SpiralMLP: A Lightweight Vision MLP Architecture

0
Sign in to get full access
Overview
- SpiralMLP is a lightweight vision MLP (Multilayer Perceptron) architecture.
- It aims to provide an efficient alternative to convolutional neural networks (CNNs) for vision tasks.
- The key idea is to use a spiral pattern of connections between layers to capture spatial relationships.
- This allows the model to learn representations that are more efficient and effective than traditional MLPs.
Plain English Explanation
The SpiralMLP paper introduces a new type of neural network architecture called SpiralMLP that is designed for computer vision tasks. Traditional neural networks for vision, called convolutional neural networks (CNNs), use a specific type of layer that is good at capturing the spatial relationships in images.
However, the authors of this paper wanted to see if they could create a simpler neural network architecture, called a multilayer perceptron (MLP), that could perform just as well on vision tasks. The key insight was to connect the neurons in each layer of the MLP in a spiral pattern, instead of the typical fully connected structure.
This spiral pattern allows the MLP to learn representations that can capture the spatial relationships in images, similar to how CNNs work. The result is a model that is more efficient and effective than a traditional MLP, while being simpler and lighter-weight than a CNN. This could be useful for deploying AI models on devices with limited computing power, like smartphones or edge devices.
Technical Explanation
The SpiralMLP paper proposes a new neural network architecture called SpiralMLP that is designed for computer vision tasks. Traditional convolutional neural networks (CNNs) use specialized convolutional layers to effectively capture the spatial relationships in images.
In contrast, the SpiralMLP architecture is based on a more basic neural network structure called a multilayer perceptron (MLP). However, the key innovation is the use of a spiral pattern of connections between the layers of the MLP. This spiral structure allows the model to learn representations that can encode the spatial information in images, similar to how CNNs work.
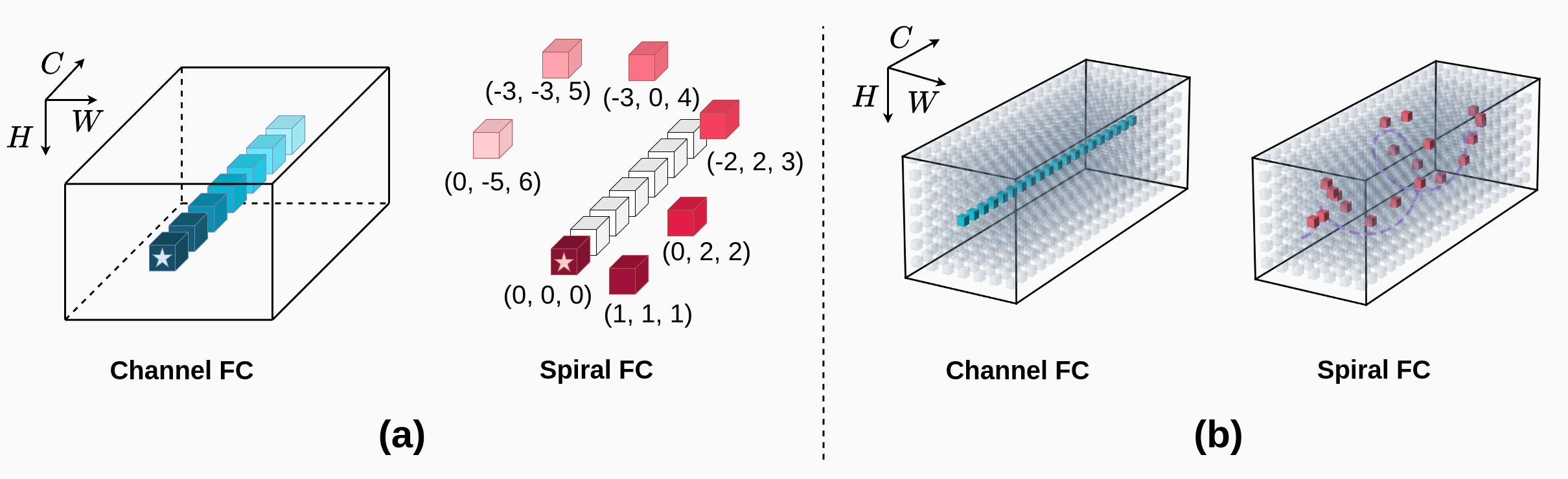
Specifically, the authors use a spiral attention mechanism to connect the neurons in each layer of the MLP. This attention mechanism learns a set of weights that determine how each neuron in a layer should be connected to the neurons in the next layer, forming a spiral pattern.
Through extensive experiments on image classification benchmarks, the authors show that SpiralMLP can achieve competitive accuracy compared to CNNs, while being more efficient and requiring less computational resources. This makes SpiralMLP a promising lightweight alternative to CNNs for vision tasks, especially on resource-constrained devices.
Critical Analysis
The SpiralMLP paper presents an interesting and novel approach to designing a more efficient neural network architecture for computer vision tasks. By introducing the spiral attention mechanism, the authors are able to imbue a standard MLP with the ability to learn spatial representations, overcoming a key limitation of traditional MLPs.
However, the paper does not address some potential limitations or areas for further research. For example, it is unclear how SpiralMLP would scale to higher-resolution or more complex image datasets, as the spiral attention mechanism may become unwieldy. Additionally, the paper does not explore the interpretability or explainability of the learned representations in SpiralMLP, which could be an important consideration for real-world applications.
Further research could also investigate whether the spiral attention mechanism could be applied to other neural network architectures, such as transformers, to create even more efficient and effective models for vision tasks. Overall, the SpiralMLP paper represents an important step forward in the ongoing efforts to develop lightweight and performant AI models for deployment on a wide range of devices and applications.
Conclusion
The SpiralMLP paper introduces a new neural network architecture called SpiralMLP that aims to provide an efficient alternative to convolutional neural networks (CNNs) for computer vision tasks. By using a spiral pattern of connections between the layers of a multilayer perceptron (MLP), SpiralMLP is able to capture spatial relationships in images, overcoming a key limitation of traditional MLPs.
Through experiments on image classification benchmarks, the authors demonstrate that SpiralMLP can achieve competitive accuracy compared to CNNs, while being more efficient and requiring less computational resources. This makes SpiralMLP a promising lightweight model for deployment on resource-constrained devices, such as smartphones or edge devices.
While the paper presents an interesting and novel approach, there are still some areas for further research and potential limitations that could be explored. Overall, the SpiralMLP architecture represents an important contribution to the ongoing efforts to develop more efficient and effective AI models for a wide range of real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SpiralMLP: A Lightweight Vision MLP Architecture
Haojie Mu, Burhan Ul Tayyab, Nicholas Chua
We present SpiralMLP, a novel architecture that introduces a Spiral FC layer as a replacement for the conventional Token Mixing approach. Differing from several existing MLP-based models that primarily emphasize axes, our Spiral FC layer is designed as a deformable convolution layer with spiral-like offsets. We further adapt Spiral FC into two variants: Self-Spiral FC and Cross-Spiral FC, which enable both local and global feature integration seamlessly, eliminating the need for additional processing steps. To thoroughly investigate the effectiveness of the spiral-like offsets and validate our design, we conduct ablation studies and explore optimal configurations. In empirical tests, SpiralMLP reaches state-of-the-art performance, similar to Transformers, CNNs, and other MLPs, benchmarking on ImageNet-1k, COCO and ADE20K. SpiralMLP still maintains linear computational complexity O(HW) and is compatible with varying input image resolutions. Our study reveals that targeting the full receptive field is not essential for achieving high performance, instead, adopting a refined approach offers better results.
Read more9/5/2024
🖼️
0
Caterpillar: A Pure-MLP Architecture with Shifted-Pillars-Concatenation
Jin Sun, Xiaoshuang Shi, Zhiyuan Wang, Kaidi Xu, Heng Tao Shen, Xiaofeng Zhu
Modeling in Computer Vision has evolved to MLPs. Vision MLPs naturally lack local modeling capability, to which the simplest treatment is combined with convolutional layers. Convolution, famous for its sliding window scheme, also suffers from this scheme of redundancy and lower parallel computation. In this paper, we seek to dispense with the windowing scheme and introduce a more elaborate and parallelizable method to exploit locality. To this end, we propose a new MLP module, namely Shifted-Pillars-Concatenation (SPC), that consists of two steps of processes: (1) Pillars-Shift, which generates four neighboring maps by shifting the input image along four directions, and (2) Pillars-Concatenation, which applies linear transformations and concatenation on the maps to aggregate local features. SPC module offers superior local modeling power and performance gains, making it a promising alternative to the convolutional layer. Then, we build a pure-MLP architecture called Caterpillar by replacing the convolutional layer with the SPC module in a hybrid model of sMLPNet. Extensive experiments show Caterpillar's excellent performance on both small-scale and ImageNet-1k classification benchmarks, with remarkable scalability and transfer capability possessed as well. The code is available at https://github.com/sunjin19126/Caterpillar.
Read more9/11/2024

0
Lateralization MLP: A Simple Brain-inspired Architecture for Diffusion
Zizhao Hu, Mohammad Rostami
The Transformer architecture has dominated machine learning in a wide range of tasks. The specific characteristic of this architecture is an expensive scaled dot-product attention mechanism that models the inter-token interactions, which is known to be the reason behind its success. However, such a mechanism does not have a direct parallel to the human brain which brings the question if the scaled-dot product is necessary for intelligence with strong expressive power. Inspired by the lateralization of the human brain, we propose a new simple but effective architecture called the Lateralization MLP (L-MLP). Stacking L-MLP blocks can generate complex architectures. Each L-MLP block is based on a multi-layer perceptron (MLP) that permutes data dimensions, processes each dimension in parallel, merges them, and finally passes through a joint MLP. We discover that this specific design outperforms other MLP variants and performs comparably to a transformer-based architecture in the challenging diffusion task while being highly efficient. We conduct experiments using text-to-image generation tasks to demonstrate the effectiveness and efficiency of L-MLP. Further, we look into the model behavior and discover a connection to the function of the human brain. Our code is publicly available: url{https://github.com/zizhao-hu/L-MLP}
Read more5/28/2024
0
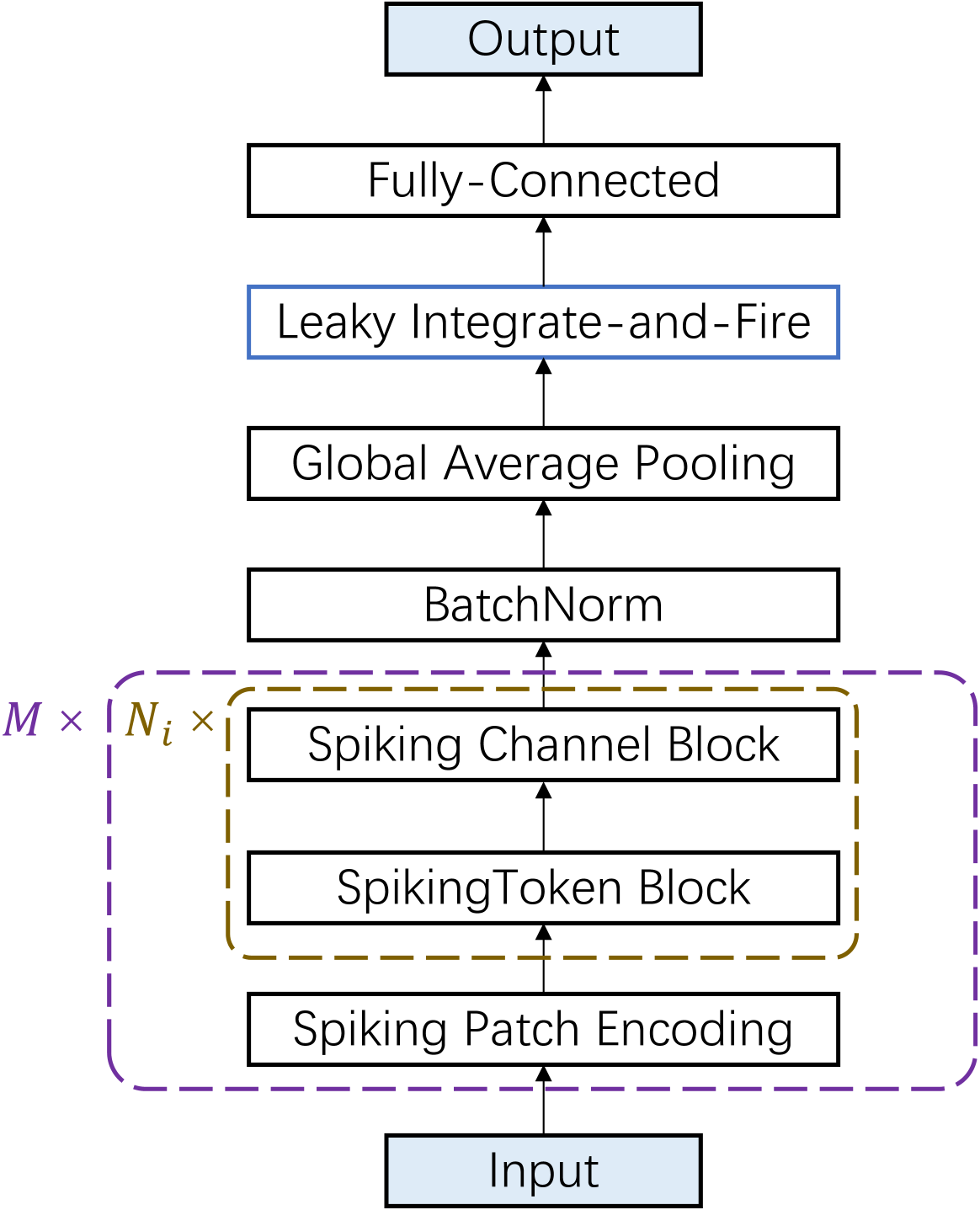
Efficient Deep Spiking Multi-Layer Perceptrons with Multiplication-Free Inference
Boyan Li, Luziwei Leng, Shuaijie Shen, Kaixuan Zhang, Jianguo Zhang, Jianxing Liao, Ran Cheng
Advancements in adapting deep convolution architectures for Spiking Neural Networks (SNNs) have significantly enhanced image classification performance and reduced computational burdens. However, the inability of Multiplication-Free Inference (MFI) to align with attention and transformer mechanisms, which are critical to superior performance on high-resolution vision tasks, imposing limitations on these gains. To address this, our research explores a new pathway, drawing inspiration from the progress made in Multi-Layer Perceptrons (MLPs). We propose an innovative spiking MLP architecture that uses batch normalization to retain MFI compatibility and introducing a spiking patch encoding layer to enhance local feature extraction capabilities. As a result, we establish an efficient multi-stage spiking MLP network that blends effectively global receptive fields with local feature extraction for comprehensive spike-based computation. Without relying on pre-training or sophisticated SNN training techniques, our network secures a top-1 accuracy of 66.39% on the ImageNet-1K dataset, surpassing the directly trained spiking ResNet-34 by 2.67%. Furthermore, we curtail computational costs, model parameters, and simulation steps. An expanded version of our network compares with the performance of the spiking VGG-16 network with a 71.64% top-1 accuracy, all while operating with a model capacity 2.1 times smaller. Our findings highlight the potential of our deep SNN architecture in effectively integrating global and local learning abilities. Interestingly, the trained receptive field in our network mirrors the activity patterns of cortical cells. Source codes are publicly accessible at https://github.com/EMI-Group/mixer-snn.
Read more4/29/2024