Lateralization MLP: A Simple Brain-inspired Architecture for Diffusion

0

Sign in to get full access
Overview
- This paper proposes a simple brain-inspired architecture called Lateralization MLP for diffusion models.
- The architecture is inspired by the lateral specialization observed in the human brain, where the left and right hemispheres process information differently.
- The authors show that this architecture can achieve competitive performance compared to more complex models, while being more efficient and easier to train.
Plain English Explanation
The human brain is an incredible organ, with the left and right hemispheres often specializing in different tasks. For example, the left side is typically better at language processing, while the right side is better at spatial awareness. Brainformers and other research have explored ways to mimic this lateral specialization in artificial neural networks.
The authors of this paper take a similar approach with their Lateralization MLP architecture. Instead of using a complex model like a transformer, they designed a simpler Multi-Layer Perceptron (MLP) network that separates the left and right sides of the input data. This allows the model to process information in a more specialized way, just like the human brain.
The key insight is that this simple architecture can achieve results on par with more sophisticated models, while being more efficient and easier to train. The authors demonstrate this on diffusion tasks, which are a type of machine learning problem that generates new data samples by gradually removing noise from an initial noisy input.
Overall, the Lateralization MLP is an intriguing example of how bio-inspired architectures can lead to powerful and efficient models, even for complex tasks like diffusion.
Technical Explanation
The authors propose a simple brain-inspired architecture called Lateralization MLP for diffusion models. The key idea is to separate the left and right sides of the input data, similar to the lateral specialization observed in the human brain.
Specifically, the Lateralization MLP consists of two parallel MLPs, one processing the left side of the input and the other processing the right side. The outputs of these two MLPs are then concatenated and passed through a final MLP layer to produce the final output.
This architecture allows the model to specialize in processing different parts of the input, mimicking the lateral specialization seen in the brain. The authors show that this simple approach can achieve competitive performance on diffusion tasks compared to more complex models, while being more efficient and easier to train.
In their experiments, the authors evaluate the Lateralization MLP on several diffusion benchmarks, including image and text generation tasks. They compare the performance to alternative architectures and find that the Lateralization MLP achieves comparable or better results, while being more parameter-efficient and faster to train.
Critical Analysis
The Lateralization MLP architecture is a compelling approach that demonstrates how bio-inspired principles can lead to simple yet effective models. The authors make a strong case for the benefits of this architecture, including its efficiency and ease of training.
However, the paper does not delve into the limitations or potential drawbacks of the Lateralization MLP. For example, it would be interesting to understand how the architecture performs on more complex tasks or datasets, and whether the lateral specialization approach is universally beneficial or has specific use cases.
Additionally, the authors could have explored the interpretability of the Lateralization MLP and how the specialized processing in the left and right MLPs contributes to the model's performance. This could provide valuable insights into the inner workings of the architecture and its relationship to the brain.
Overall, the Lateralization MLP is a promising direction in the pursuit of efficient and bio-inspired machine learning models. Further research and exploration of its capabilities, limitations, and potential applications would be valuable for the field.
Conclusion
The Lateralization MLP proposed in this paper is a simple yet effective brain-inspired architecture for diffusion models. By separating the left and right sides of the input data and processing them in parallel, the model can achieve competitive performance while being more efficient and easier to train than more complex alternatives.
This research demonstrates the potential of bio-inspired approaches in machine learning, and the Lateralization MLP serves as an example of how principles observed in the human brain can be translated into effective artificial neural network architectures. As the field of machine learning continues to evolve, this type of innovative and efficient architecture may play an important role in advancing the state of the art.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Lateralization MLP: A Simple Brain-inspired Architecture for Diffusion
Zizhao Hu, Mohammad Rostami
The Transformer architecture has dominated machine learning in a wide range of tasks. The specific characteristic of this architecture is an expensive scaled dot-product attention mechanism that models the inter-token interactions, which is known to be the reason behind its success. However, such a mechanism does not have a direct parallel to the human brain which brings the question if the scaled-dot product is necessary for intelligence with strong expressive power. Inspired by the lateralization of the human brain, we propose a new simple but effective architecture called the Lateralization MLP (L-MLP). Stacking L-MLP blocks can generate complex architectures. Each L-MLP block is based on a multi-layer perceptron (MLP) that permutes data dimensions, processes each dimension in parallel, merges them, and finally passes through a joint MLP. We discover that this specific design outperforms other MLP variants and performs comparably to a transformer-based architecture in the challenging diffusion task while being highly efficient. We conduct experiments using text-to-image generation tasks to demonstrate the effectiveness and efficiency of L-MLP. Further, we look into the model behavior and discover a connection to the function of the human brain. Our code is publicly available: url{https://github.com/zizhao-hu/L-MLP}
Read more5/28/2024
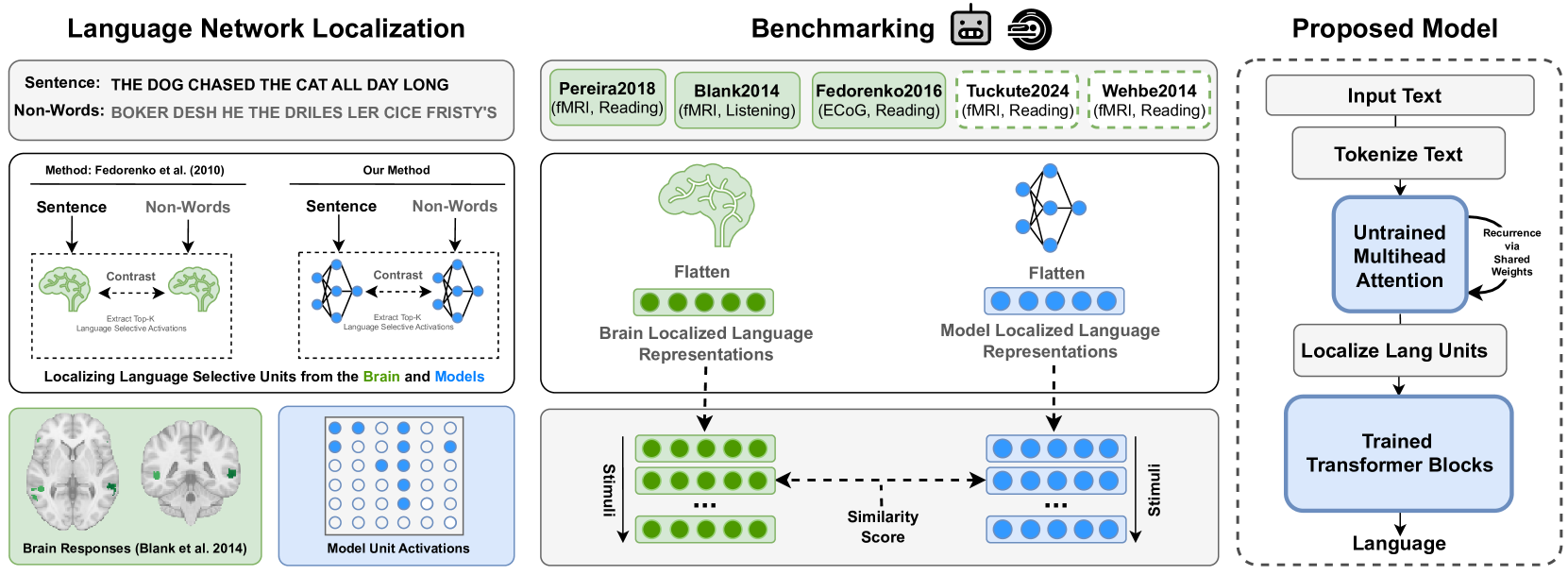
0
Brain-Like Language Processing via a Shallow Untrained Multihead Attention Network
Badr AlKhamissi, Greta Tuckute, Antoine Bosselut, Martin Schrimpf
Large Language Models (LLMs) have been shown to be effective models of the human language system, with some models predicting most explainable variance of brain activity in current datasets. Even in untrained models, the representations induced by architectural priors can exhibit reasonable alignment to brain data. In this work, we investigate the key architectural components driving the surprising alignment of untrained models. To estimate LLM-to-brain similarity, we first select language-selective units within an LLM, similar to how neuroscientists identify the language network in the human brain. We then benchmark the brain alignment of these LLM units across five different brain recording datasets. By isolating critical components of the Transformer architecture, we identify tokenization strategy and multihead attention as the two major components driving brain alignment. A simple form of recurrence further improves alignment. We further demonstrate this quantitative brain alignment of our model by reproducing landmark studies in the language neuroscience field, showing that localized model units -- just like language voxels measured empirically in the human brain -- discriminate more reliably between lexical than syntactic differences, and exhibit similar response profiles under the same experimental conditions. Finally, we demonstrate the utility of our model's representations for language modeling, achieving improved sample and parameter efficiency over comparable architectures. Our model's estimates of surprisal sets a new state-of-the-art in the behavioral alignment to human reading times. Taken together, we propose a highly brain- and behaviorally-aligned model that conceptualizes the human language system as an untrained shallow feature encoder, with structural priors, combined with a trained decoder to achieve efficient and performant language processing.
Read more6/24/2024

0
What Matters in Transformers? Not All Attention is Needed
Shwai He, Guoheng Sun, Zheyu Shen, Ang Li
Scaling Transformer-based large language models (LLMs) has demonstrated promising performance across various tasks. However, it also introduces redundant structures, posing challenges for real-world deployment. Despite some recognition of redundancy in LLMs, the variability of redundancy across different modules, such as MLP and Attention layers, is under-explored. In this work, we investigate the varying redundancy across different modules within Transformers, including Blocks, MLP, and Attention layers, using a similarity-based metric. This metric operates on the premise that redundant structures produce outputs highly similar to their inputs. Surprisingly, while attention layers are essential for transformers and distinguish them from other mainstream architectures, we found that a large proportion of attention layers exhibit excessively high similarity and can be safely pruned without degrading performance, leading to reduced memory and computation costs. Additionally, we further propose a method that jointly drops Attention and MLP layers, achieving improved performance and dropping ratios. Extensive experiments demonstrate the effectiveness of our methods, e.g., Llama-3-70B maintains comparable performance even after pruning half of the attention layers. Our findings provide valuable insights for future network architecture design. The code is released at: url{https://github.com/Shwai-He/LLM-Drop}.
Read more7/23/2024
🧪
56
Brainformers: Trading Simplicity for Efficiency
Yanqi Zhou, Nan Du, Yanping Huang, Daiyi Peng, Chang Lan, Da Huang, Siamak Shakeri, David So, Andrew Dai, Yifeng Lu, Zhifeng Chen, Quoc Le, Claire Cui, James Laudon, Jeff Dean
Transformers are central to recent successes in natural language processing and computer vision. Transformers have a mostly uniform backbone where layers alternate between feed-forward and self-attention in order to build a deep network. Here we investigate this design choice and find that more complex blocks that have different permutations of layer primitives can be more efficient. Using this insight, we develop a complex block, named Brainformer, that consists of a diverse sets of layers such as sparsely gated feed-forward layers, dense feed-forward layers, attention layers, and various forms of layer normalization and activation functions. Brainformer consistently outperforms the state-of-the-art dense and sparse Transformers, in terms of both quality and efficiency. A Brainformer model with 8 billion activated parameters per token demonstrates 2x faster training convergence and 5x faster step time compared to its GLaM counterpart. In downstream task evaluation, Brainformer also demonstrates a 3% higher SuperGLUE score with fine-tuning compared to GLaM with a similar number of activated parameters. Finally, Brainformer largely outperforms a Primer dense model derived with NAS with similar computation per token on fewshot evaluations.
Read more4/26/2024