SPP: Sparsity-Preserved Parameter-Efficient Fine-Tuning for Large Language Models
2405.16057
0
0
Abstract
Large Language Models (LLMs) have become pivotal in advancing the field of artificial intelligence, yet their immense sizes pose significant challenges for both fine-tuning and deployment. Current post-training pruning methods, while reducing the sizes of LLMs, often fail to maintain their original performance. To address these challenges, this paper introduces SPP, a Sparsity-Preserved Parameter-efficient fine-tuning method. Different from existing post-training pruning approaches that struggle with performance retention, SPP proposes to employ lightweight learnable column and row matrices to optimize sparse LLM weights, keeping the structure and sparsity of pruned pre-trained models intact. By element-wise multiplication and residual addition, SPP ensures the consistency of model sparsity pattern and ratio during both training and weight-merging processes. We demonstrate the effectiveness of SPP by applying it to the LLaMA and LLaMA-2 model families with recent post-training pruning methods. Our results show that SPP significantly enhances the performance of models with different sparsity patterns (i.e. unstructured and N:M sparsity), especially for those with high sparsity ratios (e.g. 75%), making it a promising solution for the efficient fine-tuning of sparse LLMs. Code will be made available at https://github.com/Lucky-Lance/SPP.
Create account to get full access
Overview
- This paper presents a new method called Sparsity-Preserved Parameter-Efficient Fine-Tuning (SPP) for fine-tuning large language models on specific tasks.
- SPP aims to achieve high performance while significantly reducing the number of parameters required, making fine-tuning more efficient and practical.
- The method leverages the inherent sparsity in the model's parameters during fine-tuning to preserve this sparsity, leading to a more compact model.
Plain English Explanation
Large language models, like GPT-3 or BERT, are powerful AI systems that can understand and generate human-like text. However, fine-tuning these models on specific tasks, such as answering questions or summarizing documents, typically requires retraining a significant portion of the model's parameters, which can be computationally expensive and time-consuming.
The SPP method introduced in this paper offers a more efficient approach. It takes advantage of the fact that these large models often have a lot of "unused" or "redundant" parameters, meaning that many of the model's internal connections don't contribute much to its performance. By preserving this inherent sparsity during the fine-tuning process, SPP is able to achieve high task performance while significantly reducing the number of parameters that need to be updated.
This is beneficial because it makes the fine-tuning process faster, requires less computational resources, and results in a more compact model that is easier to deploy and use in practical applications. It's a bit like how you can compress a file to make it smaller without losing important information – SPP does something similar with the parameters of a large language model.
Technical Explanation
The key innovation in the SPP method is the way it handles the model's parameters during fine-tuning. Typically, when fine-tuning a large language model, the majority of the model's parameters are updated, which can be computationally expensive and lead to a significant increase in the model's size.
In contrast, SPP leverages the inherent sparsity in the model's pre-trained parameters, meaning that many of the connections between the model's neurons are already weak or insignificant. During fine-tuning, SPP selectively updates only the most important parameters, while preserving the sparsity in the rest of the model. This is achieved through a specialized training procedure that includes a sparsity-preserving regularization term.
The authors demonstrate the effectiveness of SPP through experiments on a variety of language tasks, including text classification, question answering, and text generation. They show that SPP can achieve comparable or even better performance compared to standard fine-tuning, while reducing the number of updated parameters by up to 90%. This makes the fine-tuning process more efficient and results in a more compact model that is easier to deploy.
Critical Analysis
The SPP method presents a compelling approach to making fine-tuning of large language models more practical and efficient. By preserving the inherent sparsity in the model's parameters, it is able to achieve significant reductions in the number of parameters that need to be updated, without sacrificing task performance.
One potential limitation of the method is that it may not be as effective on tasks that require more significant changes to the model's parameters, such as those involving significant architectural modifications or the addition of new layers. The authors acknowledge this and suggest that SPP may be most useful for fine-tuning on relatively similar tasks to the model's pre-training.
Additionally, the paper does not provide a deep analysis of the mechanisms by which SPP is able to preserve sparsity during fine-tuning. Further research into the underlying dynamics of this process could lead to additional insights and potential improvements to the method.
Overall, the SPP method represents an important contribution to the field of parameter-efficient fine-tuning for large language models, which is an active area of research. The sparsity-aware pruning, efficient pruning of pre-trained models, and understanding the role of gradients in pruning are all related areas that could benefit from further exploration.
Conclusion
The SPP method presented in this paper offers a promising approach to making fine-tuning of large language models more efficient and practical. By preserving the inherent sparsity in the model's parameters during the fine-tuning process, SPP is able to achieve comparable or better task performance while significantly reducing the number of parameters that need to be updated.
This has important implications for the deployment and use of large language models in real-world applications, as it can lead to more compact and efficient models that are easier to run on resource-constrained devices or in low-latency settings. The research on sparse fine-tuning and the role of gradients in pruning decisions further highlights the importance of this line of research.
As the field of natural language processing continues to advance, methods like SPP that enable more efficient and practical fine-tuning of large language models will become increasingly valuable, paving the way for the widespread deployment of these powerful AI systems in a wide range of real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Sparsity-Accelerated Training for Large Language Models
Da Ma, Lu Chen, Pengyu Wang, Hongshen Xu, Hanqi Li, Liangtai Sun, Su Zhu, Shuai Fan, Kai Yu
0
0
Large language models (LLMs) have demonstrated proficiency across various natural language processing (NLP) tasks but often require additional training, such as continual pre-training and supervised fine-tuning. However, the costs associated with this, primarily due to their large parameter count, remain high. This paper proposes leveraging emph{sparsity} in pre-trained LLMs to expedite this training process. By observing sparsity in activated neurons during forward iterations, we identify the potential for computational speed-ups by excluding inactive neurons. We address associated challenges by extending existing neuron importance evaluation metrics and introducing a ladder omission rate scheduler. Our experiments on Llama-2 demonstrate that Sparsity-Accelerated Training (SAT) achieves comparable or superior performance to standard training while significantly accelerating the process. Specifically, SAT achieves a $45%$ throughput improvement in continual pre-training and saves $38%$ training time in supervised fine-tuning in practice. It offers a simple, hardware-agnostic, and easily deployable framework for additional LLM training. Our code is available at https://github.com/OpenDFM/SAT.
6/7/2024
💬
One-Shot Sensitivity-Aware Mixed Sparsity Pruning for Large Language Models
Hang Shao, Bei Liu, Bo Xiao, Ke Zeng, Guanglu Wan, Yanmin Qian
0
0
Various Large Language Models~(LLMs) from the Generative Pretrained Transformer(GPT) family have achieved outstanding performances in a wide range of text generation tasks. However, the enormous model sizes have hindered their practical use in real-world applications due to high inference latency. Therefore, improving the efficiencies of LLMs through quantization, pruning, and other means has been a key issue in LLM studies. In this work, we propose a method based on Hessian sensitivity-aware mixed sparsity pruning to prune LLMs to at least 50% sparsity without the need of any retraining. It allocates sparsity adaptively based on sensitivity, allowing us to reduce pruning-induced error while maintaining the overall sparsity level. The advantages of the proposed method exhibit even more when the sparsity is extremely high. Furthermore, our method is compatible with quantization, enabling further compression of LLMs. We have released the available code.
4/24/2024
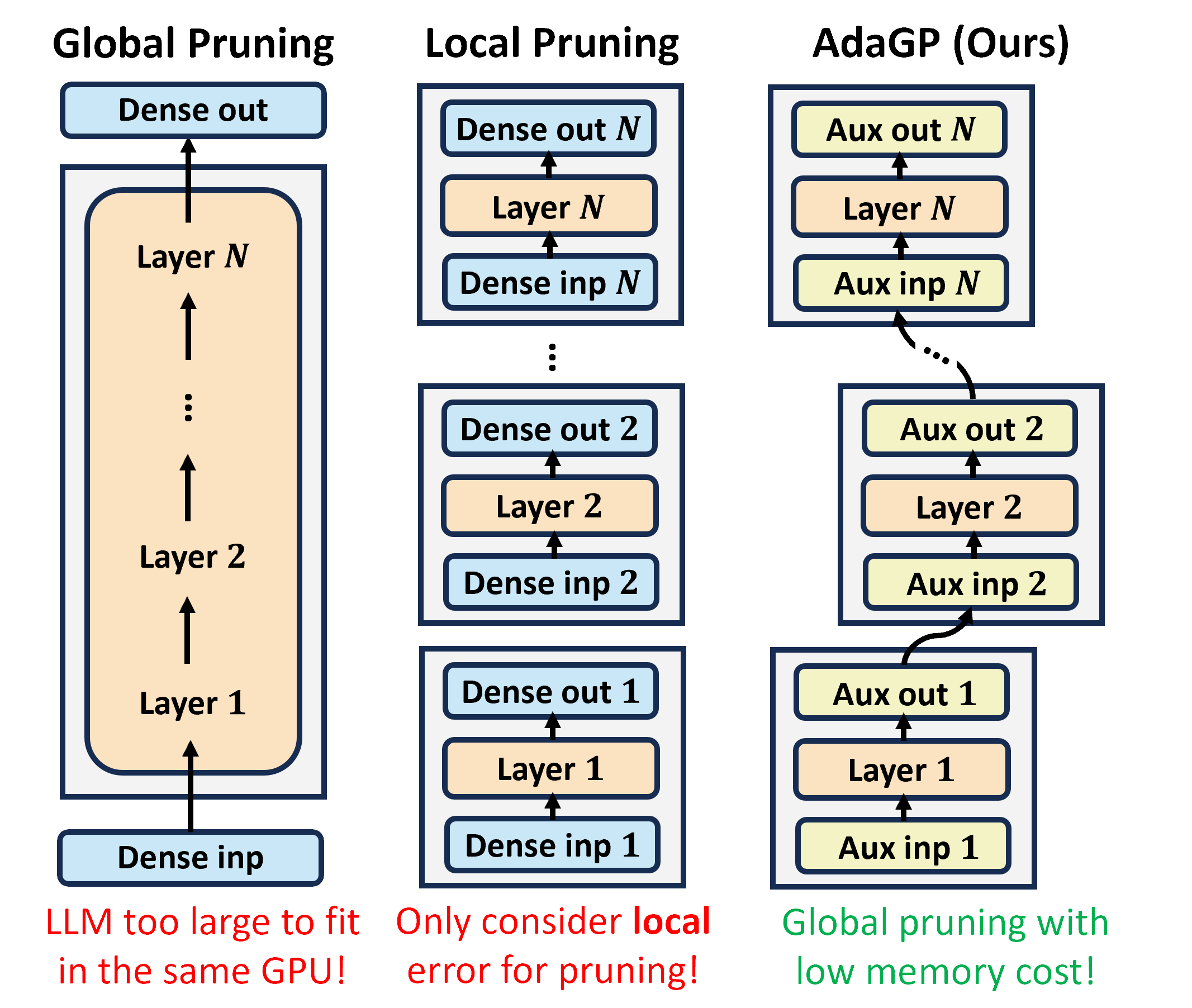
SparseLLM: Towards Global Pruning for Pre-trained Language Models
Guangji Bai, Yijiang Li, Chen Ling, Kibaek Kim, Liang Zhao
0
0
The transformative impact of large language models (LLMs) like LLaMA and GPT on natural language processing is countered by their prohibitive computational demands. Pruning has emerged as a pivotal compression strategy, introducing sparsity to enhance both memory and computational efficiency. Yet, traditional global pruning is impractical for LLMs due to scalability issues, while local pruning, despite its efficiency, leads to suboptimal solutions. Addressing these challenges, we propose SparseLLM, a novel framework that redefines the global pruning process into manageable, coordinated subproblems, allowing for resource-efficient optimization with global optimality. SparseLLM's approach, which conceptualizes LLMs as a chain of modular functions and leverages auxiliary variables for problem decomposition, not only facilitates a pragmatic application on LLMs but also demonstrates significant performance improvements, particularly in high-sparsity regimes where it surpasses current state-of-the-art methods.
5/27/2024
❗
Enabling High-Sparsity Foundational Llama Models with Efficient Pretraining and Deployment
Abhinav Agarwalla, Abhay Gupta, Alexandre Marques, Shubhra Pandit, Michael Goin, Eldar Kurtic, Kevin Leong, Tuan Nguyen, Mahmoud Salem, Dan Alistarh, Sean Lie, Mark Kurtz
0
0
Large language models (LLMs) have revolutionized Natural Language Processing (NLP), but their size creates computational bottlenecks. We introduce a novel approach to create accurate, sparse foundational versions of performant LLMs that achieve full accuracy recovery for fine-tuning tasks at up to 70% sparsity. We achieve this for the LLaMA-2 7B model by combining the SparseGPT one-shot pruning method and sparse pretraining of those models on a subset of the SlimPajama dataset mixed with a Python subset of The Stack dataset. We exhibit training acceleration due to sparsity on Cerebras CS-3 chips that closely matches theoretical scaling. In addition, we establish inference acceleration of up to 3x on CPUs by utilizing Neural Magic's DeepSparse engine and 1.7x on GPUs through Neural Magic's nm-vllm engine. The above gains are realized via sparsity alone, thus enabling further gains through additional use of quantization. Specifically, we show a total speedup on CPUs for sparse-quantized LLaMA models of up to 8.6x. We demonstrate these results across diverse, challenging tasks, including chat, instruction following, code generation, arithmetic reasoning, and summarization to prove their generality. This work paves the way for rapidly creating smaller and faster LLMs without sacrificing accuracy.
5/7/2024