StableSemantics: A Synthetic Language-Vision Dataset of Semantic Representations in Naturalistic Images
2406.13735
1
0

Abstract
Understanding the semantics of visual scenes is a fundamental challenge in Computer Vision. A key aspect of this challenge is that objects sharing similar semantic meanings or functions can exhibit striking visual differences, making accurate identification and categorization difficult. Recent advancements in text-to-image frameworks have led to models that implicitly capture natural scene statistics. These frameworks account for the visual variability of objects, as well as complex object co-occurrences and sources of noise such as diverse lighting conditions. By leveraging large-scale datasets and cross-attention conditioning, these models generate detailed and contextually rich scene representations. This capability opens new avenues for improving object recognition and scene understanding in varied and challenging environments. Our work presents StableSemantics, a dataset comprising 224 thousand human-curated prompts, processed natural language captions, over 2 million synthetic images, and 10 million attention maps corresponding to individual noun chunks. We explicitly leverage human-generated prompts that correspond to visually interesting stable diffusion generations, provide 10 generations per phrase, and extract cross-attention maps for each image. We explore the semantic distribution of generated images, examine the distribution of objects within images, and benchmark captioning and open vocabulary segmentation methods on our data. To the best of our knowledge, we are the first to release a diffusion dataset with semantic attributions. We expect our proposed dataset to catalyze advances in visual semantic understanding and provide a foundation for developing more sophisticated and effective visual models. Website: https://stablesemantics.github.io/StableSemantics
Create account to get full access
Overview
- This paper introduces a new synthetic dataset called "StableSemantics" that aims to capture semantic representations in naturalistic images.
- The dataset is designed to support research on language-vision models and their ability to understand and reason about the semantic content of images.
- The dataset consists of paired images and semantic annotations, created using a novel text-to-image generation approach that aims to produce realistic-looking images.
Plain English Explanation
The researchers who created this dataset wanted to build tools that can better understand the meaning and content of images, not just what they look like on the surface. To do this, they created a large collection of images and paired them with detailed descriptions of the semantic information they contain.
The key idea is that by training language-vision models on this dataset, they will be able to learn how to extract and reason about the deeper meaning and conceptual content of images, beyond just recognizing the objects and scenes depicted. This could enable more advanced applications in areas like computer vision, image understanding, and multimodal AI.
The dataset was created using a novel text-to-image generation approach, which allowed the researchers to produce realistic-looking images that match the semantic annotations. This synthetic approach gives them more control and flexibility compared to using only real-world images and annotations.
Technical Explanation
The StableSemantics dataset consists of over 1 million paired images and semantic annotations. The images were generated using a text-to-image model inspired by SynthDollar2Dollar, while the annotations were created through a novel semantic encoding process.
The semantic annotations capture a rich set of information about the content of each image, including object-level descriptions, scene-level attributes, relationships between elements, and abstract concepts. This goes beyond typical image captioning datasets, which tend to focus more on surface-level descriptions.
The dataset is designed to support research on language-vision models and their ability to understand and reason about the semantic content of images. By training on this dataset, models can learn to extract and leverage the deeper conceptual information, which could enable more advanced applications in areas like visual classification and semantic-guided image generation.
Critical Analysis
The authors acknowledge that the synthetic nature of the dataset may limit its direct applicability to real-world scenarios. There are also potential concerns about the potential for biases or artifacts introduced by the text-to-image generation process.
Additionally, the paper does not provide a comprehensive evaluation of the dataset's quality or its impact on downstream tasks. Further research would be needed to assess the practical utility of the StableSemantics dataset and the language-vision models trained on it.
Overall, the StableSemantics dataset represents an interesting and potentially valuable contribution to the field of language-vision research. However, its long-term impact will depend on the ability of researchers to address the limitations and further validate its usefulness for advancing the state of the art in this domain.
Conclusion
The StableSemantics dataset is a novel synthetic dataset that aims to capture rich semantic representations in naturalistic images. By training language-vision models on this dataset, researchers hope to enable more advanced applications in areas like computer vision, image understanding, and multimodal AI.
While the synthetic nature of the dataset introduces some potential limitations, the conceptual depth of the semantic annotations and the flexibility of the text-to-image generation approach make StableSemantics a promising resource for furthering our understanding of how language and vision can be effectively integrated. As the field continues to progress, datasets like this will play an important role in driving innovation and expanding the capabilities of these powerful AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
Semantica: An Adaptable Image-Conditioned Diffusion Model
Manoj Kumar, Neil Houlsby, Emiel Hoogeboom
0
0
We investigate the task of adapting image generative models to different datasets without finetuneing. To this end, we introduce Semantica, an image-conditioned diffusion model capable of generating images based on the semantics of a conditioning image. Semantica is trained exclusively on web-scale image pairs, that is it receives a random image from a webpage as conditional input and models another random image from the same webpage. Our experiments highlight the expressivity of pretrained image encoders and necessity of semantic-based data filtering in achieving high-quality image generation. Once trained, it can adaptively generate new images from a dataset by simply using images from that dataset as input. We study the transfer properties of Semantica on ImageNet, LSUN Churches, LSUN Bedroom and SUN397.
6/11/2024
Synth$^2$: Boosting Visual-Language Models with Synthetic Captions and Image Embeddings
Sahand Sharifzadeh, Christos Kaplanis, Shreya Pathak, Dharshan Kumaran, Anastasija Ilic, Jovana Mitrovic, Charles Blundell, Andrea Banino
0
0
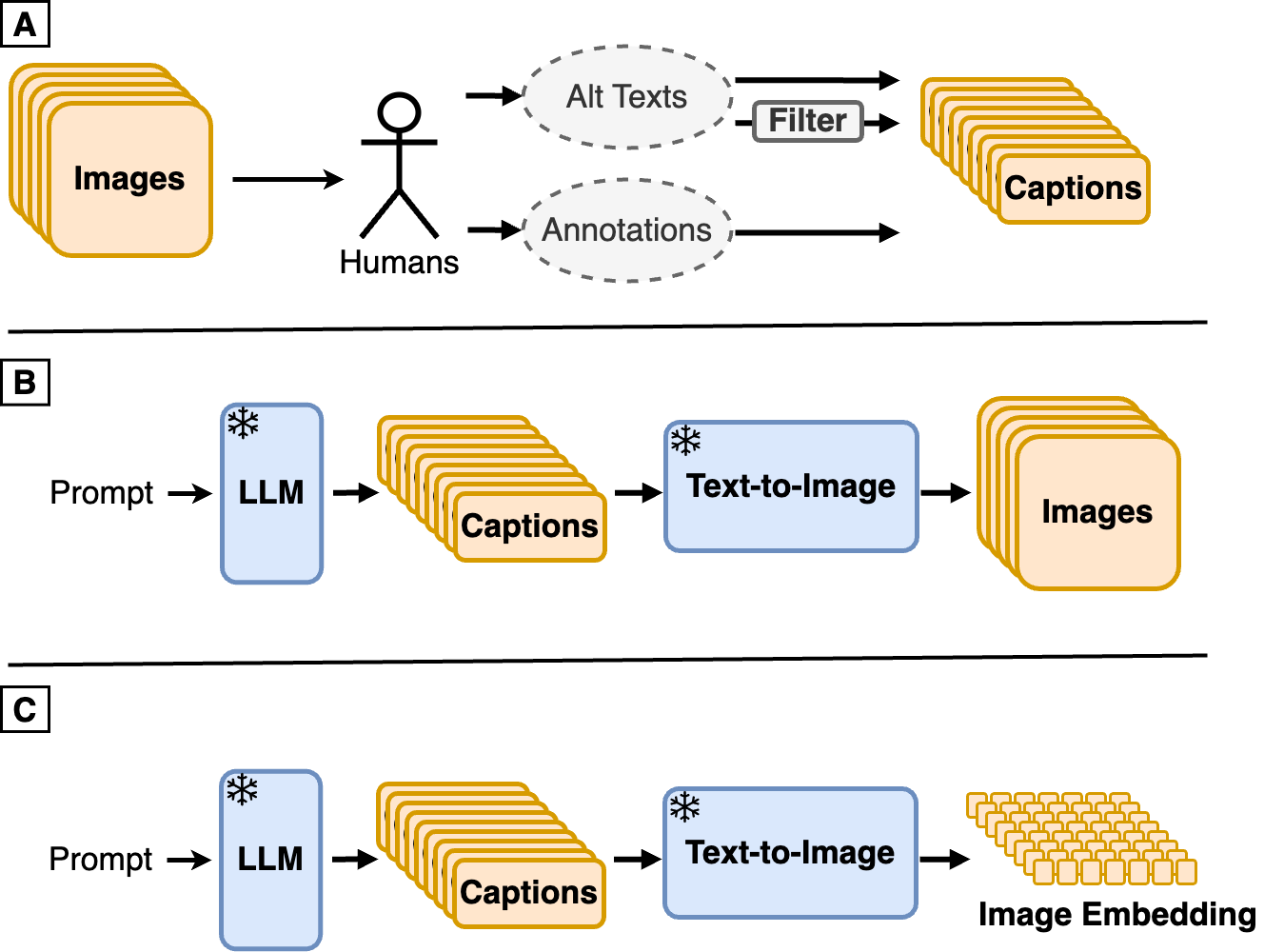
The creation of high-quality human-labeled image-caption datasets presents a significant bottleneck in the development of Visual-Language Models (VLMs). In this work, we investigate an approach that leverages the strengths of Large Language Models (LLMs) and image generation models to create synthetic image-text pairs for efficient and effective VLM training. Our method employs a pretrained text-to-image model to synthesize image embeddings from captions generated by an LLM. Despite the text-to-image model and VLM initially being trained on the same data, our approach leverages the image generator's ability to create novel compositions, resulting in synthetic image embeddings that expand beyond the limitations of the original dataset. Extensive experiments demonstrate that our VLM, finetuned on synthetic data achieves comparable performance to models trained solely on human-annotated data, while requiring significantly less data. Furthermore, we perform a set of analyses on captions which reveals that semantic diversity and balance are key aspects for better downstream performance. Finally, we show that synthesizing images in the image embedding space is 25% faster than in the pixel space. We believe our work not only addresses a significant challenge in VLM training but also opens up promising avenues for the development of self-improving multi-modal models.
6/10/2024

Visual Car Brand Classification by Implementing a Synthetic Image Dataset Creation Pipeline
Jan Lippemeier, Stefanie Hittmeyer, Oliver Niehorster, Markus Lange-Hegermann
0
0
Recent advancements in machine learning, particularly in deep learning and object detection, have significantly improved performance in various tasks, including image classification and synthesis. However, challenges persist, particularly in acquiring labeled data that accurately represents specific use cases. In this work, we propose an automatic pipeline for generating synthetic image datasets using Stable Diffusion, an image synthesis model capable of producing highly realistic images. We leverage YOLOv8 for automatic bounding box detection and quality assessment of synthesized images. Our contributions include demonstrating the feasibility of training image classifiers solely on synthetic data, automating the image generation pipeline, and describing the computational requirements for our approach. We evaluate the usability of different modes of Stable Diffusion and achieve a classification accuracy of 75%.
6/4/2024
Simple Semantic-Aided Few-Shot Learning
Hai Zhang, Junzhe Xu, Shanlin Jiang, Zhenan He
0
0
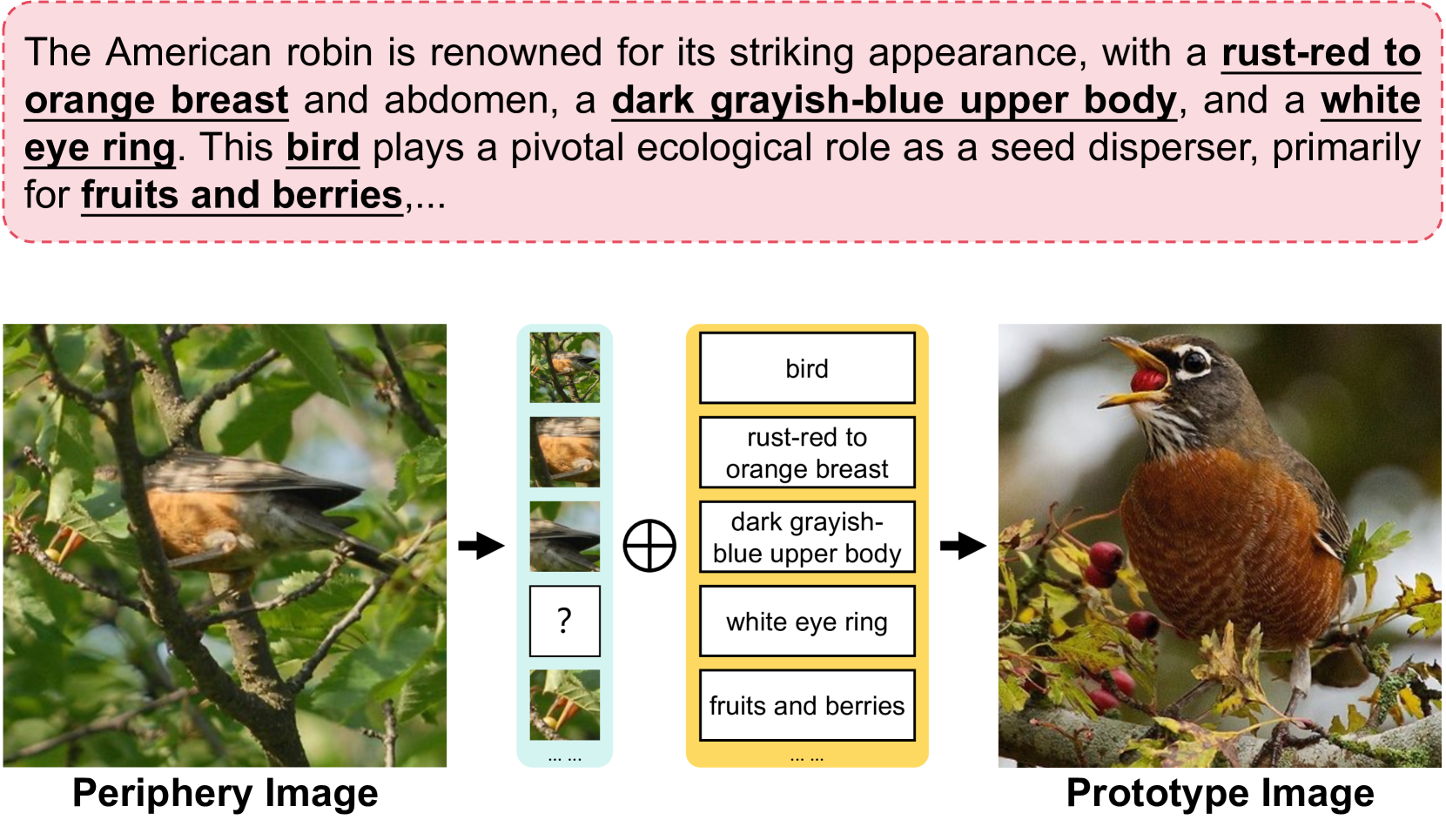
Learning from a limited amount of data, namely Few-Shot Learning, stands out as a challenging computer vision task. Several works exploit semantics and design complicated semantic fusion mechanisms to compensate for rare representative features within restricted data. However, relying on naive semantics such as class names introduces biases due to their brevity, while acquiring extensive semantics from external knowledge takes a huge time and effort. This limitation severely constrains the potential of semantics in Few-Shot Learning. In this paper, we design an automatic way called Semantic Evolution to generate high-quality semantics. The incorporation of high-quality semantics alleviates the need for complex network structures and learning algorithms used in previous works. Hence, we employ a simple two-layer network termed Semantic Alignment Network to transform semantics and visual features into robust class prototypes with rich discriminative features for few-shot classification. The experimental results show our framework outperforms all previous methods on six benchmarks, demonstrating a simple network with high-quality semantics can beat intricate multi-modal modules on few-shot classification tasks. Code is available at https://github.com/zhangdoudou123/SemFew.
4/10/2024