Visual Car Brand Classification by Implementing a Synthetic Image Dataset Creation Pipeline
2406.01071
0
0

Abstract
Recent advancements in machine learning, particularly in deep learning and object detection, have significantly improved performance in various tasks, including image classification and synthesis. However, challenges persist, particularly in acquiring labeled data that accurately represents specific use cases. In this work, we propose an automatic pipeline for generating synthetic image datasets using Stable Diffusion, an image synthesis model capable of producing highly realistic images. We leverage YOLOv8 for automatic bounding box detection and quality assessment of synthesized images. Our contributions include demonstrating the feasibility of training image classifiers solely on synthetic data, automating the image generation pipeline, and describing the computational requirements for our approach. We evaluate the usability of different modes of Stable Diffusion and achieve a classification accuracy of 75%.
Create account to get full access
Overview
- This paper explores the creation of a synthetic image dataset for visual car brand classification.
- The researchers implemented a pipeline to generate realistic-looking synthetic car images using techniques like Stable Diffusion.
- They then trained deep learning models on this synthetic dataset and evaluated their performance on real-world car image classification tasks.
Plain English Explanation
The researchers in this study wanted to build a system that could accurately identify the brand of a car just from looking at an image of it. However, getting enough real-world car images to train such a system can be challenging and expensive.
To address this, the researchers developed a way to generate synthetic, computer-created car images that look very realistic. They used advanced AI techniques like Stable Diffusion to generate these synthetic images. The key insight was that training machine learning models on these realistic-looking synthetic images could help them perform better on real-world car brand classification tasks, even though the training data was not real.
The researchers then tested this approach by training several different machine learning models on their synthetic car image dataset, and evaluating how well those models could identify the brand of cars in real photographs. The results showed that the models trained on synthetic data were able to achieve high accuracy on the real-world classification task, demonstrating the potential of using synthetic data to improve computer vision systems.
Technical Explanation
The researchers first built a pipeline to generate a large synthetic dataset of car images. This involved using techniques like Stable Diffusion to create highly realistic-looking car images, with control over factors like the car model, viewpoint, lighting, and background.
They then trained several deep learning models, including convolutional neural networks and transformers, on this synthetic dataset. The models were tasked with classifying the car brand (e.g. Toyota, Ford, BMW) based solely on the visual appearance of the cars in the images.
To evaluate the models, the researchers tested them on real-world car image datasets that were held out from the training process. The results showed that the models trained on synthetic data were able to achieve high classification accuracy, outperforming models trained on limited real-world datasets. This suggests that the synthetic dataset was effective at capturing the key visual features needed for accurate car brand classification.
Critical Analysis
The researchers acknowledge several limitations of their work. First, the synthetic images, while highly realistic, may still differ in subtle ways from real-world car images, which could impact the models' performance. Additionally, the researchers only evaluated their approach on a single car brand classification task - it remains to be seen how well it would generalize to other computer vision problems.
Another potential issue is the risk of using synthetic data to train models that can be fooled by adversarial attacks. If the synthetic images do not accurately capture all the important visual nuances, models trained on them may be vulnerable to being "hacked" by carefully crafted adversarial examples.
That said, the researchers' work demonstrates the promising potential of using synthetic data to improve transfer learning and classification performance, especially in domains like industrial parts classification where collecting real-world training data can be challenging. Further research is needed to fully understand the tradeoffs and limitations of this approach, but the results are encouraging.
Conclusion
This paper presents a novel pipeline for generating a large synthetic dataset of car images and demonstrates its effectiveness in training deep learning models for accurate car brand classification. The results suggest that high-quality synthetic data can be a valuable tool for developing computer vision systems, especially when real-world data is scarce or expensive to obtain.
While there are still open questions around the broader applicability and potential vulnerabilities of this approach, the researchers' work highlights the exciting potential of using synthetic data to enhance machine learning performance. As the field of AI continues to advance, techniques like this could become increasingly important for building robust and capable computer vision systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Stable Diffusion Dataset Generation for Downstream Classification Tasks
Eugenio Lomurno, Matteo D'Oria, Matteo Matteucci
0
0
Recent advances in generative artificial intelligence have enabled the creation of high-quality synthetic data that closely mimics real-world data. This paper explores the adaptation of the Stable Diffusion 2.0 model for generating synthetic datasets, using Transfer Learning, Fine-Tuning and generation parameter optimisation techniques to improve the utility of the dataset for downstream classification tasks. We present a class-conditional version of the model that exploits a Class-Encoder and optimisation of key generation parameters. Our methodology led to synthetic datasets that, in a third of cases, produced models that outperformed those trained on real datasets.
5/7/2024

Harnessing Machine Learning for Discerning AI-Generated Synthetic Images
Yuyang Wang, Yizhi Hao, Amando Xu Cong
0
0
In the realm of digital media, the advent of AI-generated synthetic images has introduced significant challenges in distinguishing between real and fabricated visual content. These images, often indistinguishable from authentic ones, pose a threat to the credibility of digital media, with potential implications for disinformation and fraud. Our research addresses this challenge by employing machine learning techniques to discern between AI-generated and genuine images. Central to our approach is the CIFAKE dataset, a comprehensive collection of images labeled as Real and Fake. We refine and adapt advanced deep learning architectures like ResNet, VGGNet, and DenseNet, utilizing transfer learning to enhance their precision in identifying synthetic images. We also compare these with a baseline model comprising a vanilla Support Vector Machine (SVM) and a custom Convolutional Neural Network (CNN). The experimental results were significant, demonstrating that our optimized deep learning models outperform traditional methods, with DenseNet achieving an accuracy of 97.74%. Our application study contributes by applying and optimizing these advanced models for synthetic image detection, conducting a comparative analysis using various metrics, and demonstrating their superior capability in identifying AI-generated images over traditional machine learning techniques. This research not only advances the field of digital media integrity but also sets a foundation for future explorations into the ethical and technical dimensions of AI-generated content in digital media.
5/27/2024
Is Synthetic Image Useful for Transfer Learning? An Investigation into Data Generation, Volume, and Utilization
Yuhang Li, Xin Dong, Chen Chen, Jingtao Li, Yuxin Wen, Michael Spranger, Lingjuan Lyu
0
0
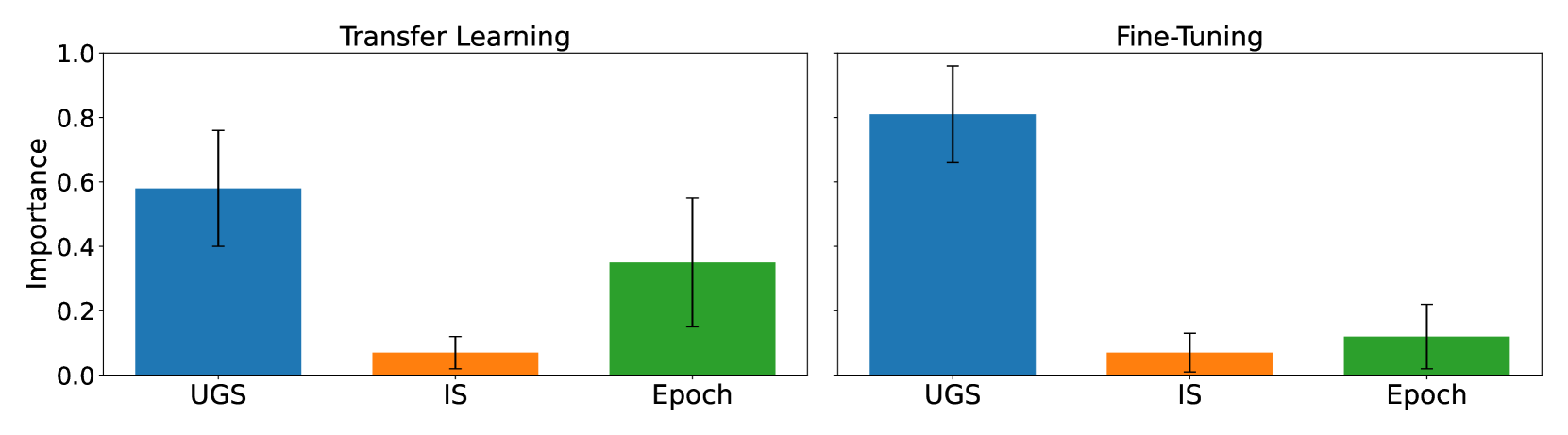
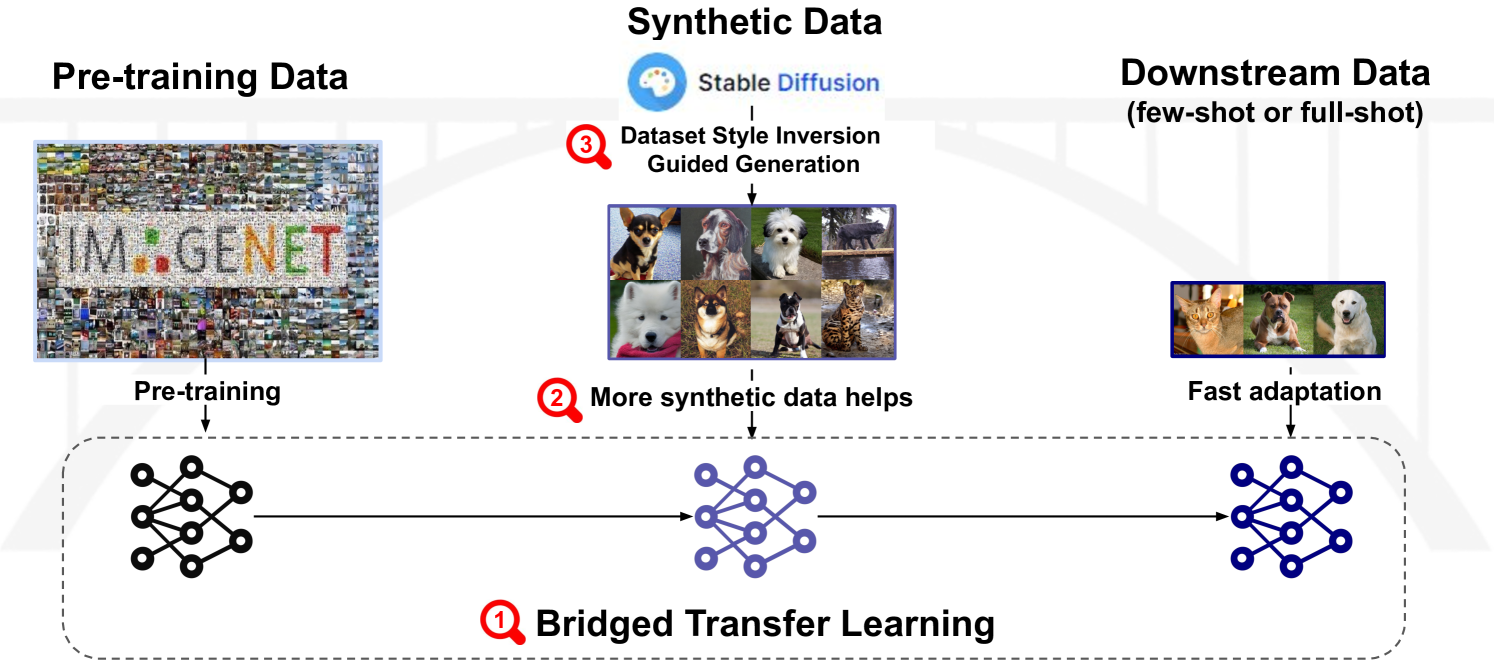
Synthetic image data generation represents a promising avenue for training deep learning models, particularly in the realm of transfer learning, where obtaining real images within a specific domain can be prohibitively expensive due to privacy and intellectual property considerations. This work delves into the generation and utilization of synthetic images derived from text-to-image generative models in facilitating transfer learning paradigms. Despite the high visual fidelity of the generated images, we observe that their naive incorporation into existing real-image datasets does not consistently enhance model performance due to the inherent distribution gap between synthetic and real images. To address this issue, we introduce a novel two-stage framework called bridged transfer, which initially employs synthetic images for fine-tuning a pre-trained model to improve its transferability and subsequently uses real data for rapid adaptation. Alongside, We propose dataset style inversion strategy to improve the stylistic alignment between synthetic and real images. Our proposed methods are evaluated across 10 different datasets and 5 distinct models, demonstrating consistent improvements, with up to 30% accuracy increase on classification tasks. Intriguingly, we note that the enhancements were not yet saturated, indicating that the benefits may further increase with an expanded volume of synthetic data.
4/4/2024

Towards Sim-to-Real Industrial Parts Classification with Synthetic Dataset
Xiaomeng Zhu, Talha Bilal, Par M{aa}rtensson, Lars Hanson, M{aa}rten Bjorkman, Atsuto Maki
0
0
This paper is about effectively utilizing synthetic data for training deep neural networks for industrial parts classification, in particular, by taking into account the domain gap against real-world images. To this end, we introduce a synthetic dataset that may serve as a preliminary testbed for the Sim-to-Real challenge; it contains 17 objects of six industrial use cases, including isolated and assembled parts. A few subsets of objects exhibit large similarities in shape and albedo for reflecting challenging cases of industrial parts. All the sample images come with and without random backgrounds and post-processing for evaluating the importance of domain randomization. We call it Synthetic Industrial Parts dataset (SIP-17). We study the usefulness of SIP-17 through benchmarking the performance of five state-of-the-art deep network models, supervised and self-supervised, trained only on the synthetic data while testing them on real data. By analyzing the results, we deduce some insights on the feasibility and challenges of using synthetic data for industrial parts classification and for further developing larger-scale synthetic datasets. Our dataset and code are publicly available.
4/16/2024