CLaM-TTS: Improving Neural Codec Language Model for Zero-Shot Text-to-Speech
2404.02781
0
0
Abstract
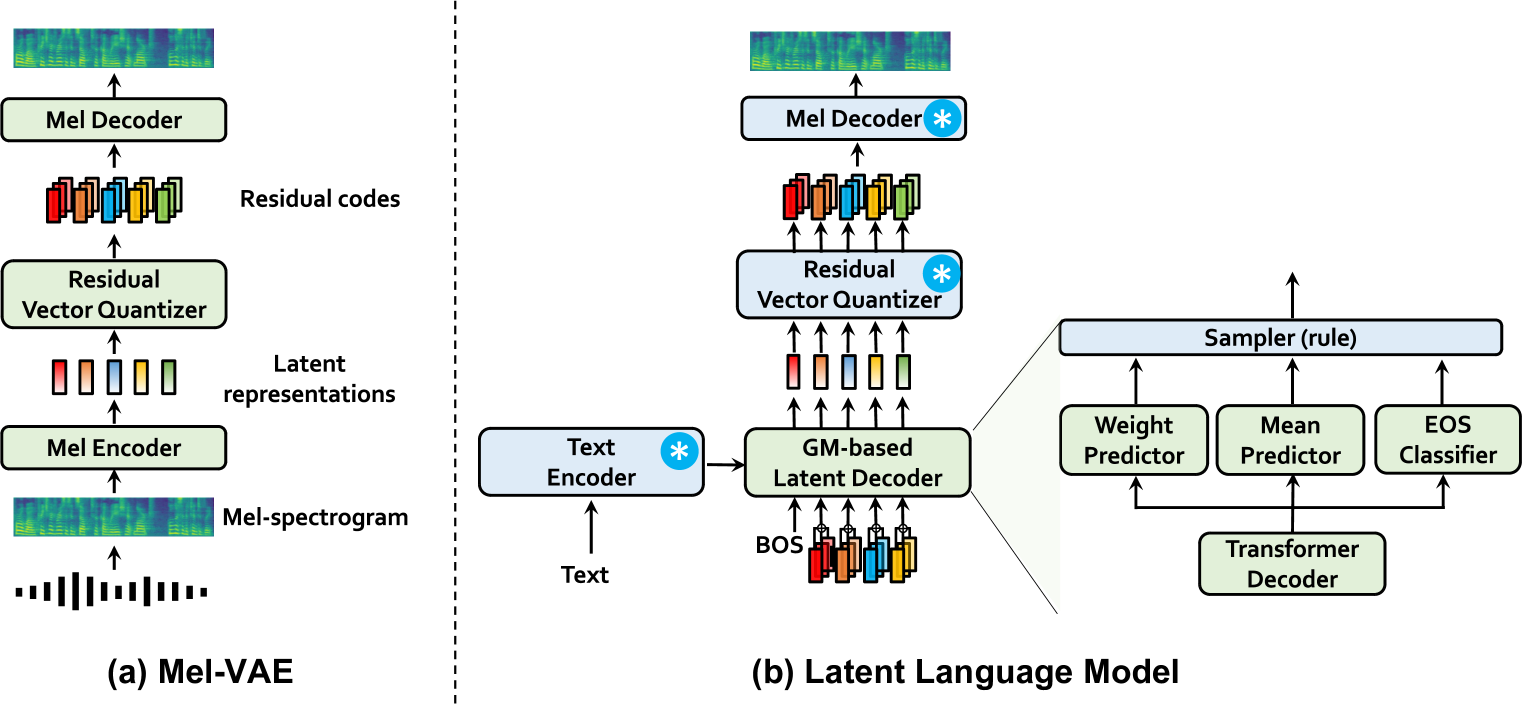
With the emergence of neural audio codecs, which encode multiple streams of discrete tokens from audio, large language models have recently gained attention as a promising approach for zero-shot Text-to-Speech (TTS) synthesis. Despite the ongoing rush towards scaling paradigms, audio tokenization ironically amplifies the scalability challenge, stemming from its long sequence length and the complexity of modelling the multiple sequences. To mitigate these issues, we present CLaM-TTS that employs a probabilistic residual vector quantization to (1) achieve superior compression in the token length, and (2) allow a language model to generate multiple tokens at once, thereby eliminating the need for cascaded modeling to handle the number of token streams. Our experimental results demonstrate that CLaM-TTS is better than or comparable to state-of-the-art neural codec-based TTS models regarding naturalness, intelligibility, speaker similarity, and inference speed. In addition, we examine the impact of the pretraining extent of the language models and their text tokenization strategies on performances.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper introduces CLaM-TTS, a novel approach to improving neural codec language modeling for zero-shot text-to-speech (TTS) tasks.
- The key idea is to leverage a pre-trained neural audio codec to bridge the gap between text and speech, enabling text-to-speech synthesis without requiring parallel text-speech data.
- The proposed method involves training a language model on the latent representations of the audio codec, allowing the model to better capture the connection between language and speech.
- Experiments demonstrate the effectiveness of CLaM-TTS in zero-shot TTS scenarios, outperforming previous state-of-the-art methods.
Plain English Explanation
The paper presents a new way to generate speech from text, even for languages or voices that the system hasn't been trained on before. The core idea is to use a pre-existing neural network that can convert audio into a compact, efficient representation. This "neural audio codec" acts as a bridge between text and speech.
The researchers train a language model to predict these compact audio representations, rather than trying to directly generate the audio waveform. This allows the system to learn the relationship between language and speech without requiring large datasets of paired text and speech samples.
The key advantage of this approach is that it enables "zero-shot" text-to-speech, where the system can generate speech for new languages or voices that it hasn't been explicitly trained on. This is particularly useful for low-resource languages or specialized applications where collecting large speech datasets may be difficult.
The paper demonstrates through experiments that this CLaM-TTS approach outperforms previous state-of-the-art methods for zero-shot text-to-speech. It's an exciting development that could make text-to-speech technology more accessible and flexible.
Technical Explanation
The paper introduces a novel approach called CLaM-TTS (Codec Language Modeling for Text-to-Speech) to improve neural codec language modeling for zero-shot text-to-speech tasks.
The key innovation is to leverage a pre-trained neural audio codec as an intermediate representation to bridge the gap between text and speech. Specifically, the researchers train a language model to predict the latent representations of the audio codec, rather than directly generating the audio waveform.
This approach has several advantages:
- It allows the language model to better capture the connection between language and speech, without requiring parallel text-speech data.
- It enables zero-shot text-to-speech, where the system can generate speech for new languages or voices that it hasn't been explicitly trained on.
- It leverages the efficiency and generalization capabilities of the pre-trained audio codec, which has been shown to outperform traditional speech codecs.
The paper evaluates the CLaM-TTS approach on several zero-shot TTS benchmarks, demonstrating its effectiveness compared to previous state-of-the-art methods. The results suggest that this approach could be a promising direction for improving the flexibility and accessibility of text-to-speech technology.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the CLaM-TTS approach, including comparisons to various baselines and state-of-the-art methods. The authors also acknowledge some potential limitations, such as the need for a high-quality pre-trained audio codec and the potential for performance degradation on out-of-distribution languages or voices.
One area that could be explored further is the interpretability and explainability of the learned representations. While the paper demonstrates the effectiveness of the approach, it would be interesting to understand more about how the language model is able to capture the relationship between text and speech through the audio codec's latent space.
Additionally, the paper focuses on zero-shot TTS, but it would be valuable to investigate the performance of CLaM-TTS in more traditional TTS scenarios where parallel text-speech data is available. This could help further validate the benefits of the proposed approach and potentially lead to insights about how to combine it with other TTS techniques.
Overall, the CLaM-TTS approach is a promising contribution to the field of text-to-speech, particularly for scenarios where data is scarce or diverse. The paper provides a solid technical foundation and encourages further research in this direction.
Conclusion
The CLaM-TTS paper presents a novel and effective approach to improving neural codec language modeling for zero-shot text-to-speech tasks. By leveraging a pre-trained audio codec as an intermediate representation, the method can bridge the gap between text and speech without requiring large parallel datasets.
The experiments demonstrate the effectiveness of CLaM-TTS in zero-shot scenarios, outperforming previous state-of-the-art methods. This is a significant advancement, as it could enable more flexible and accessible text-to-speech systems, particularly for low-resource languages or specialized applications.
The paper also highlights the potential for further research in this area, such as exploring the interpretability of the learned representations and investigating the performance of CLaM-TTS in more traditional TTS settings. Overall, this work represents an exciting step forward in the field of text-to-speech synthesis.
Related Papers

Improving Language Model-Based Zero-Shot Text-to-Speech Synthesis with Multi-Scale Acoustic Prompts
Shun Lei, Yixuan Zhou, Liyang Chen, Dan Luo, Zhiyong Wu, Xixin Wu, Shiyin Kang, Tao Jiang, Yahui Zhou, Yuxing Han, Helen Meng
0
0
Zero-shot text-to-speech (TTS) synthesis aims to clone any unseen speaker's voice without adaptation parameters. By quantizing speech waveform into discrete acoustic tokens and modeling these tokens with the language model, recent language model-based TTS models show zero-shot speaker adaptation capabilities with only a 3-second acoustic prompt of an unseen speaker. However, they are limited by the length of the acoustic prompt, which makes it difficult to clone personal speaking style. In this paper, we propose a novel zero-shot TTS model with the multi-scale acoustic prompts based on a neural codec language model VALL-E. A speaker-aware text encoder is proposed to learn the personal speaking style at the phoneme-level from the style prompt consisting of multiple sentences. Following that, a VALL-E based acoustic decoder is utilized to model the timbre from the timbre prompt at the frame-level and generate speech. The experimental results show that our proposed method outperforms baselines in terms of naturalness and speaker similarity, and can achieve better performance by scaling out to a longer style prompt.
4/10/2024
NaturalSpeech 3: Zero-Shot Speech Synthesis with Factorized Codec and Diffusion Models
Zeqian Ju, Yuancheng Wang, Kai Shen, Xu Tan, Detai Xin, Dongchao Yang, Yanqing Liu, Yichong Leng, Kaitao Song, Siliang Tang, Zhizheng Wu, Tao Qin, Xiang-Yang Li, Wei Ye, Shikun Zhang, Jiang Bian, Lei He, Jinyu Li, Sheng Zhao
0
0
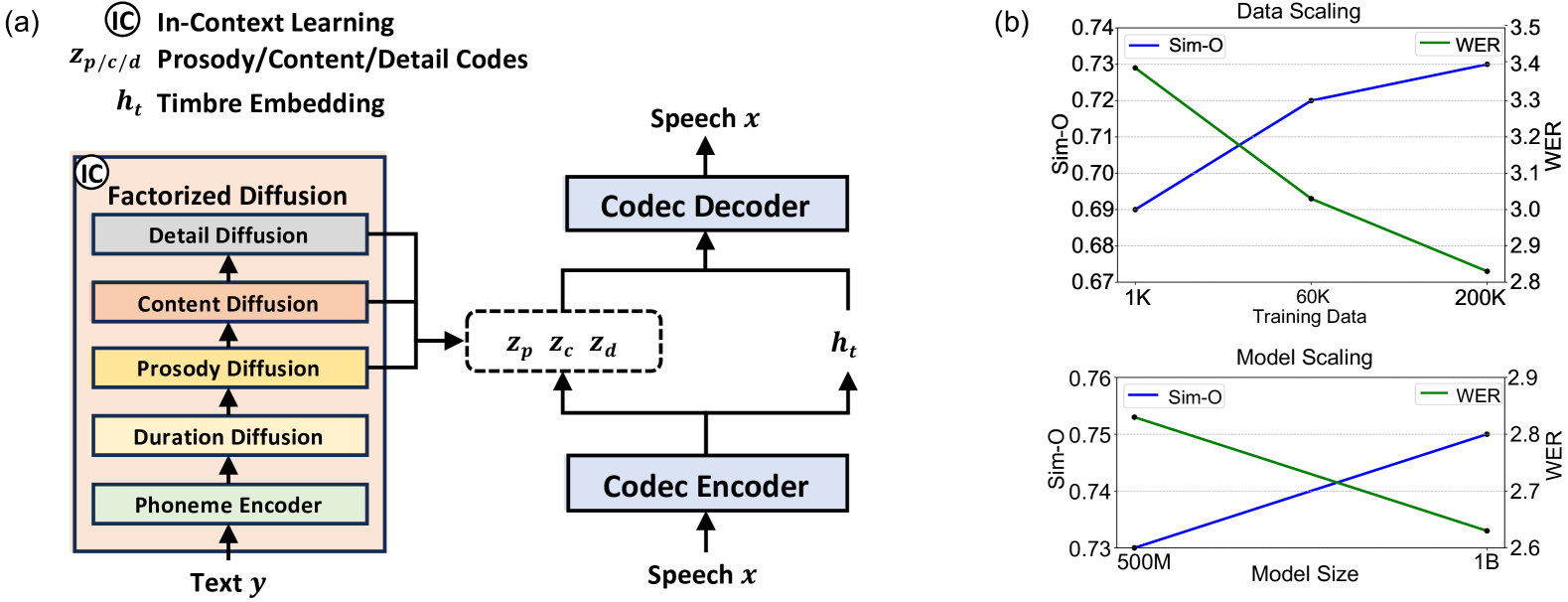
While recent large-scale text-to-speech (TTS) models have achieved significant progress, they still fall short in speech quality, similarity, and prosody. Considering speech intricately encompasses various attributes (e.g., content, prosody, timbre, and acoustic details) that pose significant challenges for generation, a natural idea is to factorize speech into individual subspaces representing different attributes and generate them individually. Motivated by it, we propose NaturalSpeech 3, a TTS system with novel factorized diffusion models to generate natural speech in a zero-shot way. Specifically, 1) we design a neural codec with factorized vector quantization (FVQ) to disentangle speech waveform into subspaces of content, prosody, timbre, and acoustic details; 2) we propose a factorized diffusion model to generate attributes in each subspace following its corresponding prompt. With this factorization design, NaturalSpeech 3 can effectively and efficiently model intricate speech with disentangled subspaces in a divide-and-conquer way. Experiments show that NaturalSpeech 3 outperforms the state-of-the-art TTS systems on quality, similarity, prosody, and intelligibility, and achieves on-par quality with human recordings. Furthermore, we achieve better performance by scaling to 1B parameters and 200K hours of training data.
4/24/2024
VoiceCraft: Zero-Shot Speech Editing and Text-to-Speech in the Wild
Puyuan Peng, Po-Yao Huang, Abdelrahman Mohamed, David Harwath
0
0
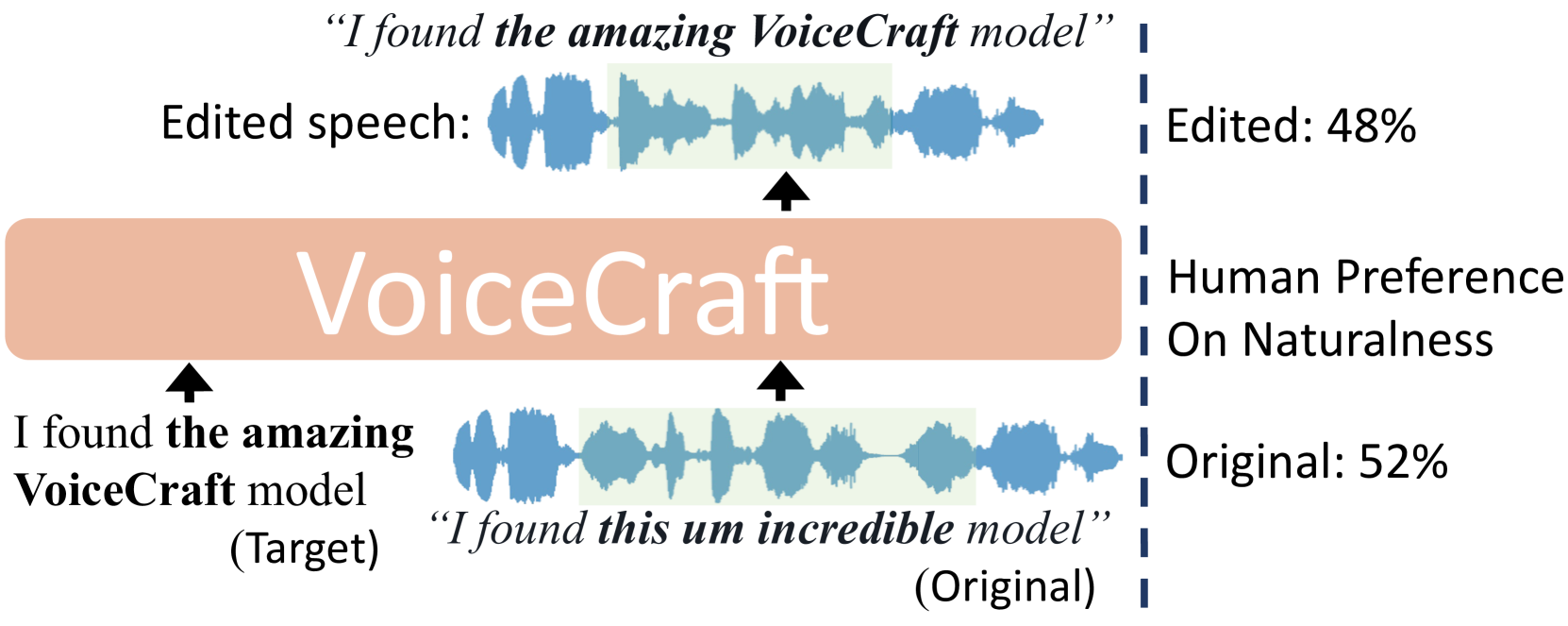
We introduce VoiceCraft, a token infilling neural codec language model, that achieves state-of-the-art performance on both speech editing and zero-shot text-to-speech (TTS) on audiobooks, internet videos, and podcasts. VoiceCraft employs a Transformer decoder architecture and introduces a token rearrangement procedure that combines causal masking and delayed stacking to enable generation within an existing sequence. On speech editing tasks, VoiceCraft produces edited speech that is nearly indistinguishable from unedited recordings in terms of naturalness, as evaluated by humans; for zero-shot TTS, our model outperforms prior SotA models including VALLE and the popular commercial model XTTS-v2. Crucially, the models are evaluated on challenging and realistic datasets, that consist of diverse accents, speaking styles, recording conditions, and background noise and music, and our model performs consistently well compared to other models and real recordings. In particular, for speech editing evaluation, we introduce a high quality, challenging, and realistic dataset named RealEdit. We encourage readers to listen to the demos at https://jasonppy.github.io/VoiceCraft_web.
4/23/2024
CoVoMix: Advancing Zero-Shot Speech Generation for Human-like Multi-talker Conversations
Leying Zhang, Yao Qian, Long Zhou, Shujie Liu, Dongmei Wang, Xiaofei Wang, Midia Yousefi, Yanmin Qian, Jinyu Li, Lei He, Sheng Zhao, Michael Zeng
0
0
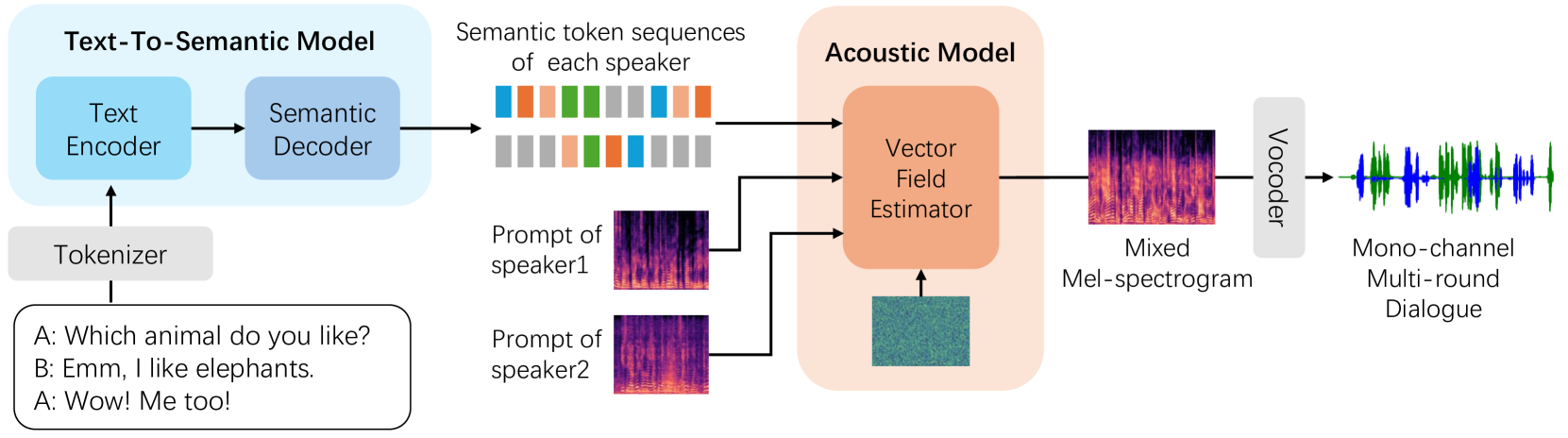
Recent advancements in zero-shot text-to-speech (TTS) modeling have led to significant strides in generating high-fidelity and diverse speech. However, dialogue generation, along with achieving human-like naturalness in speech, continues to be a challenge in the field. In this paper, we introduce CoVoMix: Conversational Voice Mixture Generation, a novel model for zero-shot, human-like, multi-speaker, multi-round dialogue speech generation. CoVoMix is capable of first converting dialogue text into multiple streams of discrete tokens, with each token stream representing semantic information for individual talkers. These token streams are then fed into a flow-matching based acoustic model to generate mixed mel-spectrograms. Finally, the speech waveforms are produced using a HiFi-GAN model. Furthermore, we devise a comprehensive set of metrics for measuring the effectiveness of dialogue modeling and generation. Our experimental results show that CoVoMix can generate dialogues that are not only human-like in their naturalness and coherence but also involve multiple talkers engaging in multiple rounds of conversation. These dialogues, generated within a single channel, are characterized by seamless speech transitions, including overlapping speech, and appropriate paralinguistic behaviors such as laughter. Audio samples are available at https://aka.ms/covomix.
4/11/2024