SPEED: Scalable Preprocessing of EEG Data for Self-Supervised Learning

0
Sign in to get full access
Overview
- Presents SPEED, a scalable preprocessing pipeline for EEG data to enable self-supervised learning
- Addresses the challenges of working with large-scale EEG datasets for machine learning applications
- Introduces a novel preprocessing workflow to enhance the quality and usability of EEG data
Plain English Explanation
The paper introduces a new system called SPEED (internal link) that helps make it easier to use brain wave (EEG) data for machine learning. Working with EEG data can be challenging because the signals are complex and large datasets are required for effective machine learning. SPEED provides a step-by-step process to preprocess the EEG data, which means preparing the data so it can be effectively used for training AI models. This preprocessing includes cleaning up noise, aligning the signals, and formatting the data in a way that machine learning algorithms can work with. By providing this scalable preprocessing pipeline, the authors aim to make it simpler for researchers and developers to leverage EEG data for self-supervised learning (internal link), which is a technique that can learn patterns in data without requiring labeled examples.
Technical Explanation
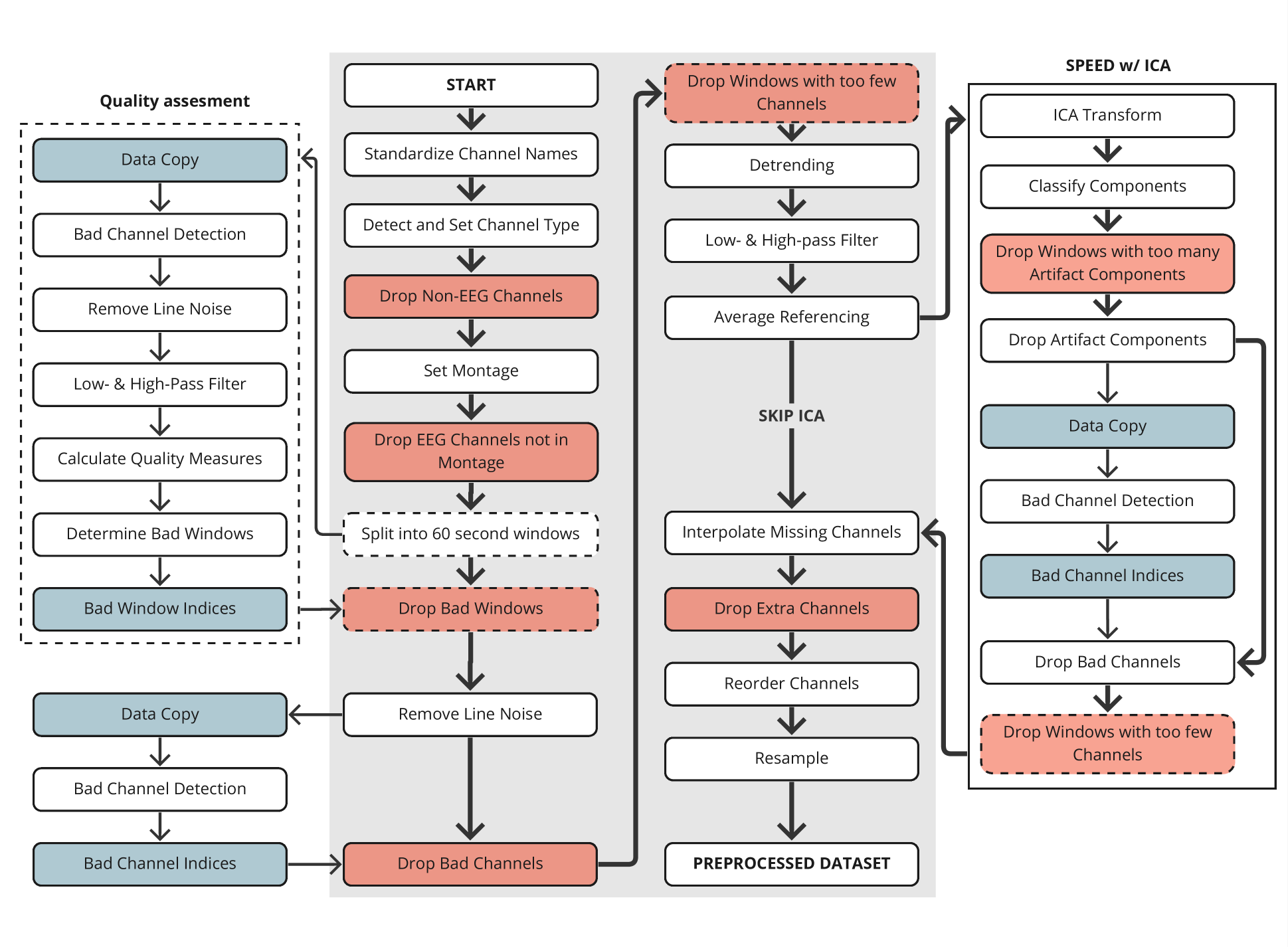
The paper presents SPEED (internal link), a scalable preprocessing pipeline for preparing EEG data for self-supervised learning. The authors identify several challenges in working with large-scale EEG datasets, including noise, variability, and the need for extensive preprocessing. SPEED addresses these issues through a novel workflow that includes steps like channel alignment, artifact removal, and normalization (internal link).
The key components of the SPEED pipeline are described in detail (internal link). These include advanced signal processing techniques like independent component analysis (ICA) and wavelet decomposition to isolate and remove artifacts. The preprocessed EEG data is then formatted for use in self-supervised learning models, which can learn rich representations of the brain activity without requiring labeled training data.
The authors evaluate SPEED on several large-scale EEG datasets and demonstrate its effectiveness in improving the quality and usability of the data for downstream machine learning tasks (internal link). The results show that SPEED can significantly enhance the performance of self-supervised learning models compared to traditional preprocessing approaches.
Critical Analysis
The paper provides a compelling solution to the challenges of working with large-scale EEG data for machine learning applications. The SPEED pipeline leverages state-of-the-art signal processing and normalization techniques to address issues like noise, variability, and the need for extensive manual preprocessing (internal link).
One potential limitation discussed in the paper is the computational complexity of some of the SPEED components, which could make it challenging to apply the pipeline to truly massive EEG datasets (internal link). The authors suggest that future work could explore ways to further optimize the pipeline for scalability.
Additionally, while the paper demonstrates the effectiveness of SPEED for self-supervised learning, it would be interesting to see how the preprocessed data performs on other machine learning tasks, such as clinical diagnosis or brain-computer interfaces (internal link, internal link). Exploring these additional applications could help further validate the broader utility of the SPEED approach.
Conclusion
The SPEED preprocessing pipeline introduced in this paper represents a significant advancement in making large-scale EEG data more accessible and usable for machine learning applications, particularly in the context of self-supervised learning (internal link, internal link). By addressing key challenges like noise, variability, and scalability, SPEED has the potential to accelerate progress in areas like brain-computer interfaces, clinical neuroimaging, and our fundamental understanding of the human brain.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SPEED: Scalable Preprocessing of EEG Data for Self-Supervised Learning
Anders Gj{o}lbye, Lina Skerath, William Lehn-Schi{o}ler, Nicolas Langer, Lars Kai Hansen
Electroencephalography (EEG) research typically focuses on tasks with narrowly defined objectives, but recent studies are expanding into the use of unlabeled data within larger models, aiming for a broader range of applications. This addresses a critical challenge in EEG research. For example, Kostas et al. (2021) show that self-supervised learning (SSL) outperforms traditional supervised methods. Given the high noise levels in EEG data, we argue that further improvements are possible with additional preprocessing. Current preprocessing methods often fail to efficiently manage the large data volumes required for SSL, due to their lack of optimization, reliance on subjective manual corrections, and validation processes or inflexible protocols that limit SSL. We propose a Python-based EEG preprocessing pipeline optimized for self-supervised learning, designed to efficiently process large-scale data. This optimization not only stabilizes self-supervised training but also enhances performance on downstream tasks compared to training with raw data.
Read more8/21/2024
0
Enhancing ADHD Diagnosis with EEG: The Critical Role of Preprocessing and Key Features
Sandra Garc'ia-Ponsoda, Alejandro Mat'e, Juan Trujillo
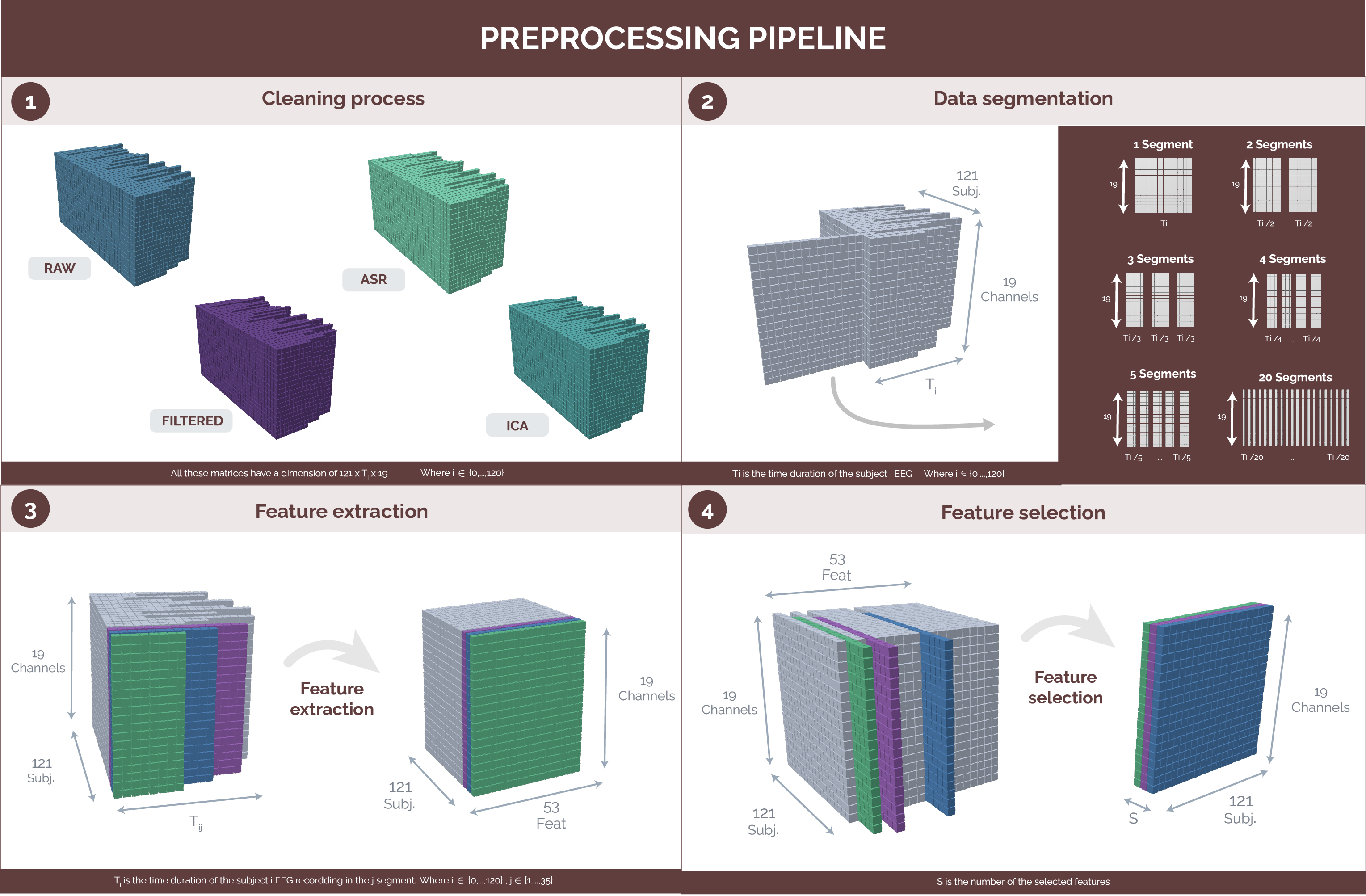
Background: Attention-Deficit/Hyperactivity Disorder (ADHD) is a prevalent neurodevelopmental disorder that significantly impacts various key aspects of life, requiring accurate diagnostic methods. Electroencephalogram (EEG) signals are used in diagnosing ADHD, but proper preprocessing is crucial to avoid noise and artifacts that could lead to unreliable results. Method: This study utilized a public EEG dataset from children diagnosed with ADHD and typically developing (TD) children. Four preprocessing techniques were applied: no preprocessing (Raw), Finite Impulse Response (FIR) filtering, Artifact Subspace Reconstruction (ASR), and Independent Component Analysis (ICA). EEG recordings were segmented, and features were extracted and selected based on statistical significance. Classification was performed using Machine Learning models, as XGBoost, Support Vector Machine, and K-Nearest Neighbors. Results: The absence of preprocessing leads to artificially high classification accuracy due to noise. In contrast, ASR and ICA preprocessing techniques significantly improved the reliability of results. Segmenting EEG recordings revealed that later segments provided better classification accuracy, likely due to the manifestation of ADHD symptoms over time. The most relevant EEG channels were P3, P4, and C3. The top features for classification included Kurtosis, Katz fractal dimension, and power spectral density of Delta, Theta, and Alpha bands. Conclusions: Effective preprocessing is essential in EEG-based ADHD diagnosis to prevent noise-induced biases. This study identifies crucial EEG channels and features, providing a foundation for further research and improving ADHD diagnostic accuracy. Future work should focus on expanding datasets, refining preprocessing methods, and enhancing feature interpretability to improve diagnostic accuracy and model robustness for clinical use.
Read more7/12/2024

0
Self-supervised visual learning in the low-data regime: a comparative evaluation
Sotirios Konstantakos, Despina Ioanna Chalkiadaki, Ioannis Mademlis, Yuki M. Asano, Efstratios Gavves, Georgios Th. Papadopoulos
Self-Supervised Learning (SSL) is a valuable and robust training methodology for contemporary Deep Neural Networks (DNNs), enabling unsupervised pretraining on a `pretext task' that does not require ground-truth labels/annotation. This allows efficient representation learning from massive amounts of unlabeled training data, which in turn leads to increased accuracy in a `downstream task' by exploiting supervised transfer learning. Despite the relatively straightforward conceptualization and applicability of SSL, it is not always feasible to collect and/or to utilize very large pretraining datasets, especially when it comes to real-world application settings. In particular, in cases of specialized and domain-specific application scenarios, it may not be achievable or practical to assemble a relevant image pretraining dataset in the order of millions of instances or it could be computationally infeasible to pretrain at this scale. This motivates an investigation on the effectiveness of common SSL pretext tasks, when the pretraining dataset is of relatively limited/constrained size. In this context, this work introduces a taxonomy of modern visual SSL methods, accompanied by detailed explanations and insights regarding the main categories of approaches, and, subsequently, conducts a thorough comparative experimental evaluation in the low-data regime, targeting to identify: a) what is learnt via low-data SSL pretraining, and b) how do different SSL categories behave in such training scenarios. Interestingly, for domain-specific downstream tasks, in-domain low-data SSL pretraining outperforms the common approach of large-scale pretraining on general datasets. Grounded on the obtained results, valuable insights are highlighted regarding the performance of each category of SSL methods, which in turn suggest straightforward future research directions in the field.
Read more4/29/2024

0
Scaling Law in Neural Data: Non-Invasive Speech Decoding with 175 Hours of EEG Data
Motoshige Sato, Kenichi Tomeoka, Ilya Horiguchi, Kai Arulkumaran, Ryota Kanai, Shuntaro Sasai
Brain-computer interfaces (BCIs) hold great potential for aiding individuals with speech impairments. Utilizing electroencephalography (EEG) to decode speech is particularly promising due to its non-invasive nature. However, recordings are typically short, and the high variability in EEG data has led researchers to focus on classification tasks with a few dozen classes. To assess its practical applicability for speech neuroprostheses, we investigate the relationship between the size of EEG data and decoding accuracy in the open vocabulary setting. We collected extensive EEG data from a single participant (175 hours) and conducted zero-shot speech segment classification using self-supervised representation learning. The model trained on the entire dataset achieved a top-1 accuracy of 48% and a top-10 accuracy of 76%, while mitigating the effects of myopotential artifacts. Conversely, when the data was limited to the typical amount used in practice ($sim$10 hours), the top-1 accuracy dropped to 2.5%, revealing a significant scaling effect. Additionally, as the amount of training data increased, the EEG latent representation progressively exhibited clearer temporal structures of spoken phrases. This indicates that the decoder can recognize speech segments in a data-driven manner without explicit measurements of word recognition. This research marks a significant step towards the practical realization of EEG-based speech BCIs.
Read more7/11/2024