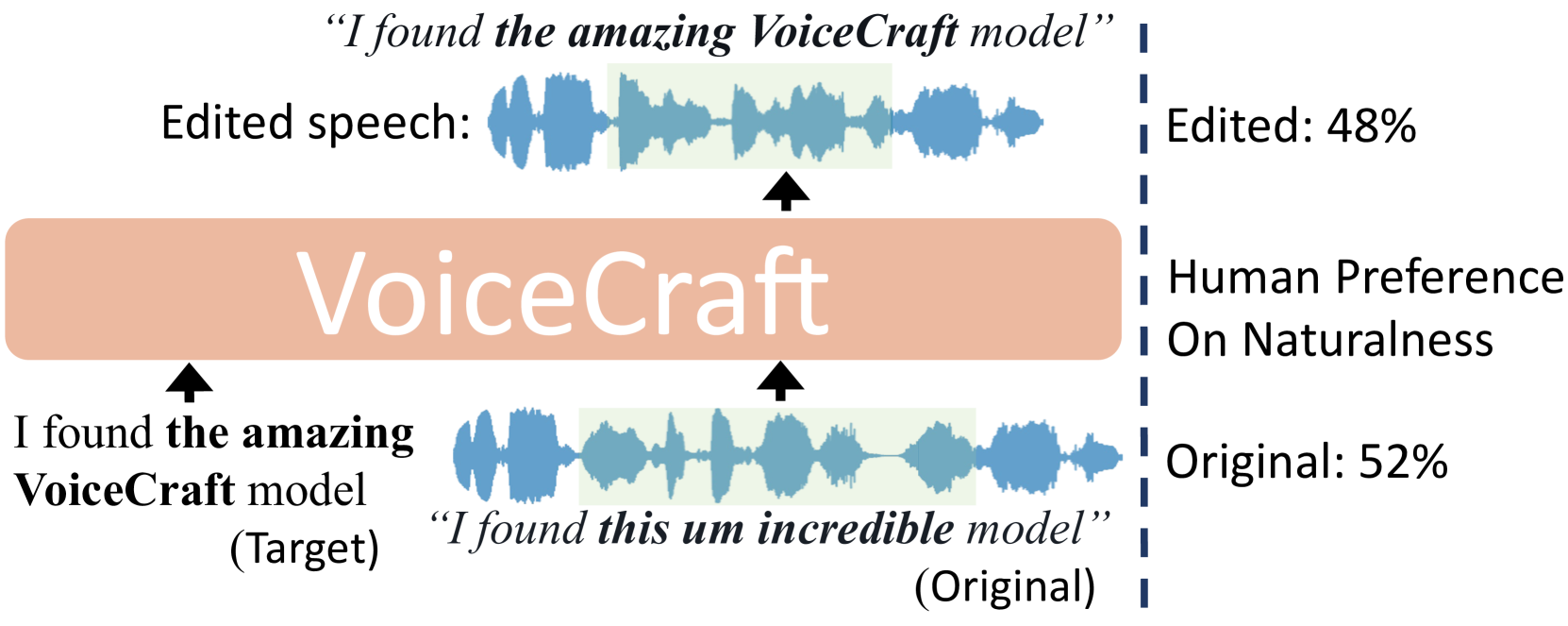
VoiceCraft: Zero-Shot Speech Editing and Text-to-Speech in the Wild
Puyuan Peng, Po-Yao Huang, Shang-Wen Li, Abdelrahman Mohamed, David Harwath
0
0
We introduce VoiceCraft, a token infilling neural codec language model, that achieves state-of-the-art performance on both speech editing and zero-shot text-to-speech (TTS) on audiobooks, internet videos, and podcasts. VoiceCraft employs a Transformer decoder architecture and introduces a token rearrangement procedure that combines causal masking and delayed stacking to enable generation within an existing sequence. On speech editing tasks, VoiceCraft produces edited speech that is nearly indistinguishable from unedited recordings in terms of naturalness, as evaluated by humans; for zero-shot TTS, our model outperforms prior SotA models including VALLE and the popular commercial model XTTS-v2. Crucially, the models are evaluated on challenging and realistic datasets, that consist of diverse accents, speaking styles, recording conditions, and background noise and music, and our model performs consistently well compared to other models and real recordings. In particular, for speech editing evaluation, we introduce a high quality, challenging, and realistic dataset named RealEdit. We encourage readers to listen to the demos at https://jasonppy.github.io/VoiceCraft_web.
6/17/2024

XTTS: a Massively Multilingual Zero-Shot Text-to-Speech Model
Edresson Casanova, Kelly Davis, Eren Golge, Gorkem Goknar, Iulian Gulea, Logan Hart, Aya Aljafari, Joshua Meyer, Reuben Morais, Samuel Olayemi, Julian Weber
0
0
Most Zero-shot Multi-speaker TTS (ZS-TTS) systems support only a single language. Although models like YourTTS, VALL-E X, Mega-TTS 2, and Voicebox explored Multilingual ZS-TTS they are limited to just a few high/medium resource languages, limiting the applications of these models in most of the low/medium resource languages. In this paper, we aim to alleviate this issue by proposing and making publicly available the XTTS system. Our method builds upon the Tortoise model and adds several novel modifications to enable multilingual training, improve voice cloning, and enable faster training and inference. XTTS was trained in 16 languages and achieved state-of-the-art (SOTA) results in most of them.
6/10/2024