Sparsity-Accelerated Training for Large Language Models
2406.01392
0
0

Abstract
Large language models (LLMs) have demonstrated proficiency across various natural language processing (NLP) tasks but often require additional training, such as continual pre-training and supervised fine-tuning. However, the costs associated with this, primarily due to their large parameter count, remain high. This paper proposes leveraging emph{sparsity} in pre-trained LLMs to expedite this training process. By observing sparsity in activated neurons during forward iterations, we identify the potential for computational speed-ups by excluding inactive neurons. We address associated challenges by extending existing neuron importance evaluation metrics and introducing a ladder omission rate scheduler. Our experiments on Llama-2 demonstrate that Sparsity-Accelerated Training (SAT) achieves comparable or superior performance to standard training while significantly accelerating the process. Specifically, SAT achieves a $45%$ throughput improvement in continual pre-training and saves $38%$ training time in supervised fine-tuning in practice. It offers a simple, hardware-agnostic, and easily deployable framework for additional LLM training. Our code is available at https://github.com/OpenDFM/SAT.
Create account to get full access
Overview
- The paper explores "Sparsity-Accelerated Training for Large Language Models", a novel approach to training large language models more efficiently.
- It presents techniques to increase the sparsity (number of zero-valued parameters) in the model while maintaining performance, leading to faster training and inference.
- The proposed methods build on recent developments in sparse training and pruning, including Enabling High Sparsity in Foundational LLaMA Models, SPP: Sparsity-Preserved Parameter-Efficient Fine-Tuning, and One-Shot Sensitivity-Aware Mixed Sparsity Pruning.
Plain English Explanation
The paper focuses on making large language models, like GPT-3 or BERT, more efficient to train and use. These models are incredibly powerful, but they also require a lot of computing power and take a long time to train.
The key idea is to increase the sparsity of the model, which means having more zero-valued parameters. This allows the model to be stored and processed more efficiently, without significantly impacting its performance.
The researchers develop several techniques to achieve this increased sparsity, building on previous work in the field. For example, they use "sensitivity-aware" pruning, which identifies the most important parameters and keeps them while removing the less important ones.
By making the models more sparse, the training and inference (using the model) processes become faster and more efficient. This could lead to significant cost savings and environmental benefits, as large language models consume a lot of energy during training and deployment.
The paper also discusses how these sparsity-accelerated techniques can be applied to fine-tuning, where a pre-trained model is adapted to a specific task or dataset. This is important, as fine-tuning is a common practice in the field of natural language processing.
Technical Explanation
The paper presents a framework for "Sparsity-Accelerated Training for Large Language Models", which aims to increase the sparsity of the model parameters while maintaining performance.
The key technical contributions include:
-
Sensitivity-Aware Pruning: The researchers develop a pruning method that identifies the most important parameters in the model and preserves them, while removing the less important ones. This is based on the One-Shot Sensitivity-Aware Mixed Sparsity Pruning technique.
-
Sparsity-Preserved Fine-Tuning: The paper explores methods for fine-tuning pre-trained language models while preserving the sparsity structure, building on the SPP: Sparsity-Preserved Parameter-Efficient Fine-Tuning approach.
-
Contextually-Aware Thresholding: The researchers propose a technique called "Contextually-Aware Thresholding for Sparsity" (CATS), which dynamically adjusts the sparsity threshold based on the input context. This is inspired by the CATS: Contextually Aware Thresholding for Sparsity in Large Language Models method.
The paper evaluates the proposed techniques on various language modeling tasks, demonstrating significant improvements in training efficiency and inference speed, while maintaining comparable model performance.
Critical Analysis
The paper presents a well-designed and thoughtful approach to improving the efficiency of large language models through sparsity-accelerated training. The techniques build on and extend previous work in the field, showing a clear progression of research.
One potential limitation is that the paper does not explore the impact of these sparsity-accelerated methods on the generalization performance of the models. While the authors demonstrate maintained performance on the evaluated tasks, it would be valuable to understand how the increased sparsity affects the models' ability to handle a broader range of inputs and tasks.
Additionally, the paper could benefit from a more in-depth discussion of the practical implications and real-world applications of the proposed techniques. For example, how might these methods impact the deployment of large language models in resource-constrained environments or at scale?
Further research could also explore the interplay between sparsity, model capacity, and task-specific performance. Sparsity-Accelerated Training for Large Language Models is a promising direction, but there may be additional opportunities to optimize the balance between model efficiency and effectiveness.
Conclusion
The paper presents a compelling approach to improving the training and deployment of large language models through sparsity-accelerated techniques. By increasing the sparsity of the model parameters, the researchers demonstrate significant gains in efficiency without compromising performance.
These methods have the potential to drive down the significant computational and energy costs associated with large language models, making them more accessible and environmentally sustainable. As the field of natural language processing continues to advance, techniques like those proposed in this paper will be essential for unlocking the full potential of these powerful models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
❗
Enabling High-Sparsity Foundational Llama Models with Efficient Pretraining and Deployment
Abhinav Agarwalla, Abhay Gupta, Alexandre Marques, Shubhra Pandit, Michael Goin, Eldar Kurtic, Kevin Leong, Tuan Nguyen, Mahmoud Salem, Dan Alistarh, Sean Lie, Mark Kurtz
0
0
Large language models (LLMs) have revolutionized Natural Language Processing (NLP), but their size creates computational bottlenecks. We introduce a novel approach to create accurate, sparse foundational versions of performant LLMs that achieve full accuracy recovery for fine-tuning tasks at up to 70% sparsity. We achieve this for the LLaMA-2 7B model by combining the SparseGPT one-shot pruning method and sparse pretraining of those models on a subset of the SlimPajama dataset mixed with a Python subset of The Stack dataset. We exhibit training acceleration due to sparsity on Cerebras CS-3 chips that closely matches theoretical scaling. In addition, we establish inference acceleration of up to 3x on CPUs by utilizing Neural Magic's DeepSparse engine and 1.7x on GPUs through Neural Magic's nm-vllm engine. The above gains are realized via sparsity alone, thus enabling further gains through additional use of quantization. Specifically, we show a total speedup on CPUs for sparse-quantized LLaMA models of up to 8.6x. We demonstrate these results across diverse, challenging tasks, including chat, instruction following, code generation, arithmetic reasoning, and summarization to prove their generality. This work paves the way for rapidly creating smaller and faster LLMs without sacrificing accuracy.
5/7/2024
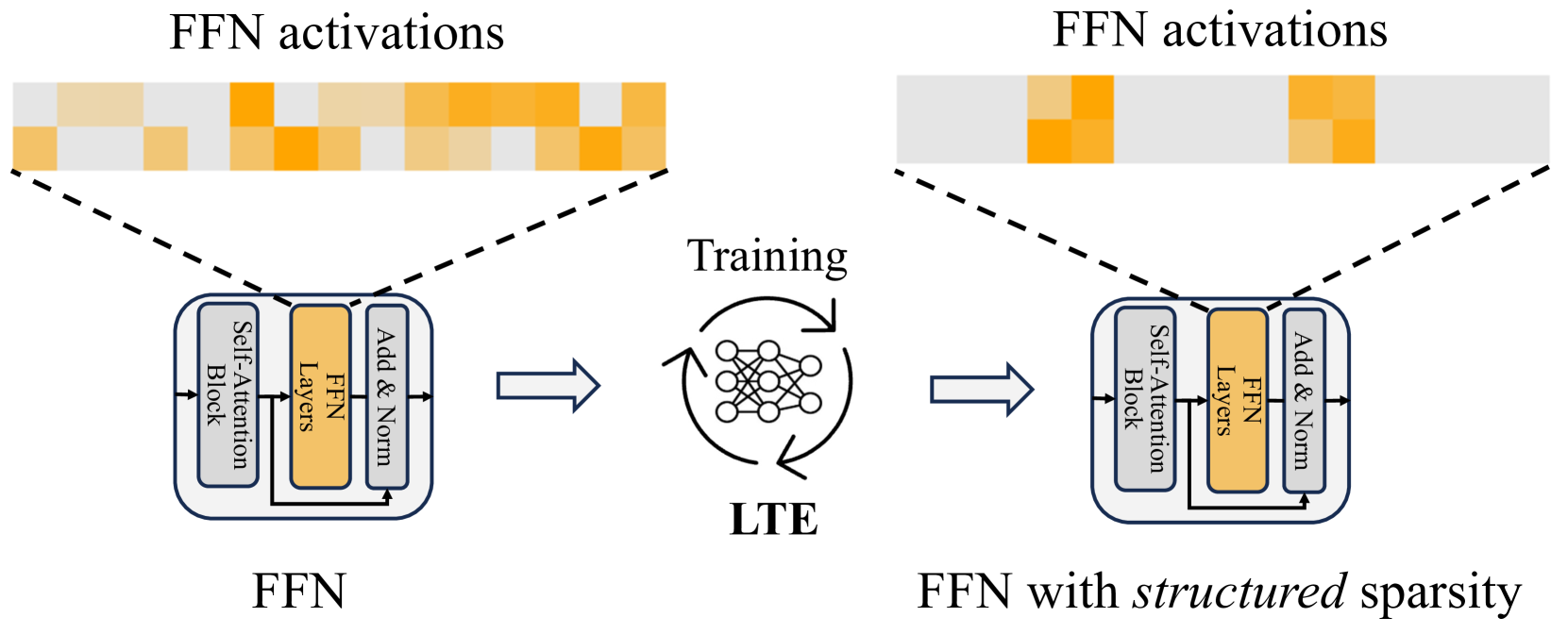
Learn To be Efficient: Build Structured Sparsity in Large Language Models
Haizhong Zheng, Xiaoyan Bai, Xueshen Liu, Z. Morley Mao, Beidi Chen, Fan Lai, Atul Prakash
0
0
Large Language Models (LLMs) have achieved remarkable success with their billion-level parameters, yet they incur high inference overheads. The emergence of activation sparsity in LLMs provides a natural approach to reduce this cost by involving only parts of the parameters for inference. However, existing methods only focus on utilizing this naturally formed activation sparsity in a post-training setting, overlooking the potential for further amplifying this inherent sparsity. In this paper, we hypothesize that LLMs can learn to be efficient by achieving more structured activation sparsity. To achieve this, we introduce a novel training algorithm, Learn-To-be-Efficient (LTE), designed to train efficiency-aware LLMs to learn to activate fewer neurons and achieve a better trade-off between sparsity and performance. Furthermore, unlike SOTA MoEfication methods, which mainly focus on ReLU-based models, LTE can also be applied to LLMs like LLaMA using non-ReLU activations. Extensive evaluation on language understanding, language generation, and instruction tuning tasks show that LTE consistently outperforms SOTA baselines. Along with our hardware-aware custom kernel implementation, LTE reduces LLaMA2-7B inference latency by 25% at 50% sparsity.
6/5/2024
SPP: Sparsity-Preserved Parameter-Efficient Fine-Tuning for Large Language Models
Xudong Lu, Aojun Zhou, Yuhui Xu, Renrui Zhang, Peng Gao, Hongsheng Li
0
0
Large Language Models (LLMs) have become pivotal in advancing the field of artificial intelligence, yet their immense sizes pose significant challenges for both fine-tuning and deployment. Current post-training pruning methods, while reducing the sizes of LLMs, often fail to maintain their original performance. To address these challenges, this paper introduces SPP, a Sparsity-Preserved Parameter-efficient fine-tuning method. Different from existing post-training pruning approaches that struggle with performance retention, SPP proposes to employ lightweight learnable column and row matrices to optimize sparse LLM weights, keeping the structure and sparsity of pruned pre-trained models intact. By element-wise multiplication and residual addition, SPP ensures the consistency of model sparsity pattern and ratio during both training and weight-merging processes. We demonstrate the effectiveness of SPP by applying it to the LLaMA and LLaMA-2 model families with recent post-training pruning methods. Our results show that SPP significantly enhances the performance of models with different sparsity patterns (i.e. unstructured and N:M sparsity), especially for those with high sparsity ratios (e.g. 75%), making it a promising solution for the efficient fine-tuning of sparse LLMs. Code will be made available at https://github.com/Lucky-Lance/SPP.
5/28/2024
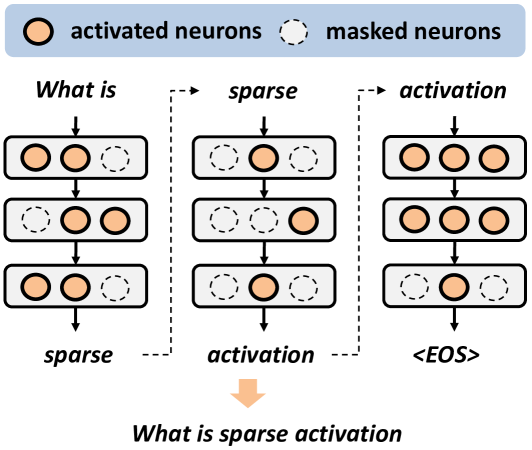
Achieving Sparse Activation in Small Language Models
Jifeng Song, Kai Huang, Xiangyu Yin, Boyuan Yang, Wei Gao
0
0
Sparse activation, which selectively activates only an input-dependent set of neurons in inference, is a useful technique to reduce the computing cost of Large Language Models (LLMs) without retraining or adaptation efforts. However, whether it can be applied to the recently emerging Small Language Models (SLMs) remains questionable, because SLMs are generally less over-parameterized than LLMs. In this paper, we aim to achieve sparse activation in SLMs. We first show that the existing sparse activation schemes in LLMs that build on neurons' output magnitudes cannot be applied to SLMs, and activating neurons based on their attribution scores is a better alternative. Further, we demonstrated and quantified the large errors of existing attribution metrics when being used for sparse activation, due to the interdependency among attribution scores of neurons across different layers. Based on these observations, we proposed a new attribution metric that can provably correct such errors and achieve precise sparse activation. Experiments over multiple popular SLMs and datasets show that our approach can achieve 80% sparsification ratio with <5% model accuracy loss, comparable to the sparse activation achieved in LLMs. The source code is available at: https://github.com/pittisl/Sparse-Activation.
6/12/2024