VoiceCraft: Zero-Shot Speech Editing and Text-to-Speech in the Wild
2403.16973
0
0
Abstract
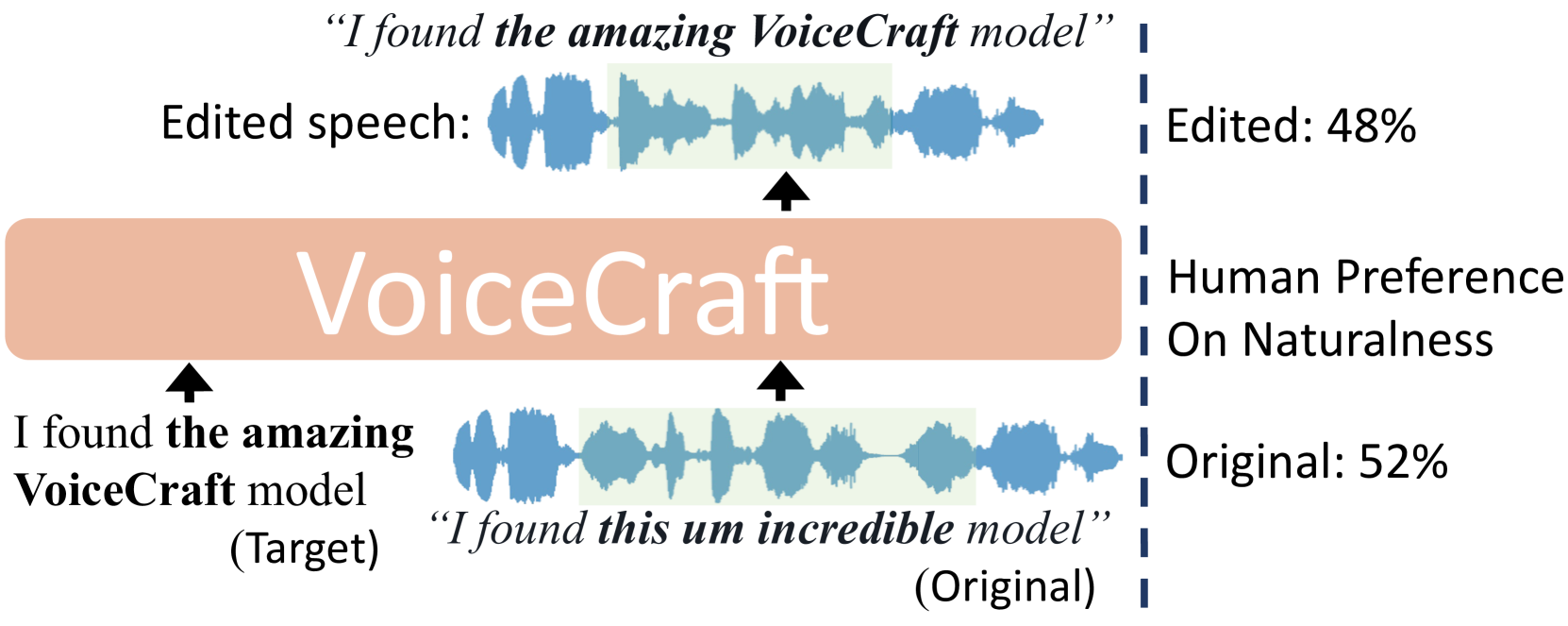
We introduce VoiceCraft, a token infilling neural codec language model, that achieves state-of-the-art performance on both speech editing and zero-shot text-to-speech (TTS) on audiobooks, internet videos, and podcasts. VoiceCraft employs a Transformer decoder architecture and introduces a token rearrangement procedure that combines causal masking and delayed stacking to enable generation within an existing sequence. On speech editing tasks, VoiceCraft produces edited speech that is nearly indistinguishable from unedited recordings in terms of naturalness, as evaluated by humans; for zero-shot TTS, our model outperforms prior SotA models including VALLE and the popular commercial model XTTS-v2. Crucially, the models are evaluated on challenging and realistic datasets, that consist of diverse accents, speaking styles, recording conditions, and background noise and music, and our model performs consistently well compared to other models and real recordings. In particular, for speech editing evaluation, we introduce a high quality, challenging, and realistic dataset named RealEdit. We encourage readers to listen to the demos at https://jasonppy.github.io/VoiceCraft_web.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper presents VoiceCraft, a novel system that enables zero-shot speech editing and text-to-speech capabilities in the real world.
- VoiceCraft leverages large language models and speech generation frameworks to allow users to edit audio and generate speech from text without the need for specialized training data or models.
- The system demonstrates impressive results, with the ability to modify voice characteristics, insert pauses, and generate coherent speech from arbitrary text prompts.
Plain English Explanation
VoiceCraft is a new technology that lets you edit audio and create speech from text, without needing lots of special training data or models. It uses large language models and speech generation tools to give you powerful capabilities, like changing how a voice sounds, adding pauses, and generating natural-sounding speech from any text you provide.
The key innovation of VoiceCraft is that it can do all this in a "zero-shot" way - meaning you don't need to train it on lots of examples first. You can just start using it to edit audio or create new speech, and it will work well right away. This makes it much more practical for real-world use cases compared to previous speech editing and generation systems.
The researchers behind VoiceCraft have demonstrated some impressive results, showing how you can dramatically transform the characteristics of a voice or generate coherent speech from any text prompt. This opens up all kinds of possibilities, from making audio more expressive to creating synthetic voices for creative applications.
Overall, VoiceCraft represents an exciting advance in the field of speech technology, providing users with powerful editing and generation capabilities without the need for specialized training. This could have big implications for industries like media, entertainment, and communications.
Technical Explanation
The core innovation of VoiceCraft is its ability to perform zero-shot speech editing and text-to-speech generation. This means the system can modify audio characteristics and synthesize speech from text without any prior training on specific speakers or styles.
At the heart of VoiceCraft is a large language model that has been pre-trained on a massive amount of text data. This allows the system to understand natural language and generate coherent speech that matches the input text. VoiceCraft also leverages state-of-the-art speech generation frameworks, such as CLAM-TTS, to convert the language model's outputs into high-quality audio.
For speech editing, VoiceCraft uses a novel approach that disentangles different aspects of the audio, like pitch, timbre, and prosody. This allows users to selectively modify these characteristics, similar to VoiceShop, without affecting the core content of the speech. The system can also insert pauses, change speaking rate, and perform other editing operations.
The text-to-speech capabilities of VoiceCraft are enabled by prompting the large language model with the desired text, and then using the MEGA-TTS 2 framework to generate the corresponding audio. This approach, building on prior work like Improving Language Model-Based Zero-Shot Text-to-Speech, allows VoiceCraft to produce natural-sounding synthetic speech from any input text.
Extensive experiments demonstrate the versatility and effectiveness of VoiceCraft, with the system achieving state-of-the-art performance on a range of speech editing and generation tasks, even in the zero-shot setting. This highlights the potential of large language models and modern speech technology to enable powerful, flexible, and accessible audio manipulation capabilities.
Critical Analysis
The VoiceCraft system represents a significant advancement in the field of speech editing and text-to-speech generation. Its ability to perform these tasks in a zero-shot manner, without requiring specialized training data or models, is a substantial improvement over previous approaches.
However, the paper does note some limitations of the current system. For example, while VoiceCraft can modify various aspects of speech, it may struggle with preserving the overall coherence and naturalness of the audio, especially for more complex editing operations. Additionally, the text-to-speech capabilities, while impressive, may not yet match the quality of specialized TTS models trained on large speech corpora.
Furthermore, as with any AI-powered speech technology, there are potential concerns around the ethical use of VoiceCraft, such as the creation of synthetic voices that could be used to impersonate real people or generate misleading audio content. The authors acknowledge these issues and suggest the need for further research into responsible development and deployment of such systems.
Overall, while VoiceCraft represents a significant step forward, there is still room for improvement and further investigation into the limitations and implications of this type of technology. Ongoing research and thoughtful consideration of the societal impacts will be crucial as these capabilities continue to evolve.
Conclusion
The VoiceCraft system presented in this paper demonstrates the potential of large language models and modern speech generation frameworks to enable powerful, flexible, and accessible audio manipulation capabilities. By leveraging these technologies, VoiceCraft can perform zero-shot speech editing and text-to-speech generation, allowing users to modify voice characteristics, insert pauses, and generate coherent synthetic speech from any text prompt.
The impressive results shown in the paper highlight the significant progress being made in the field of speech technology. VoiceCraft's ability to operate in a zero-shot manner makes it much more practical for real-world applications compared to previous approaches that required specialized training data and models.
However, the authors also acknowledge the need to address potential limitations and ethical concerns around the use of such technology. As these capabilities continue to advance, it will be crucial for researchers and developers to work closely with stakeholders to ensure responsible development and deployment, while also exploring the vast creative and practical possibilities that systems like VoiceCraft could enable.
Related Papers
CoVoMix: Advancing Zero-Shot Speech Generation for Human-like Multi-talker Conversations
Leying Zhang, Yao Qian, Long Zhou, Shujie Liu, Dongmei Wang, Xiaofei Wang, Midia Yousefi, Yanmin Qian, Jinyu Li, Lei He, Sheng Zhao, Michael Zeng
0
0
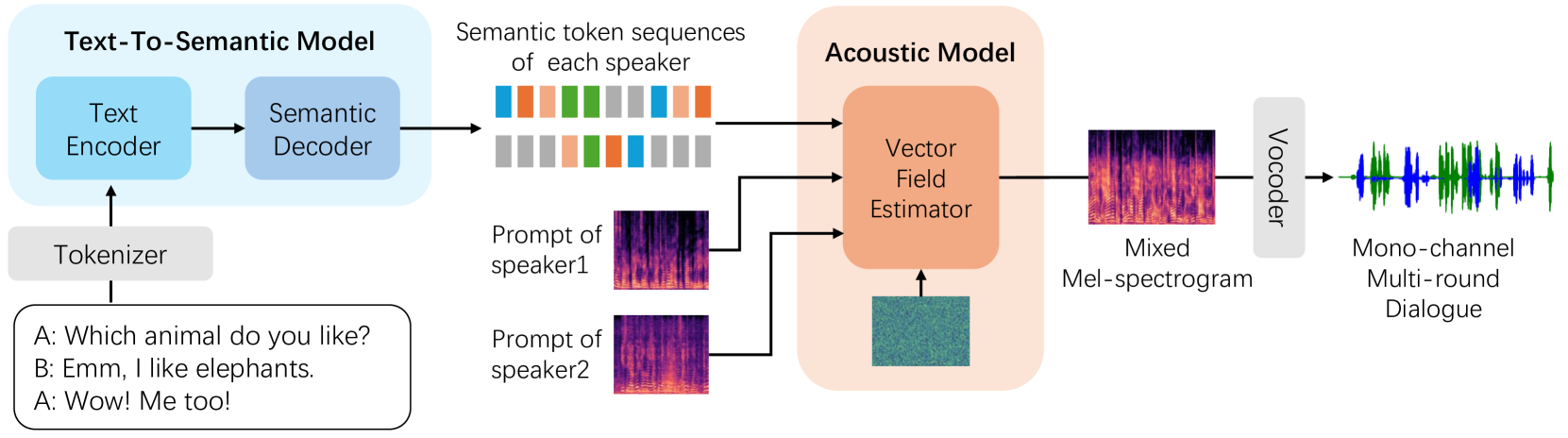
Recent advancements in zero-shot text-to-speech (TTS) modeling have led to significant strides in generating high-fidelity and diverse speech. However, dialogue generation, along with achieving human-like naturalness in speech, continues to be a challenge in the field. In this paper, we introduce CoVoMix: Conversational Voice Mixture Generation, a novel model for zero-shot, human-like, multi-speaker, multi-round dialogue speech generation. CoVoMix is capable of first converting dialogue text into multiple streams of discrete tokens, with each token stream representing semantic information for individual talkers. These token streams are then fed into a flow-matching based acoustic model to generate mixed mel-spectrograms. Finally, the speech waveforms are produced using a HiFi-GAN model. Furthermore, we devise a comprehensive set of metrics for measuring the effectiveness of dialogue modeling and generation. Our experimental results show that CoVoMix can generate dialogues that are not only human-like in their naturalness and coherence but also involve multiple talkers engaging in multiple rounds of conversation. These dialogues, generated within a single channel, are characterized by seamless speech transitions, including overlapping speech, and appropriate paralinguistic behaviors such as laughter. Audio samples are available at https://aka.ms/covomix.
4/11/2024
VoiceShop: A Unified Speech-to-Speech Framework for Identity-Preserving Zero-Shot Voice Editing
Philip Anastassiou, Zhenyu Tang, Kainan Peng, Dongya Jia, Jiaxin Li, Ming Tu, Yuping Wang, Yuxuan Wang, Mingbo Ma
0
0
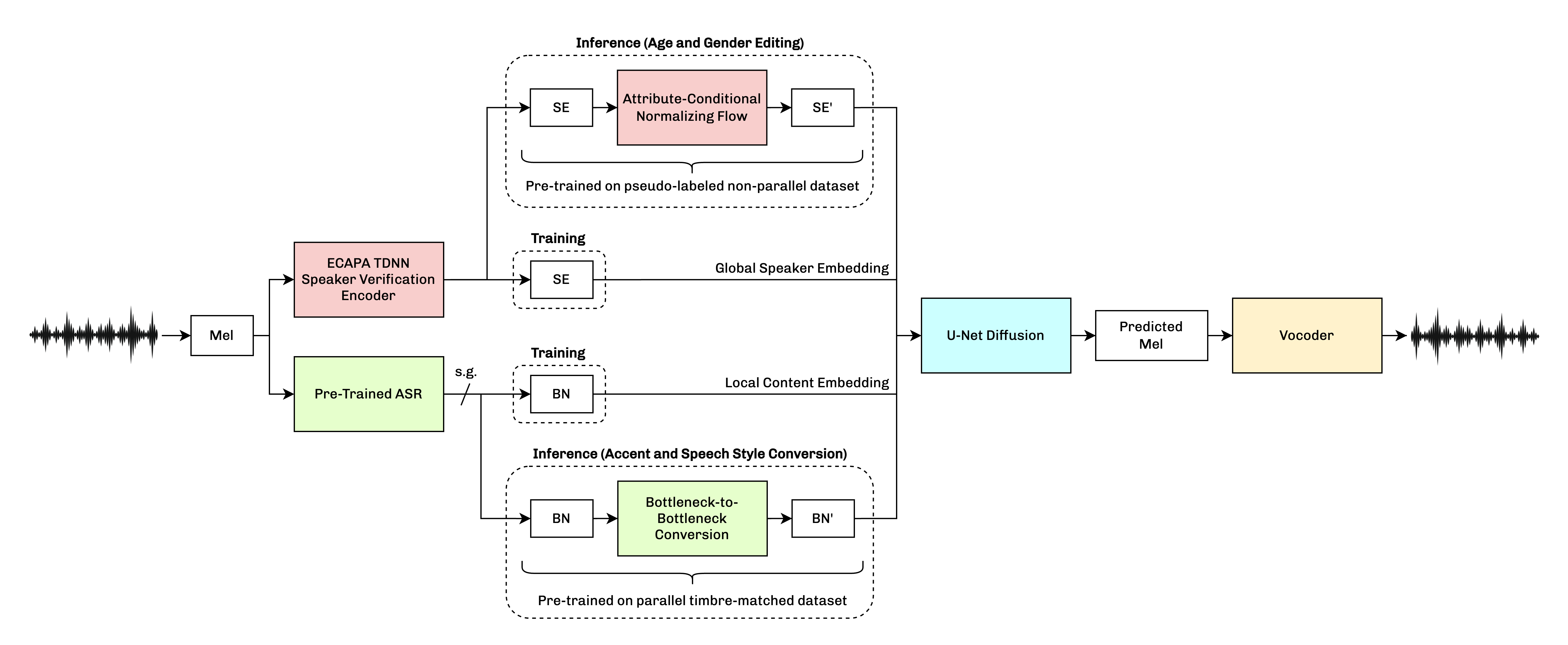
We present VoiceShop, a novel speech-to-speech framework that can modify multiple attributes of speech, such as age, gender, accent, and speech style, in a single forward pass while preserving the input speaker's timbre. Previous works have been constrained to specialized models that can only edit these attributes individually and suffer from the following pitfalls: the magnitude of the conversion effect is weak, there is no zero-shot capability for out-of-distribution speakers, or the synthesized outputs exhibit undesirable timbre leakage. Our work proposes solutions for each of these issues in a simple modular framework based on a conditional diffusion backbone model with optional normalizing flow-based and sequence-to-sequence speaker attribute-editing modules, whose components can be combined or removed during inference to meet a wide array of tasks without additional model finetuning. Audio samples are available at url{https://voiceshopai.github.io}.
4/12/2024

Improving Language Model-Based Zero-Shot Text-to-Speech Synthesis with Multi-Scale Acoustic Prompts
Shun Lei, Yixuan Zhou, Liyang Chen, Dan Luo, Zhiyong Wu, Xixin Wu, Shiyin Kang, Tao Jiang, Yahui Zhou, Yuxing Han, Helen Meng
0
0
Zero-shot text-to-speech (TTS) synthesis aims to clone any unseen speaker's voice without adaptation parameters. By quantizing speech waveform into discrete acoustic tokens and modeling these tokens with the language model, recent language model-based TTS models show zero-shot speaker adaptation capabilities with only a 3-second acoustic prompt of an unseen speaker. However, they are limited by the length of the acoustic prompt, which makes it difficult to clone personal speaking style. In this paper, we propose a novel zero-shot TTS model with the multi-scale acoustic prompts based on a neural codec language model VALL-E. A speaker-aware text encoder is proposed to learn the personal speaking style at the phoneme-level from the style prompt consisting of multiple sentences. Following that, a VALL-E based acoustic decoder is utilized to model the timbre from the timbre prompt at the frame-level and generate speech. The experimental results show that our proposed method outperforms baselines in terms of naturalness and speaker similarity, and can achieve better performance by scaling out to a longer style prompt.
4/10/2024
🗣️
FlashSpeech: Efficient Zero-Shot Speech Synthesis
Zhen Ye, Zeqian Ju, Haohe Liu, Xu Tan, Jianyi Chen, Yiwen Lu, Peiwen Sun, Jiahao Pan, Weizhen Bian, Shulin He, Qifeng Liu, Yike Guo, Wei Xue
0
0
Recent progress in large-scale zero-shot speech synthesis has been significantly advanced by language models and diffusion models. However, the generation process of both methods is slow and computationally intensive. Efficient speech synthesis using a lower computing budget to achieve quality on par with previous work remains a significant challenge. In this paper, we present FlashSpeech, a large-scale zero-shot speech synthesis system with approximately 5% of the inference time compared with previous work. FlashSpeech is built on the latent consistency model and applies a novel adversarial consistency training approach that can train from scratch without the need for a pre-trained diffusion model as the teacher. Furthermore, a new prosody generator module enhances the diversity of prosody, making the rhythm of the speech sound more natural. The generation processes of FlashSpeech can be achieved efficiently with one or two sampling steps while maintaining high audio quality and high similarity to the audio prompt for zero-shot speech generation. Our experimental results demonstrate the superior performance of FlashSpeech. Notably, FlashSpeech can be about 20 times faster than other zero-shot speech synthesis systems while maintaining comparable performance in terms of voice quality and similarity. Furthermore, FlashSpeech demonstrates its versatility by efficiently performing tasks like voice conversion, speech editing, and diverse speech sampling. Audio samples can be found in https://flashspeech.github.io/.
4/26/2024